
NumPy and pandas are very comprehensive, efficient, and flexible Python tools for data manipulation. An important concept for proficient users of these two libraries to understand is how data are referenced as shallow copies (views) and deep copies (or just copies). pandas sometimes issues a SettingWithCopyWarning to warn the user of a potentially inappropriate use of views and copies.
In this article, you’ll learn:
- What views and copies are in NumPy and pandas
- How to properly work with views and copies in NumPy and pandas
- Why the
SettingWithCopyWarninghappens in pandas - How to avoid getting a
SettingWithCopyWarningin pandas
You’ll first see a short explanation of what the SettingWithCopyWarning is and how to avoid it. You might find this enough for your needs, but you can also dig a bit deeper into the details of NumPy and pandas to learn more about copies and views.
Free Bonus: Click here to get access to a free NumPy Resources Guide that points you to the best tutorials, videos, and books for improving your NumPy skills.
Prerequisites
To follow the examples in this article, you’ll need Python 3.7 or 3.8, as well as the libraries NumPy and pandas. This article is written for NumPy version 1.18.1 and pandas version 1.0.3. You can install them with pip:
$ python -m pip install -U "numpy==1.18.*" "pandas==1.0.*"
If you prefer Anaconda or Miniconda distributions, you can use the conda package management system. To learn more about this approach, check out Setting Up Python for Machine Learning on Windows. For now, it’ll be enough to install NumPy and pandas in your environment:
$ conda install numpy=1.18.* pandas=1.0.*
Now that you have NumPy and pandas installed, you can import them and check their versions:
>>> import numpy as np
>>> import pandas as pd
>>> np.__version__
'1.18.1'
>>> pd.__version__
'1.0.3'
That’s it. You have all the prerequisites for this article. Your versions might vary slightly, but the information below will still apply.
Note: This article requires you to have some prior pandas knowledge. You’ll also need some knowledge of NumPy for the later sections.
To refresh your NumPy skills, you can check out the following resources:
- NumPy Quickstart Tutorial
- Look Ma, No
forLoops: Array Programming With NumPy - Python Plotting With Matplotlib
To remind yourself about pandas, you can read the following:
Now you’re ready to start learning about views, copies, and the SettingWithCopyWarning!
Example of a SettingWithCopyWarning
If you work with pandas, chances are that you’ve already seen a SettingWithCopyWarning in action. It can be annoying and sometimes hard to understand. However, it’s issued for a reason.
The first thing you should know about the SettingWithCopyWarning is that it’s not an error. It’s a warning. It warns you that you’ve probably done something that’s going to result in unwanted behavior in your code.
Let’s see an example. You’ll start by creating a pandas DataFrame:
>>> data = {"x": 2**np.arange(5),
... "y": 3**np.arange(5),
... "z": np.array([45, 98, 24, 11, 64])}
>>> index = ["a", "b", "c", "d", "e"]
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
This example creates a dictionary referenced by the variable data that contains:
- The keys
"x","y", and"z", which will be the column labels of the DataFrame - Three NumPy arrays that hold the data of the DataFrame
You create the first two arrays with the routine numpy.arange() and the last one with numpy.array(). To learn more about arange(), check out NumPy arange(): How to Use np.arange().
The list attached to the variable index contains the strings "a", "b", "c", "d", and "e", which will be the row labels for the DataFrame.
Finally, you initialize the DataFrame df that contains the information from data and index. You can visualize it like this:
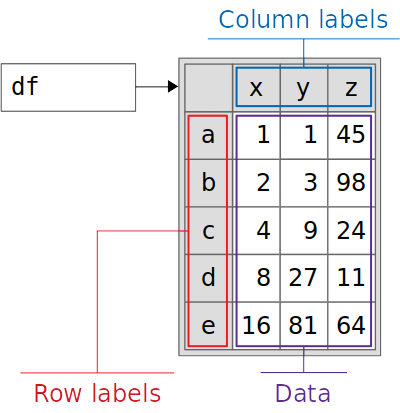
Here’s a breakdown of the main information contained in the DataFrame:
- Purple box: Data
- Blue box: Column labels
- Red box: Row labels
The DataFrame stores additional information, or metadata, including its shape, data types, and so on.
Now that you have a DataFrame to work with, let’s try to get a SettingWithCopyWarning. You’ll take all values from column z that are less than fifty and replace them with zeros. You can start by creating a mask, or a filter with pandas Boolean operators:
>>> mask = df["z"] < 50
>>> mask
a True
b False
c True
d True
e False
Name: z, dtype: bool
>>> df[mask]
x y z
a 1 1 45
c 4 9 24
d 8 27 11
mask is an instance of a pandas Series with Boolean data and the indices from df:
Trueindicates the rows indfin which the value ofzis less than50.Falseindicates the rows indfin which the value ofzis not less than50.
df[mask] returns a DataFrame with the rows from df for which mask is True. In this case, you get rows a, c, and d.
If you try to change df by extracting rows a, c, and d using mask, you’ll get a SettingWithCopyWarning, and df will remain the same:
>>> df[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
As you can see, the assignment of zeros to the column z fails. This image illustrates the entire process:
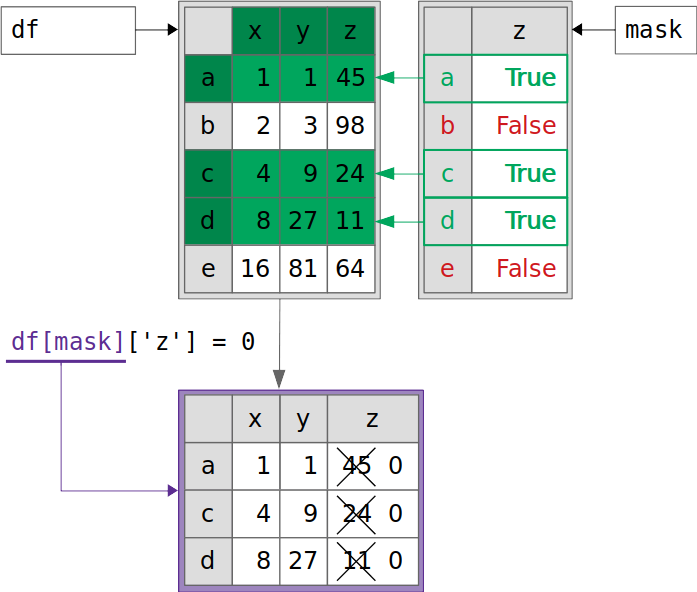
Here’s what happens in the code sample above:
df[mask]returns a completely new DataFrame (outlined in purple). This DataFrame holds a copy of the data fromdfthat correspond toTruevalues frommask(highlighted in green).df[mask]["z"] = 0modifies the columnzof the new DataFrame to zeros, leavingdfuntouched.
Usually, you don’t want this! You want to modify df and not some intermediate data structure that isn’t referenced by any variable. That’s why pandas issues a SettingWithCopyWarning and warns you about this possible mistake.
In this case, the proper way to modify df is to apply one of the accessors .loc[], .iloc[], .at[], or .iat[]:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
This approach enables you to provide two arguments, mask and "z", to the single method that assigns the values to the DataFrame.
An alternative way to fix this issue is to change the evaluation order:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["z"]
a 45
b 98
c 24
d 11
e 64
Name: z, dtype: int64
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
This works! You’ve modified df. Here’s what this process looks like:
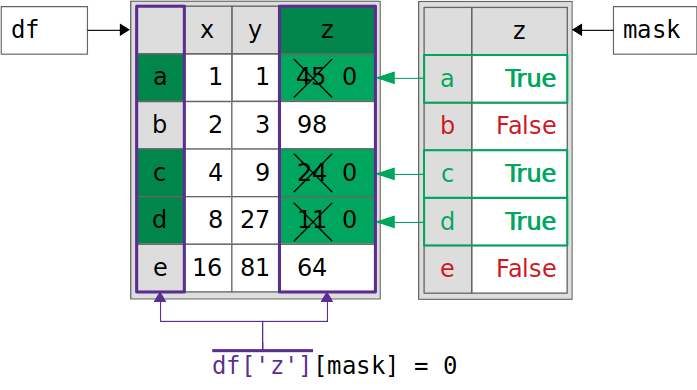
Here’s a breakdown of the image::
df["z"]returns aSeriesobject (outlined in purple) that points to the same data as the columnzindf, not its copy.df["z"][mask] = 0modifies thisSeriesobject by using chained assignment to set the masked values (highlighted in green) to zero.dfis modified as well since theSeriesobjectdf["z"]holds the same data asdf.
You’ve seen that df[mask] contains a copy of the data, whereas df["z"] points to the same data as df. The rules used by pandas to determine whether or not you make a copy are very complex. Fortunately, there are some straightforward ways to assign values to DataFrames and avoid a SettingWithCopyWarning.
Invoking accessors is usually considered better practice than chained assignment for these reasons:
- The intention to modify
dfis clearer to pandas when you use a single method. - The code is cleaner for readers.
- The accessors tend to have better performance, even though you won’t notice this in most cases.
However, using accessors sometimes isn’t enough. They might also return copies, in which case you can get a SettingWithCopyWarning:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
In this example, as in the previous one, you use the accessor .loc[]. The assignment fails because df.loc[mask] returns a new DataFrame with a copy of the data from df. Then df.loc[mask]["z"] = 0 modifies the new DataFrame, not df.
Generally, to avoid a SettingWithCopyWarning in pandas, you should do the following:
- Avoid chained assignments that combine two or more indexing operations like
df["z"][mask] = 0anddf.loc[mask]["z"] = 0. - Apply single assignments with just one indexing operation like
df.loc[mask, "z"] = 0. This might (or might not) involve the use of accessors, but they are certainly very useful and are often preferable.
With this knowledge, you can successfully avoid the SettingWithCopyWarning and any unwanted behavior in most cases. However, if you want to dive deeper into NumPy, pandas, views, copies, and the issues related to the SettingWithCopyWarning, then continue on with the rest of the article.
Views and Copies in NumPy and pandas
Understanding views and copies is an important part of getting to know how NumPy and pandas manipulate data. It can also help you avoid errors and performance bottlenecks. Sometimes data is copied from one part of memory to another, but in other cases two or more objects can share the same data, saving both time and memory.
Understanding Views and Copies in NumPy
Let’s start by creating a NumPy array:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr
array([ 1, 2, 4, 8, 16, 32])
Now that you have arr, you can use it to create other arrays. Let’s first extract the second and fourth elements of arr (2 and 8) as a new array. There are several ways to do this:
>>> arr[1:4:2]
array([2, 8])
>>> arr[[1, 3]]
array([2, 8]))
Don’t worry if you’re not familiar with array indexing. You’ll learn more about these and other statements later. For now, it’s important to notice that both statements return array([2, 8]). However, they have different behavior under the surface:
>>> arr[1:4:2].base
array([ 1, 2, 4, 8, 16, 32])
>>> arr[1:4:2].flags.owndata
False
>>> arr[[1, 3]].base
>>> arr[[1, 3]].flags.owndata
True
This might seem odd at the first sight. The difference is in the fact that arr[1:4:2] returns a shallow copy, while arr[[1, 3]] returns a deep copy. Understanding this difference is essential not only for dealing with the SettingWithCopyWarning but also for manipulating big data with NumPy and pandas.
In the sections below, you’ll learn more about shallow and deep copies in NumPy and pandas.
Views in NumPy
A shallow copy or view is a NumPy array that doesn’t have its own data. It looks at, or “views,” the data contained in the original array. You can create a view of an array with .view():
>>> view_of_arr = arr.view()
>>> view_of_arr
array([ 1, 2, 4, 8, 16, 32])
>>> view_of_arr.base
array([ 1, 2, 4, 8, 16, 32])
>>> view_of_arr.base is arr
True
You’ve obtained the array view_of_arr, which is a view, or shallow copy, of the original array arr. The attribute .base of view_of_arr is arr itself. In other words, view_of_arr doesn’t own any data—it uses the data that belongs to arr. You can also verify this with the attribute .flags:
>>> view_of_arr.flags.owndata
False
As you can see, view_of_arr.flags.owndata is False. This means that view_of_arr doesn’t own data and uses its .base to get the data:
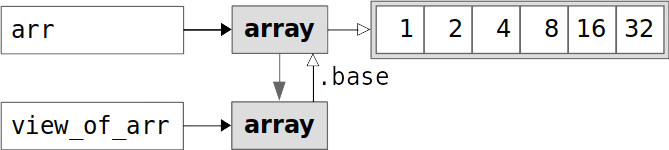
The image above shows that arr and view_of_arr point to the same data values.
Copies in NumPy
A deep copy of a NumPy array, sometimes called just a copy, is a separate NumPy array that has its own data. The data of a deep copy is obtained by copying the elements of the original array into the new array. The original and the copy are two separate instances. You can create a copy of an array with .copy():
>>> copy_of_arr = arr.copy()
>>> copy_of_arr
array([ 1, 2, 4, 8, 16, 32])
>>> copy_of_arr.base is None
True
>>> copy_of_arr.flags.owndata
True
As you can see, copy_of_arr doesn’t have .base. To be more precise, the value of copy_of_arr.base is None. The attribute .flags.owndata is True. This means that copy_of_arr owns data:
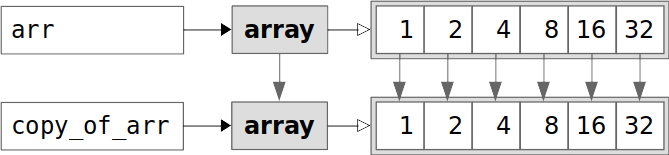
The image above shows that arr and copy_of_arr contain different instances of data values.
Differences Between Views and Copies
There are two very important differences between views and copies:
- Views don’t need additional storage for data, but copies do.
- Modifying the original array affects its views, and vice versa. However, modifying the original array will not affect its copy.
To illustrate the first difference between views and copies, let’s compare the sizes of arr, view_of_arr, and copy_of_arr. The attribute .nbytes returns the memory consumed by the elements of the array:
>>> arr.nbytes
48
>>> view_of_arr.nbytes
48
>>> copy_of_arr.nbytes
48
The amount of memory is the same for all arrays: 48 bytes. Each array looks at six integer elements of 8 bytes (64 bits) each. That’s 48 bytes in total.
However, if you use sys.getsizeof() to get the memory amount directly attributed to each array, then you’ll see the difference:
>>> from sys import getsizeof
>>> getsizeof(arr)
144
>>> getsizeof(view_of_arr)
96
>>> getsizeof(copy_of_arr)
144
arr and copy_of_arr hold 144 bytes each. As you’ve seen previously, 48 bytes out of the 144 total are for the data elements. The remaining 96 bytes are for other attributes. view_of_arr holds only those 96 bytes because it doesn’t have its own data elements.
To illustrate the second difference between views and copies, you can modify any element of the original array:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> view_of_arr
array([ 1, 64, 4, 8, 16, 32])
>>> copy_of_arr
array([ 1, 2, 4, 8, 16, 32])
As you can see, the view is also changed, but the copy stays the same. The code is illustrated in the image below:
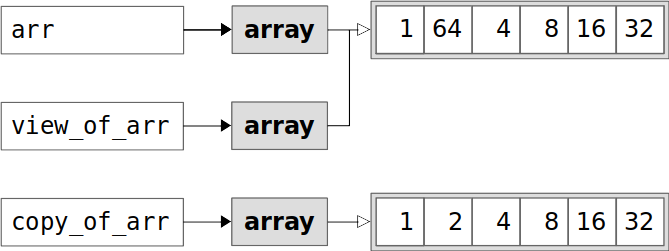
The view is modified because it looks at the elements of arr, and its .base is the original array. The copy is unchanged because it doesn’t share data with the original, so a change to the original doesn’t affect it at all.
Understanding Views and Copies in pandas
pandas also makes a distinction between views and copies. You can create a view or copy of a DataFrame with .copy(). The parameter deep determines if you want a view (deep=False) or copy (deep=True). deep is True by default, so you can omit it to get a copy:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> view_of_df = df.copy(deep=False)
>>> view_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> copy_of_df = df.copy()
>>> copy_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
At first, the view and copy of df look the same. If you compare their NumPy representations, though, then you may notice this subtle difference:
>>> view_of_df.to_numpy().base is df.to_numpy().base
True
>>> copy_of_df.to_numpy().base is df.to_numpy().base
False
Here, .to_numpy() returns the NumPy array that holds the data of the DataFrames. You can see that df and view_of_df have the same .base and share the same data. On the other hand, copy_of_df contains different data.
You can verify this by modifying df:
>>> df["z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 0
>>> view_of_df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 0
>>> copy_of_df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
You’ve assigned zeros to all elements of the column z in df. That causes a change in view_of_df, but copy_of_df remains unmodified.
Rows and column labels also exhibit the same behavior:
>>> view_of_df.index is df.index
True
>>> view_of_df.columns is df.columns
True
>>> copy_of_df.index is df.index
False
>>> copy_of_df.columns is df.columns
False
df and view_of_df share the same row and column labels, while copy_of_df has separate index instances. Keep in mind that you can’t modify particular elements of .index and .columns. They are immutable objects.
Indices and Slices in NumPy and pandas
Basic indexing and slicing in NumPy is similar to the indexing and slicing of lists and tuples. However, both NumPy and pandas provide additional options to reference and assign values to the objects and their parts.
NumPy arrays and pandas objects (DataFrame and Series) implement special methods that enable referencing, assigning, and deleting values in a style similar to that of containers:
.__getitem__()references values..__setitem__()assigns values..__delitem__()deletes values.
When you’re referencing, assigning, or deleting data in Python container-like objects, you often call these methods:
var = obj[key]is equivalent tovar = obj.__getitem__(key).obj[key] = valueis equivalent toobj.__setitem__(key, value).del obj[key]is equivalent toobj.__delitem__(key).
The argument key represents the index, which can be an integer, slice, tuple, list, NumPy array, and so on.
Indexing in NumPy: Copies and Views
NumPy has a strict set of rules related to copies and views when indexing arrays. Whether you get views or copies of the original data depends on the approach you use to index your arrays: slicing, integer indexing, or Boolean indexing.
One-Dimensional Arrays
Slicing is a well-known operation in Python for getting particular data from arrays, lists, or tuples. When you slice a NumPy array, you get a view of the array:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> a = arr[1:3]
>>> a
array([2, 4])
>>> a.base
array([ 1, 2, 4, 8, 16, 32])
>>> a.base is arr
True
>>> a.flags.owndata
False
>>> b = arr[1:4:2]
>>> b
array([2, 8])
>>> b.base
array([ 1, 2, 4, 8, 16, 32])
>>> b.base is arr
True
>>> b.flags.owndata
False
You’ve created the original array arr and sliced it to get two smaller arrays, a and b. Both a and b use arr as their bases and neither has its own data. Instead, they look at the data of arr:
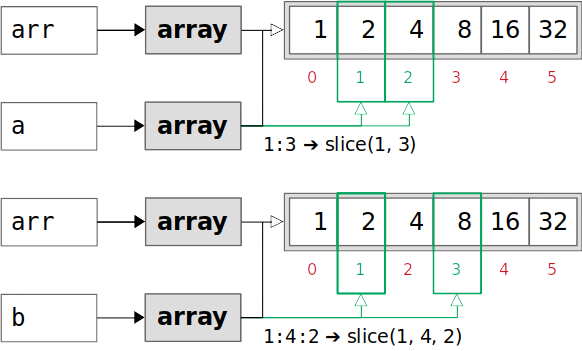
The green indices in the image above are taken by slicing. Both a and b look at the corresponding elements of arr in the green rectangles.
Note: When you have a large original array and need only a small part of it, you can call .copy() after slicing and delete the variable that points to the original with a del statement. This way, you keep the copy and remove the original array from memory.
Though slicing returns a view, there are other cases where creating one array from another actually makes a copy.
Indexing an array with a list of integers returns a copy of the original array. The copy contains the elements from the original array whose indices are present in the list:
>>> c = arr[[1, 3]]
>>> c
array([2, 8])
>>> c.base is None
True
>>> c.flags.owndata
True
The resulting array c contains the elements from arr with the indices 1 and 3. These elements have the values 2 and 8. In this case, c is a copy of arr, its .base is None, and it has its own data:
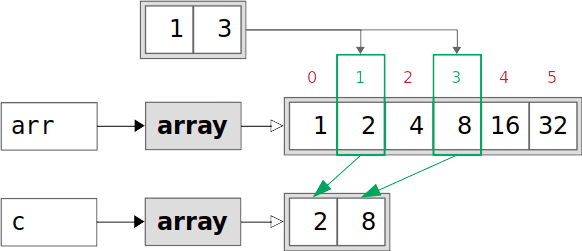
The elements of arr with the chosen indices 1 and 3 are copied into the new array c. After the copying is done, arr and c are independent.
You can also index NumPy arrays with mask arrays or lists. Masks are Boolean arrays or lists of the same shape as the original. You’ll get a copy of the original array that contains only the elements that correspond to the True values of the mask:
>>> mask = [False, True, False, True, False, False]
>>> d = arr[mask]
>>> d
array([2, 8])
>>> d.base is None
True
>>> d.flags.owndata
True
The list mask has True values at the second and fourth positions. This is why the array d contains only the elements from the second and fourth positions of arr. As in the case of c, d is a copy, its .base is None, and it has its own data:
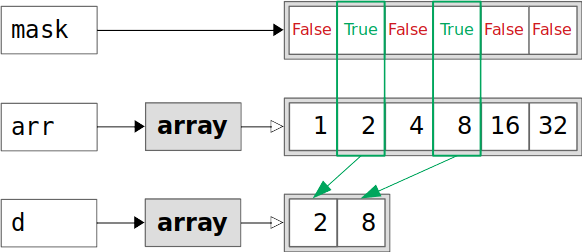
The elements of arr in the green rectangles correspond to True values from mask. These elements are copied into the new array d. After copying, arr and d are independent.
Note: Instead of a list, you can use another NumPy array of integers, but not a tuple.
To recap, here are the variables you’ve created so far that reference arr:
# `arr` is the original array:
arr = np.array([1, 2, 4, 8, 16, 32])
# `a` and `b` are views created through slicing:
a = arr[1:3]
b = arr[1:4:2]
# `c` and `d` are copies created through integer and Boolean indexing:
c = arr[[1, 3]]
d = arr[[False, True, False, True, False, False]]
Keep in mind that these examples show how you can reference data in an array. Referencing data returns views when slicing arrays and copies when using index and mask arrays. Assignments, on the other hand, always modify the original data of the array.
Now that you have all these arrays, let’s see what happens when you alter the original:
>>> arr[1] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> a
array([64, 4])
>>> b
array([64, 8])
>>> c
array([2, 8])
>>> d
array([2, 8])
You’ve changed the second value of arr from 2 to 64. The value 2 was also present in the derived arrays a, b, c, and d. However, only the views a and b are modified:
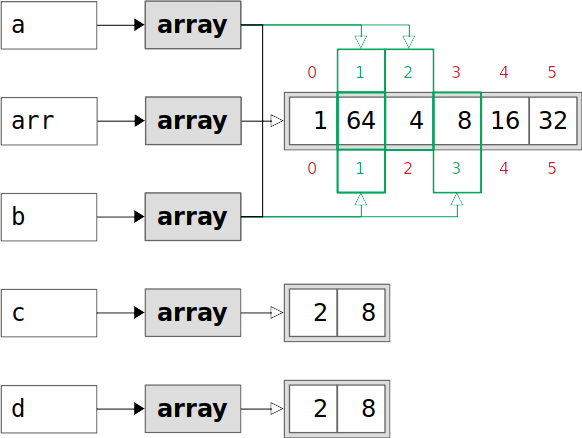
The views a and b look at the data of arr, including its second element. That’s why you see the change. The copies c and d remain unchanged because they don’t have common data with arr. They are independent of arr.
Chained Indexing in NumPy
Does this behavior with a and b look at all similar to the earlier pandas examples? It might, because the concept of chained indexing applies in NumPy, too:
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr[1:4:2][0] = 64
>>> arr
array([ 1, 64, 4, 8, 16, 32])
>>> arr = np.array([1, 2, 4, 8, 16, 32])
>>> arr[[1, 3]][0] = 64
>>> arr
array([ 1, 2, 4, 8, 16, 32])
This example illustrates the difference between copies and views when using chained indexing in NumPy.
In the first case, arr[1:4:2] returns a view that references the data of arr and contains the elements 2 and 8. The statement arr[1:4:2][0] = 64 modifies the first of these elements to 64. The change is visible in both arr and the view returned by arr[1:4:2].
In the second case, arr[[1, 3]] returns a copy that also contains the elements 2 and 8. But these aren’t the same elements as in arr. They’re new ones. arr[[1, 3]][0] = 64 modifies the copy returned by arr[[1, 3]] and leaves arr unchanged.
This is essentially the same behavior that produces a SettingWithCopyWarning in pandas, but that warning doesn’t exist in NumPy.
Multidimensional Arrays
Referencing multidimensional arrays follows the same principles:
- Slicing arrays returns views.
- Using index and mask arrays returns copies.
Combining index and mask arrays with slicing is also possible. In such cases, you get copies.
Here are a few examples:
>>> arr = np.array([[ 1, 2, 4, 8],
... [ 16, 32, 64, 128],
... [256, 512, 1024, 2048]])
>>> arr
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a = arr[:, 1:3] # Take columns 1 and 2
>>> a
array([[ 2, 4],
[ 32, 64],
[ 512, 1024]])
>>> a.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a.base is arr
True
>>> b = arr[:, 1:4:2] # Take columns 1 and 3
>>> b
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> b.base
array([[ 1, 2, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> b.base is arr
True
>>> c = arr[:, [1, 3]] # Take columns 1 and 3
>>> c
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> c.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> c.base is arr
False
>>> d = arr[:, [False, True, False, True]] # Take columns 1 and 3
>>> d
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> d.base
array([[ 2, 32, 512],
[ 8, 128, 2048]])
>>> d.base is arr
False
In this example, you start from the two-dimensional array arr. You apply slices for rows. Using the colon syntax (:), which is equivalent to slice(None), means that you want to take all rows.
When you work with the slices 1:3 and 1:4:2 for columns, the views a and b are returned. However, when you apply the list [1, 3] and mask [False, True, False, True], you get the copies c and d.
The .base of both a and b is arr itself. Both c and d have their own bases unrelated to arr.
As with one-dimensional arrays, when you modify the original, the views change because they see the same data, but the copies remain the same:
>>> arr[0, 1] = 100
>>> arr
array([[ 1, 100, 4, 8],
[ 16, 32, 64, 128],
[ 256, 512, 1024, 2048]])
>>> a
array([[ 100, 4],
[ 32, 64],
[ 512, 1024]])
>>> b
array([[ 100, 8],
[ 32, 128],
[ 512, 2048]])
>>> c
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
>>> d
array([[ 2, 8],
[ 32, 128],
[ 512, 2048]])
You changed the value 2 in arr to 100 and altered the corresponding elements from the views a and b. The copies c and d can’t be modified this way.
To learn more about indexing NumPy arrays, you can check out the official quickstart tutorial and indexing tutorial.
Indexing in pandas: Copies and Views
You’ve learned how you can use different indexing options in NumPy to refer to either actual data (a view, or shallow copy) or newly copied data (deep copy, or just copy). NumPy has a set of strict rules about this.
pandas heavily relies on NumPy arrays but offers additional functionality and flexibility. Because of that, the rules for returning views and copies are more complex and less straightforward. They depend on the layout of data, data types, and other details. In fact, pandas often doesn’t guarantee whether a view or copy will be referenced.
Note: Indexing in pandas is a very wide topic. It’s essential for using pandas data structures properly. You can use a variety of techniques:
- Dictionary-like notation
- Attribute-like (dot) notation
- The accessors
.loc[],.iloc[],.at[], and.iat
For more information, check out the official documentation and The pandas DataFrame: Make Working With Data Delightful.
In this section, you’ll see two examples of how pandas behaves similarly to NumPy. First, you can see that accessing the first three rows of df with a slice returns a view:
>>> df = pd.DataFrame(data=data, index=index)
>>> df["a":"c"]
x y z
a 1 1 45
b 2 3 98
c 4 9 24
>>> df["a":"c"].to_numpy().base
array([[ 1, 2, 4, 8, 16],
[ 1, 3, 9, 27, 81],
[45, 98, 24, 11, 64]])
>>> df["a":"c"].to_numpy().base is df.to_numpy().base
True
This view looks at the same data as df.
On the other hand, accessing the first two columns of df with a list of labels returns a copy:
>>> df = pd.DataFrame(data=data, index=index)
>>> df[["x", "y"]]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df[["x", "y"]].to_numpy().base
array([[ 1, 2, 4, 8, 16],
[ 1, 3, 9, 27, 81]])
>>> df[["x", "y"]].to_numpy().base is df.to_numpy().base
False
The copy has a different .base than df.
In the next section, you’ll find more details related to indexing DataFrames and returning views and copies. You’ll see some cases where the behavior of pandas becomes more complex and differs from NumPy.
Use of Views and Copies in pandas
As you’ve already learned, pandas can issue a SettingWithCopyWarning when you try to modify the copy of data instead of the original. This often follows chained indexing.
In this section, you’ll see some specific cases that produce a SettingWithCopyWarning. You’ll identify the causes and learn how to avoid them by properly using views, copies, and accessors.
Chained Indexing and SettingWithCopyWarning
You’ve already seen how the SettingWithCopyWarning works with chained indexing in the first example. Let’s elaborate on that a bit.
You’ve created the DataFrame and the mask Series object that corresponds to df["z"] < 50:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> mask = df["z"] < 50
>>> mask
a True
b False
c True
d True
e False
Name: z, dtype: bool
You already know that the assignment df[mask]["z"] = 0 fails. In this case, you get a SettingWithCopyWarning:
>>> df[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
The assignment fails because df[mask] returns a copy. To be more precise, the assignment is made on the copy, and df isn’t affected.
You’ve also seen that in pandas, evaluation order matters. In some cases, you can switch the order of operations to make the code work:
>>> df["z"][mask] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
df["z"][mask] = 0 succeeds and you get the modified df without a SettingWithCopyWarning.
Using the accessors is recommended, but you can run into trouble with them as well:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
In this case, df.loc[mask] returns a copy, the assignment fails, and pandas correctly issues the warning.
In some cases, pandas fails to detect the problem and the assignment on the copy passes without a SettingWithCopyWarning:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[["a", "c", "e"]]["z"] = 0 # Assignment fails, no warning
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
Here, you don’t receive a SettingWithCopyWarning and df isn’t changed because df.loc[["a", "c", "e"]] uses a list of indices and returns a copy, not a view.
There are some cases in which the code works, but pandas issues the warning anyway:
>>> df = pd.DataFrame(data=data, index=index)
>>> df[:3]["z"] = 0 # Assignment succeeds, with warning
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 11
e 16 81 64
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc["a":"c"]["z"] = 0 # Assignment succeeds, with warning
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 0
b 2 3 0
c 4 9 0
d 8 27 11
e 16 81 64
In these two cases, you select the first three rows with slices and get views. The assignments succeed both on the views and on df. But you still receive a SettingWithCopyWarning.
The recommended way of performing such operations is to avoid chained indexing. Accessors can be of great help with that:
>>> df = pd.DataFrame(data=data, index=index)
>>> df.loc[mask, "z"] = 0
>>> df
x y z
a 1 1 0
b 2 3 98
c 4 9 0
d 8 27 0
e 16 81 64
This approach uses one method call, without chained indexing, and both the code and your intentions are clearer. As a bonus, this is a slightly more efficient way to assign data.
Impact of Data Types on Views, Copies, and the SettingWithCopyWarning
In pandas, the difference between creating views and creating copies also depends on the data types used. When deciding if it’s going to return a view or copy, pandas handles DataFrames that have a single data type differently from ones with multiple types.
Let’s focus on the data types in this example:
>>> df = pd.DataFrame(data=data, index=index)
>>> df
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> df.dtypes
x int64
y int64
z int64
dtype: object
You’ve created the DataFrame with all integer columns. The fact that all three columns have the same data types is important here! In this case, you can select rows with a slice and get a view:
>>> df["b":"d"]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45
b 2 3 0
c 4 9 0
d 8 27 0
e 16 81 64
This mirrors the behavior that you’ve seen in the article so far. df["b":"d"] returns a view and allows you to modify the original data. That’s why the assignment df["b":"d"]["z"] = 0 succeeds. Notice that in this case you get a SettingWithCopyWarning regardless of the successful change to df.
If your DataFrame contains columns of different types, then you might get a copy instead of a view, in which case the same assignment will fail:
>>> df = pd.DataFrame(data=data, index=index).astype(dtype={"z": float})
>>> df
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
>>> df.dtypes
x int64
y int64
z float64
dtype: object
>>> df["b":"d"]["z"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
In this case, you used .astype() to create a DataFrame that has two integer columns and one floating-point column. Contrary to the previous example, df["b":"d"] now returns a copy, so the assignment df["b":"d"]["z"] = 0 fails and df remains unchanged.
When in doubt, avoid the confusion and use the .loc[], .iloc[], .at[], and .iat[] access methods throughout your code!
Hierarchical Indexing and SettingWithCopyWarning
Hierarchical indexing, or MultiIndex, is a pandas feature that enables you to organize your row or column indices on multiple levels according to a hierarchy. It’s a powerful feature that increases the flexibility of pandas and enables working with data in more than two dimensions.
Hierarchical indices are created using tuples as row or column labels:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
Now you have the DataFrame df with two-level column indices:
- The first level contains the labels
powersandrandom. - The second level has the labels
xandy, which belong topowers, andz, which belongs torandom.
The expression df["powers"] will return a DataFrame containing all columns below powers, which are the columns x and y. If you wanted to get just the column x, then you could pass both powers and x. The proper way to do this is with the expression df["powers", "x"]:
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers", "x"]
a 1
b 2
c 4
d 8
e 16
Name: (powers, x), dtype: int64
>>> df["powers", "x"] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
That’s one way to get and set columns in the case of multilevel column indices. You can also use accessors with multi-indexed DataFrames to get or modify the data:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df.loc[["a", "b"], "powers"]
x y
a 1 1
b 2 3
The example above uses .loc[] to return a DataFrame with the rows a and b and the columns x and y, which are below powers. You can get a particular column (or row) similarly:
>>> df.loc[["a", "b"], ("powers", "x")]
a 1
b 2
Name: (powers, x), dtype: int64
In this example, you specify that you want the intersection of the rows a and b with the column x, which is below powers. To get a single column, you pass the tuple of indices ("powers", "x") and get a Series object as the result.
You can use this approach to modify the elements of DataFrames with hierarchical indices:
>>> df.loc[["a", "b"], ("powers", "x")] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 4 9 24
d 8 27 11
e 16 81 64
In the examples above, you avoid chained indexing both with accessors (df.loc[["a", "b"], ("powers", "x")]) and without them (df["powers", "x"]).
As you saw earlier, chained indexing can lead to a SettingWithCopyWarning:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64])},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45
b 2 3 98
c 4 9 24
d 8 27 11
e 16 81 64
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers"]["x"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
Here, df["powers"] returns a DataFrame with the columns x and y. This is just a view that points to the data from df, so the assignment is successful and df is modified. But pandas still issues a SettingWithCopyWarning.
If you repeat the same code, but with different data types in the columns of df, then you’ll get a different behavior:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
>>> df["powers"]
x y
a 1 1
b 2 3
c 4 9
d 8 27
e 16 81
>>> df["powers"]["x"] = 0
__main__:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
>>> df
powers random
x y z
a 1 1 45.0
b 2 3 98.0
c 4 9 24.0
d 8 27 11.0
e 16 81 64.0
This time, df has more than one data type, so df["powers"] returns a copy, df["powers"]["x"] = 0 makes a change on this copy, and df remains unchanged, giving you a SettingWithCopyWarning.
The recommended way to modify df is to avoid chained assignment. You’ve learned that accessors can be very convenient, but they aren’t always needed:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df["powers", "x"] = 0
>>> df
powers random
x y z
a 0 1 45
b 0 3 98
c 0 9 24
d 0 27 11
e 0 81 64
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> df.loc[:, ("powers", "x")] = 0
>>> df
powers random
x y z
a 0 1 45.0
b 0 3 98.0
c 0 9 24.0
d 0 27 11.0
e 0 81 64.0
In both cases, you get the modified DataFrame df without a SettingWithCopyWarning.
Change the Default SettingWithCopyWarning Behavior
The SettingWithCopyWarning is a warning, not an error. Your code will still execute when it’s issued, even though it may not work as intended.
To change this behavior, you can modify the pandas mode.chained_assignment option with pandas.set_option(). You can use the following settings:
pd.set_option("mode.chained_assignment", "raise")raises aSettingWithCopyException.pd.set_option("mode.chained_assignment", "warn")issues aSettingWithCopyWarning. This is the default behavior.pd.set_option("mode.chained_assignment", None)suppresses both the warning and the error.
For example, this code will raise a SettingWithCopyException instead of issuing a SettingWithCopyWarning:
>>> df = pd.DataFrame(
... data={("powers", "x"): 2**np.arange(5),
... ("powers", "y"): 3**np.arange(5),
... ("random", "z"): np.array([45, 98, 24, 11, 64], dtype=float)},
... index=["a", "b", "c", "d", "e"]
... )
>>> pd.set_option("mode.chained_assignment", "raise")
>>> df["powers"]["x"] = 0
In addition to modifying the default behavior, you can use get_option() to retrieve the current setting related to mode.chained_assignment:
>>> pd.get_option("mode.chained_assignment")
'raise'
You get "raise" in this case because you changed the behavior with set_option(). Normally, pd.get_option("mode.chained_assignment") returns "warn".
Although you can suppress it, keep in mind that the SettingWithCopyWarning can be very useful in notifying you about improper code.
Conclusion
In this article, you learned what views and copies are in NumPy and pandas and what the differences are in their behavior. You also saw what a SettingWithCopyWarning is and how to avoid the subtle errors it points to.
In particular, you’ve learned the following:
- Indexing-based assignments in NumPy and pandas can return either views or copies.
- Both views and copies can be useful, but they have different behaviors.
- Special care must be taken to avoid setting unwanted values on copies.
- Accessors in pandas are very useful objects for properly assigning and referencing data.
Understanding views and copies is an important requirement for using NumPy and pandas properly, especially when you’re working with big data. Now that you have a solid grasp on these concepts, you’re ready to dive deeper into the exciting world of data science!
If you have questions or comments, then please put them in the comment section below.








