Python Coding With AI
Learn how to use Python to build real-world practical apps with large language models. On this page you will find tutorials that show how to call LLM APIs, design prompts, stream responses, and add AI features to real projects. Use this hub to stay current and ship production code with confidence.
Join Now: Click here to join the Real Python Newsletter and you’ll never miss another Python tutorial, course, or news update.
Explore topics like RAG, embeddings, vector databases, function calling, structured outputs, agents, and evaluation. Include emerging AI workflows and tooling into your day-to-day Python development. Build services with FastAPI, manage tokens and cost, log prompts, and set guardrails for privacy and safety. Examples focus on real workflows such as chat, code review, data extraction, and automation across OpenAI compatible and other providers.
You can browse all resources below, or take the guided route with a structured Learning Path that selects the most relevant content and tracks your progress:

Learning Path
Python Coding With AI
5 Resources ⋅ Skills: Claude Code, Cursor, Gemini CLI, AI-Assisted Development
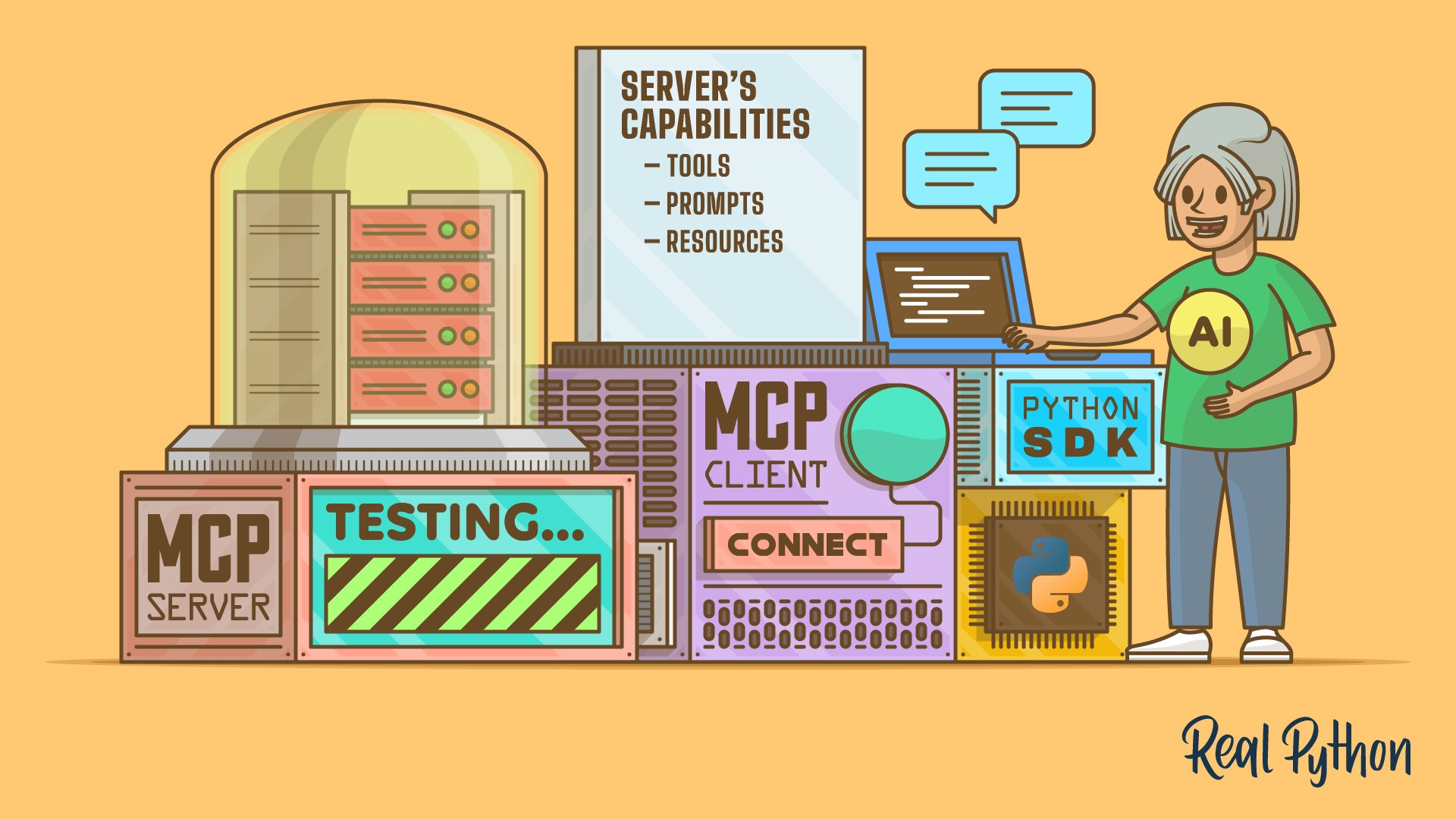
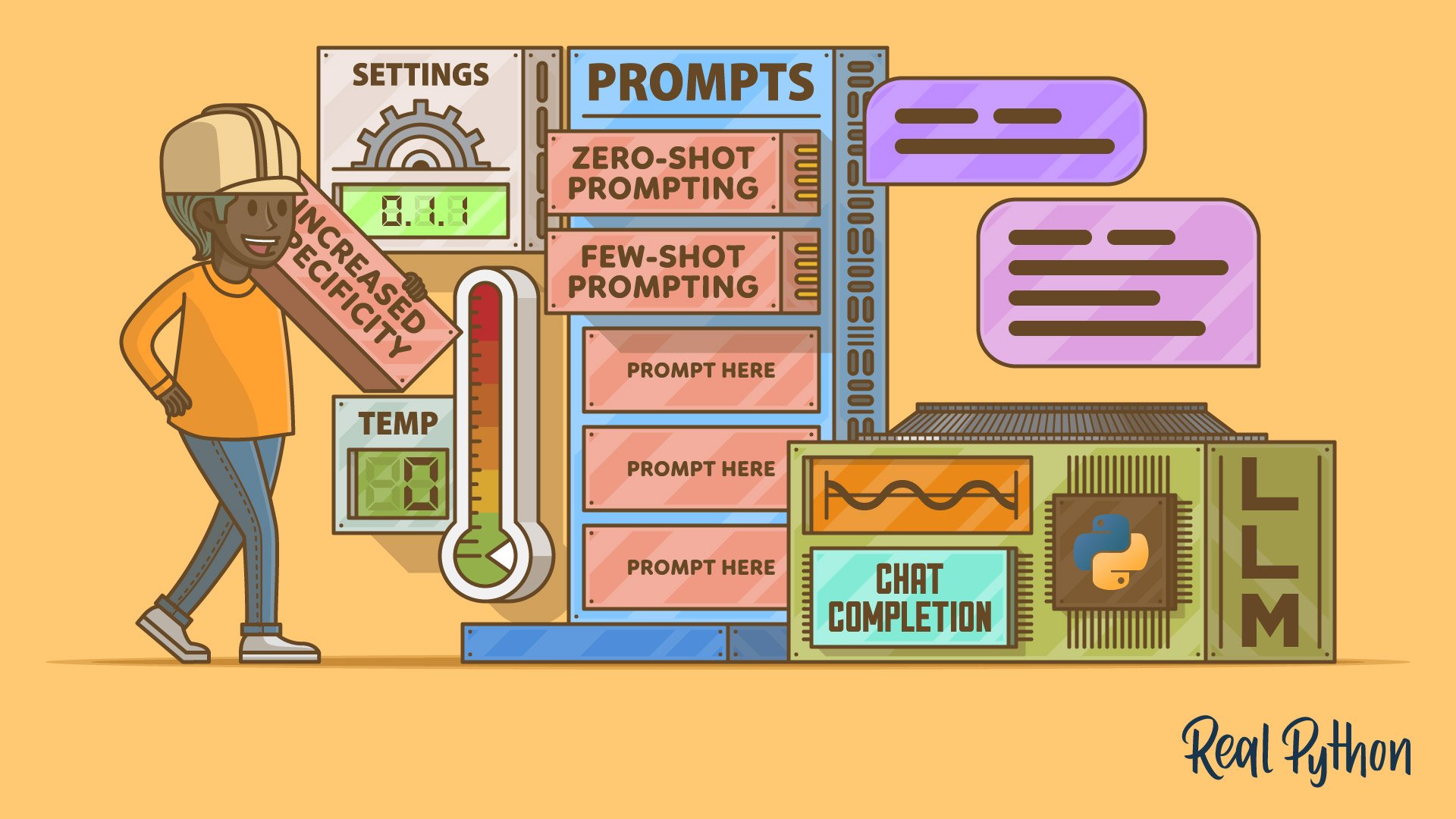
Use a provider SDK or standard HTTP with requests. Create a client, pass your prompt and optional system message, then parse the model output into your app. Start with a smaller model for speed, add retries and timeouts, and log prompts and responses for later evaluation.
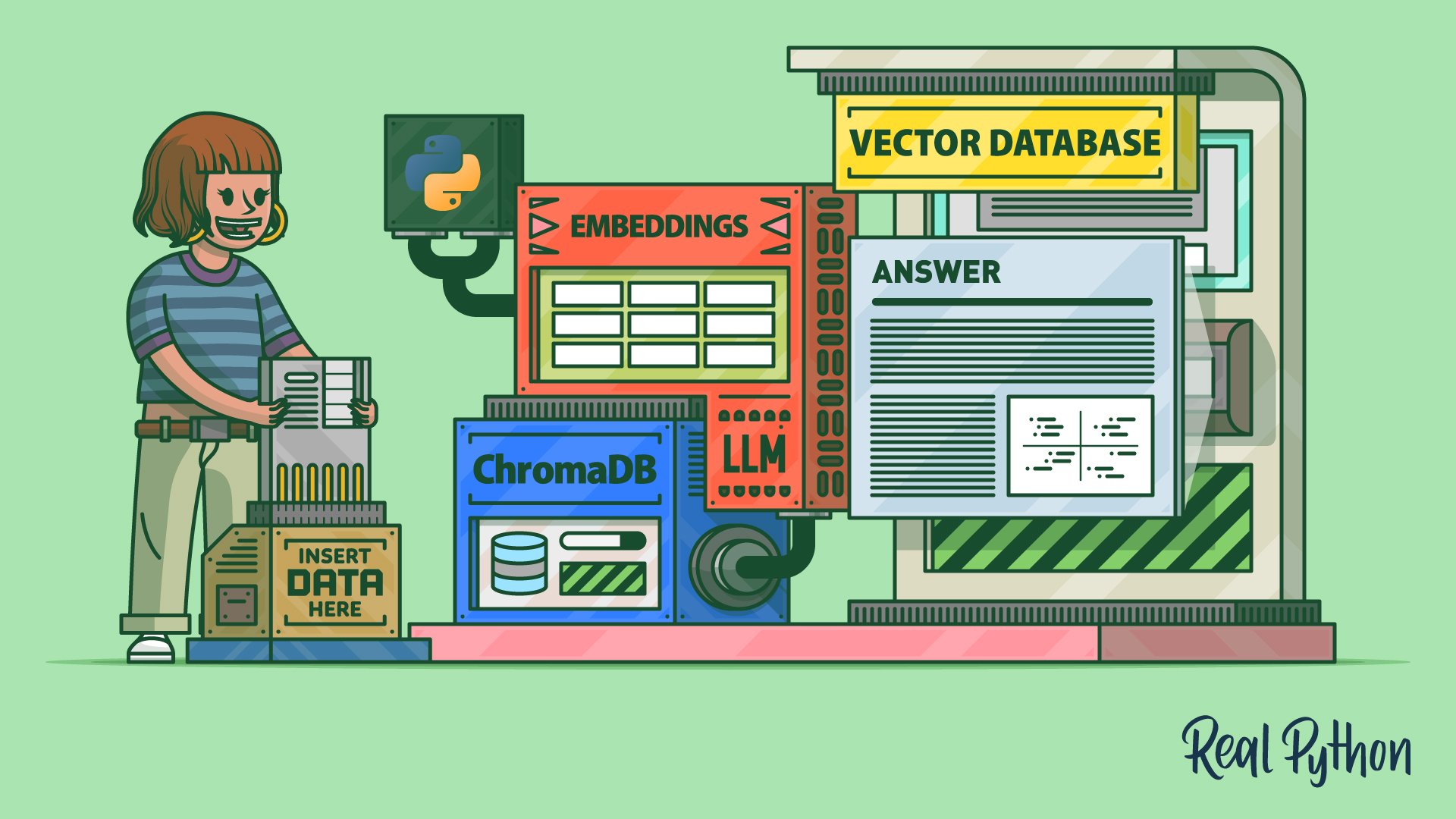
RAG means Retrieval Augmented Generation. You chunk documents, create embeddings, store vectors, run a search for each user query, and pass the top matches to the model as context. In Python you can use libraries for embeddings and a vector store such as ChromaDB or pgvector, then format a prompt that includes the retrieved text.
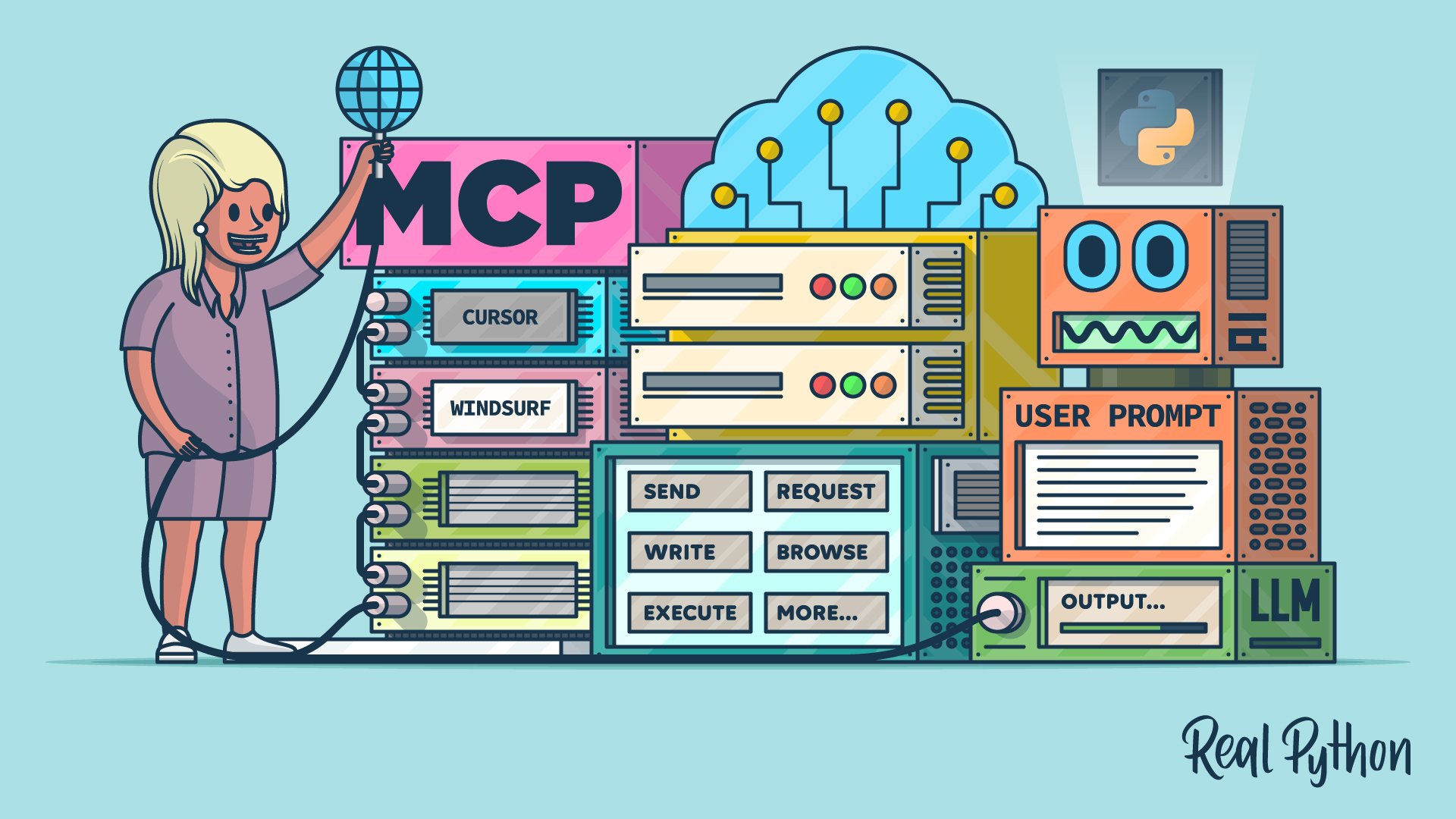
Expose a POST /chat endpoint that accepts the chat history, call the LLM with system and user messages, and stream tokens back to the client. Add rate limits, request validation with Pydantic, and optional tools or function calling for actions like search or database lookups.
Create a small golden dataset of inputs and expected outputs that reflect your use case. Run offline checks for accuracy, format, and safety, and track latency and cost. Write unit tests for deterministic parts and regression tests that compare current outputs to approved samples.
Use the smallest model that meets quality needs, shorten prompts and context, cache frequent answers, and stream partial results. Batch embedding jobs, limit tool calls, and truncate long histories. Monitor token usage per request and set budget alerts.