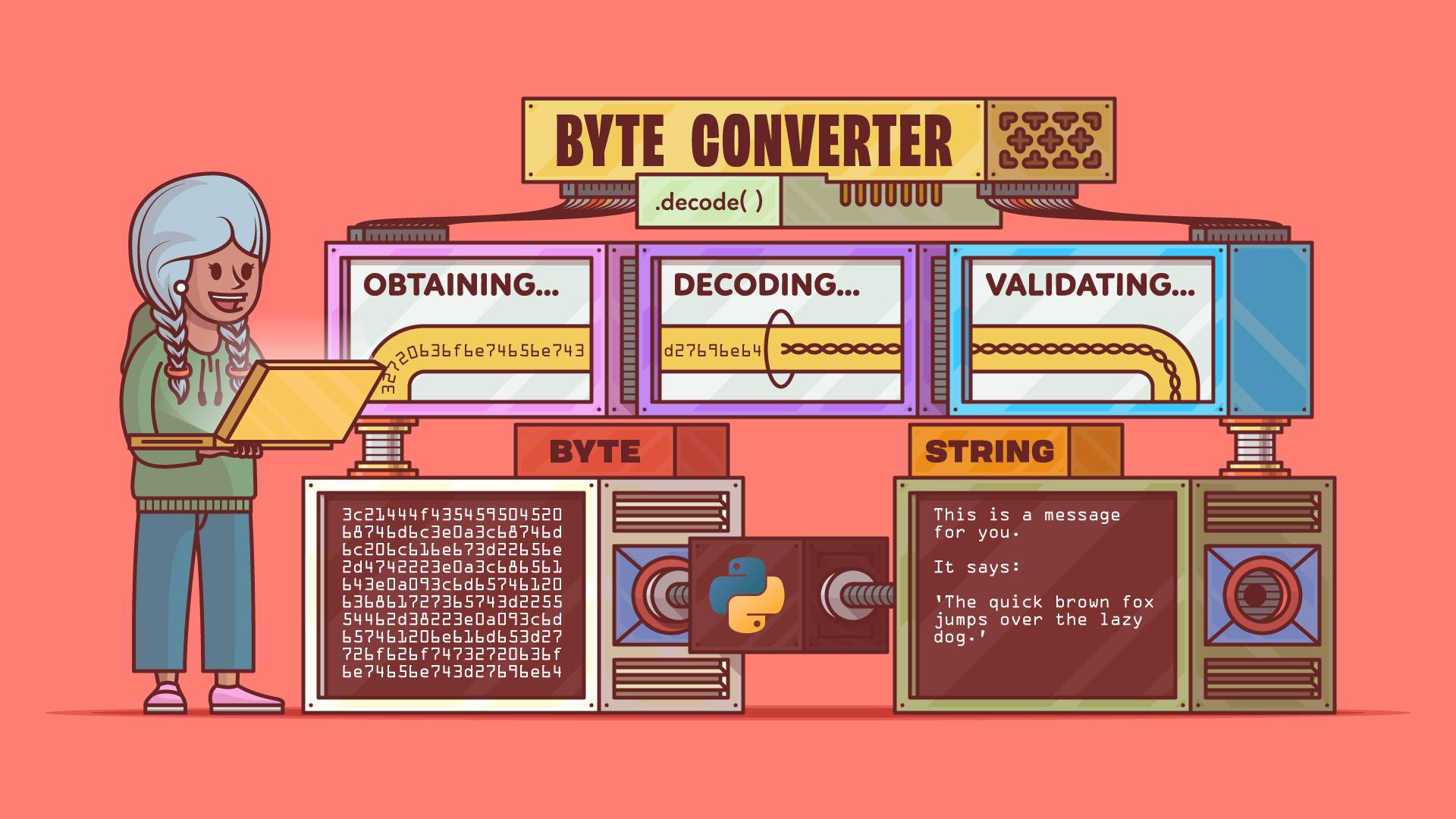
Converting bytes into readable strings in Python is an effective way to work with raw bytes fetched from files, databases, or APIs. You can do this in just three steps using the bytes.decode() method. This guide lets you convert byte data into clean text, giving you a result similar to what’s shown in the following example:
>>> binary_data = bytes([100, 195, 169, 106, 195, 160, 32, 118, 117])
>>> binary_data.decode(encoding="utf-8")
'déjà vu'
By interpreting the bytes according to a specific character encoding, Python transforms numeric byte values into their corresponding characters. This allows you to seamlessly handle data loaded from files, network responses, or other binary sources and work with it as normal text.
A byte is a fundamental unit of digital storage and processing. Composed of eight bits (binary digits), it’s a basic building block of data in computing. Bytes represent a vast range of data types and are used extensively in data storage and in networking. It’s important to be able to manage and handle bytes where they come up. Sometimes they need to be converted into strings for further use or comprehensibility.
By the end of this guide, you’ll be able to convert Python bytes to strings so that you can work with byte data in a human-readable format.
Get Your Code: Click here to download the free sample code that you’ll use to convert bytes to strings in Python.
Take the Quiz: Test your knowledge with our interactive “How to Convert Bytes to Strings in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
How to Convert Bytes to Strings in PythonDecode bytes into readable strings in Python. Test your skills working with data from files, APIs, and databases.
Step 1: Obtain the Byte Data
Before converting bytes to strings, you’ll need some actual bytes to work with. In everyday programming, you may not have to deal with bytes directly at all, as Python often handles their encoding and decoding behind the scenes.
Binary data exchanged over the internet can be expressed in different formats, such as raw binary streams, Base64, or hexadecimal strings. When you browse a web page, download a file, or chat with a colleague, the data that emerges travels as numeric bytes before it is interpreted as text that you can read.
In this step, however, you’ll obtain byte data using one of two approaches:
- Using the
bytesliteral (b"") - Using the
urllibpackage
You’ll soon find that using the urllib package requires that you go online. You can, however, create bytes manually without reaching out to the internet at all. You do this by prefixing a string with b, which creates a bytes literal containing the text inside:
raw_bytes = b"These are some interesting bytes"
You may be wondering why you have to create a bytes object at all from strings that you can read. This isn’t just a convenience. While bytes and strings share most of their methods, you can’t mix them freely. If you pass string arguments to a bytes method, then you’ll get an error:
>>> raw_bytes = b"These are some interesting bytes"
>>> raw_bytes.replace("y", "o")
Traceback (most recent call last):
...
TypeError: a bytes-like object is required, not 'str'
A bytes object only accepts other bytes-like objects as arguments. If you try to use a string like "y" with a bytes method, then Python raises a TypeError. To work with raw binary data, you must explicitly use bytes, not strings.
Note that you can represent the same information using alternative numeral formats, including binary, decimal, or hexadecimal. For instance, in the following code snippet, you convert the same bytes object from the above code example into hexadecimal and decimal formats:
>>> raw_bytes.hex()
'54686573652061726520736f6d6520696e746572657374696e67206279746573'
>>> list(raw_bytes)
[84, 104, 101, 115, 101, 32, 97, 114, 101, 32, 115, 111, …]
This seemingly random mix of numbers is a good reminder that even though bytes created using the b prefix may look readable, they aren’t actually strings. In some cases, bytes may appear much less readable. Ignoring the differences between bytes and strings could cause a bunch of errors in your code that’ll lead you to some frustrating debugging sessions.
Note: Python restricts bytes literals to ASCII characters only, meaning that something like b"é" would result in a syntax error. If you need bytes outside the ASCII range, then write them using escape codes, such as b"\xc3\xa9", or create them by calling the bytes() constructor.
You can also create bytes using Python’s built-in urllib package. It’s part of Python’s standard library, so you won’t have to install it. It provides tools for working with URLs. One of its submodules, urllib.request, contains urlopen(), which allows you to open a URL and fetch its content. If you’ve never worked with this package before, you can check out Python’s urllib.request for HTTP Requests to learn more.
You can use any website of your choice for this guide. Here, https://example.com/ can be replaced with the site that you’ve chosen. When you use the urlopen() function, Python automatically returns the data as bytes, since data is transmitted in that raw format. The strings you see are simply a human-readable representation of these bytes.
Create a Python file named decode_bytes.py and add the following code:
decode_bytes.py
from urllib.request import urlopen
url = "https://example.com/"
with urlopen(url) as response:
raw_bytes: bytes = response.read()
print("Bytes:", raw_bytes[:100])
In the code snippet above, you import urlopen() from urllib.request and assign a URL from which data will be fetched. You use the with statement to ensure that once the data is read, the connection to the website is closed automatically.
The .read() method extracts the contents of the web page and returns it as a bytes object, which you assign to raw_bytes. The call to print() displays the first 100 bytes of the web page. When you run the code in your terminal, you’ll get a result similar to the one below:
$ python decode_bytes.py
Bytes: b'<!doctype html><html lang="en"><head><title>Example Domain</title>
⮑ <meta name="viewport" content="wid'
Even though the output looks somewhat readable and you can see a familiar HTML structure, notice the b prefix before the quotes. This is used to identify a bytes object, so it reminds you that what you’re seeing is still raw byte data.
The next logical step is to decode these bytes into a string so you can process them further or at least read them. Whatever method you choose, you now have raw byte data ready to be decoded into a human-readable string. You’ll learn how to do just that next.
Step 2: Decode the Bytes to a String Using Python’s .decode() Method
Once you’ve obtained a bytes object, the next task is to decode it. This process involves converting raw bytes from step one into a readable string. In Python, the bytes.decode() method handles this task. It’s a built-in method that belongs to every bytes object and returns a string representation of the data.
In this practical example, you continue from the previous step by modifying decode_bytes.py:
decode_bytes.py
from urllib.request import urlopen
url = "https://example.com/"
with urlopen(url) as response:
raw_bytes: bytes = response.read()
print("Bytes:", raw_bytes[:100])
print("String:", raw_bytes[:100].decode())
The .decode() method takes two optional arguments:
| Argument | Default | Meaning |
|---|---|---|
encoding |
"utf-8" |
The encoding with which to decode the bytes |
errors |
"strict" |
The handling scheme to use for decoding errors |
Encodings help in mapping byte sequences to readable characters. Each encoding has a set of rules to determine how bytes represent letters, symbols, and other characters. Think of it like a specialized dictionary similar to a translation site or tool, except it translates the weird bytes of computers into a language humans can understand and use.
In the example above, .decode() uses UTF-8 encoding automatically since no encoding was specified. When the code runs, it converts the raw bytes fetched from the website into a readable HTML string, which can then be displayed or parsed further. The b prefix seen in the earlier byte representation disappears, and the result becomes a standard string:
$ python decode_bytes.py
Bytes: b'<!doctype html><html lang="en"><head><title>Example Domain</title>…
String: <!doctype html><html lang="en"><head><title>Example Domain</title>…
If you’d rather decode bytes using another encoding, you can do so by passing it explicitly, such as raw_bytes.decode("latin-1") or raw_bytes.decode("utf-16"). You’ll really need this when you’re working with data whose source uses a specific format. The collapsible below briefly dives into an explanation of some encodings.
Encodings are like specialized dictionaries. There are different kinds available, such as UTF-8. If you choose UTF-8, it becomes the dictionary agreed upon between you and the computer. If you try decoding a bytes object with a different encoding from what was used to encode it, then you’ll end up with garbled data. It’s like using a French dictionary to translate Russian. You’re bound to meet some very confused Russians.
If no encoding is specified, Python defaults to UTF-8, which is the standard encoding for almost all modern systems and web data. Each encoding defines its own rules for translating bytes into text. UTF-8, for example, can represent virtually every character used by humans, from English letters to emojis. It does this using one to four bytes per symbol, so it’s known as a variable-length encoding.
Another well-known encoding is ASCII, which is short for the American Standard Code for Information Interchange. ASCII is one of the oldest and simplest encodings, representing letters, digits, and punctuation marks using numbers from 0 to 127. Because of its simplicity, it’s still widely recognized today, but it can represent plain English text only, not special characters, emojis, or scripts like Chinese or Arabic.
If you’re working with data that includes European accented characters or special punctuation marks, you might encounter Latin-1, also known as ISO-8859-1. This encoding expands upon ASCII by supporting 256 characters, enough to cover many Western European languages. It’s especially common in legacy systems and older web pages that haven’t transitioned to UTF-8.
There are a number of standard encodings out there that you can check out. You can use any of these encodings by specifying them in the .decode() method.
Once the bytes are successfully decoded, you now have a string object that is a human-friendly version of what the machine processed earlier. In the next step, you’ll learn how to confirm that this conversion works as expected. You’ll also find out how to handle situations where decoding may not go as planned.
Step 3: Validate Decoded String and Handle Potential Decoding Errors
When decoding bytes into strings, things don’t always go as smoothly as expected. Not every sequence of bytes can be neatly translated into readable text using the encoding that you choose. This is where it becomes crucial to validate your data and handle any potential errors. Lucky for you, Python’s .decode() method helps you handle these situations gracefully.
The .decode() method takes a second, optional argument called errors. This defines what Python should do if it encounters a byte that doesn’t fit in nicely with the rules of the encoding specified. It tells Python what to do when something goes wrong during the decoding process.
By default, the errors argument is set to "strict", which means Python will immediately let you know something is wrong if it encounters invalid byte data. This is actually a really safe way to handle exceptions, since it alerts you to real issues that might otherwise go unnoticed.
Suppose you have a few bytes that don’t actually represent valid UTF-8 data:
>>> b"d\xe9j\xe0 vu".decode("utf-8")
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe9 in position 1:
⮑ invalid continuation byte
Python raises a UnicodeDecodeError because the byte 0xe9 is only allowed as a multi-byte sequence continuation in UTF-8. Sometimes, however, you may want to permit a few malformed bytes to avoid your program crashing. That’s where the other options for the errors argument come in handy.
If you set errors to "ignore", then Python will simply skip over any invalid bytes and decode the rest:
>>> b"d\xe9j\xe0 vu".decode("utf-8", errors="ignore")
'dj vu'
This means that your program will run successfully, but hidden errors may occur and escape your notice. This may be useful when you’re processing large amounts of text where perfect accuracy isn’t particularly crucial.
The "replace" option takes a gentler approach. Instead of ignoring invalid bytes entirely, it substitutes them with a replacement character, typically the Unicode replacement symbol—a question mark in a diamond shape:
>>> b"d\xe9j\xe0 vu".decode("utf-8", errors="replace")
'd�j� vu'
This makes it easy to spot where decoding failed while keeping the text mostly intact.
The "backslashreplace" option takes a different approach. Instead of dropping or replacing the bytes, it displays them as escape sequences, making debugging easier:
>>> b"d\xe9j\xe0 vu".decode("utf-8", errors="backslashreplace")
'd\\xe9j\\xe0 vu'
Using this mode, invalid bytes are shown in a form like \\xe9 or \\xe0, showing you exactly which data caused the issue.
The right error-handling strategy depends on your use case. For clean, well-structured data (like an API response or a trusted file), "strict" is best because it catches real problems early. For messy, unpredictable data like old archives, "ignore" or "replace" can help you recover what’s usable without halting your program. For debugging or data inspection, "backslashreplace" is perfect, since it preserves all bytes in a visible form.
Each encoding defines strict rules for how bytes should form characters, and if a sequence doesn’t fit, then you’re alerted to an error. The optional errors argument of the .decode() method allows for flexibility. It lets you decide whether to be strict with the rules, bend them a bit, or simply ignore them.
Conclusion
By this stage, you’ve successfully generated raw bytes, decoded them into readable strings, and handled the tricky edge cases that could appear in real-world data. Understanding these steps means you can confidently convert bytes to strings in Python, whether you’re dealing with web content, file I/O, or encoded messages. Furthermore, you can better handle any potential errors that arise as you converse with your computer.
Get Your Code: Click here to download the free sample code that you’ll use to convert bytes to strings in Python.
Frequently Asked Questions
Now that you have some experience with converting bytes to strings in Python, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
Call .decode() on the bytes object. It returns a str, using UTF-8 by default unless you pass a different character encoding.
Use UTF-8 for most modern text because it is the standard on the web and across platforms. If the data source declares a specific character set, pass that name to .decode().
Pass the errors argument to .decode() to control failures. The default is "strict", but you can also opt for "ignore", "replace", or "backslashreplace". Pick the mode that fits your data quality and debugging needs.
bytes holds raw 8-bit values, while str holds Unicode text. Convert from bytes to text with .decode() and from text to bytes with .encode().
Take the Quiz: Test your knowledge with our interactive “How to Convert Bytes to Strings in Python” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
How to Convert Bytes to Strings in PythonDecode bytes into readable strings in Python. Test your skills working with data from files, APIs, and databases.







