A Polars LazyFrame provides an efficient way to handle large datasets through lazy evaluation. Unlike traditional DataFrames, LazyFrames don’t contain data but instead store a set of instructions known as a query plan. Query plans perform operations like predicate and projection pushdown, ensuring only necessary rows and columns are processed. LazyFrames also support the parallel execution of query plans, further enhancing performance.
By the end of this tutorial, you’ll understand that:
- A Polars LazyFrame allows efficient data processing by storing query instructions instead of data.
- Lazy evaluation in LazyFrames optimizes query plans before data materialization.
- Predicate and projection pushdown minimize unnecessary data processing in LazyFrames.
- You create a LazyFrame using functions like
scan_parquet()orscan_csv(). - Switching between lazy and eager modes is sometimes necessary for certain operations.
Dive into this tutorial to discover how LazyFrames can transform your data processing tasks, providing both efficiency and flexibility for managing large datasets.
Before you start your learning journey, you should already be comfortable with the basics of working with DataFrames. This could be from any previous Polars experience you have, or from using any other DataFrame library, such as pandas.
In addition, you may consider using Jupyter Notebook as you work through many of the examples in this tutorial. Alternatively, JupyterLab will enhance your notebook experience, but any Python environment you’re comfortable with will be fine.
To get started, you’ll need some data. For the main part of this tutorial, you’ll use the rides.parquet file included in the downloadable materials. You can download this by clicking the link below:
Get Your Code: Click here to download the free sample code that shows you how work with Polars LazyFrames.
The rides.parquet file is a doctored version of the taxi ride data freely available on the New York City Taxi and Limousine Commission (TLC) website. The dataset contains edited information about New York taxi cab rides from July 2024. Before you go any further, you’ll need to download the file and place it in your project folder.
Note: The Parquet format is a format for storing large volumes of data efficiently. Parquet files use compression to minimize storage space. They also maintain metadata about each column allowing columns to be searched efficiently, often in parallel, and without the need to read the entire file. Because this metadata is useful to LazyFrames when they need to investigate a file’s content, Parquet is an excellent format for LazyFrames to use.
The table below shows details of the rides.parquet file’s columns, along with their Polars data types. The text in parentheses beside each data type shows how these types are annotated in a DataFrame header when Polars displays its results:
| Column Name | Polars Data Type | Description |
|---|---|---|
pick_up |
String (str) |
Pick-up borough |
drop_off |
String (str) |
Drop-off borough |
passengers |
Int32 (i32) |
Number of passengers |
distance |
Int32 (i32) |
Trip distance (miles) |
fare |
Int32 (i32) |
Total fare ($) |
As a starting point, you’ll create a LazyFrame and take a first look at its data. To use Polars, you first need to install the Polars library into your Python environment. You might also like to install Matplotlib as well. You’ll use this to view the inner workings of a LazyFrame graphically later on. To install both from a command prompt you use:
In a Jupyter Notebook, the command is !python -m pip install polars matplotlib.
You can then begin to use the Polars library and all of its cool features. Here’s what your data looks like, and here’s how to create your first LazyFrame:
>>> import polars as pl
>>> rides = pl.scan_parquet("rides.parquet")
>>> rides.collect()
shape: (3_076_903, 5)
┌───────────┬───────────┬────────────┬──────────┬──────┐
│ pick_up ┆ drop_off ┆ passengers ┆ distance ┆ fare │
│ --- ┆ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ str ┆ i32 ┆ i32 ┆ i32 │
╞═══════════╪═══════════╪════════════╪══════════╪══════╡
│ Manhattan ┆ Manhattan ┆ 1 ┆ 3 ┆ 24 │
│ Queens ┆ Manhattan ┆ 1 ┆ 19 ┆ 75 │
│ Manhattan ┆ Queens ┆ 1 ┆ 1 ┆ 16 │
│ Queens ┆ Manhattan ┆ 0 ┆ 9 ┆ 60 │
│ Queens ┆ Manhattan ┆ 1 ┆ 17 ┆ 90 │
│ … ┆ … ┆ … ┆ … ┆ … │
│ Manhattan ┆ Manhattan ┆ null ┆ 5 ┆ 27 │
│ Manhattan ┆ Manhattan ┆ null ┆ 4 ┆ 26 │
│ Queens ┆ Brooklyn ┆ null ┆ 4 ┆ 26 │
│ Manhattan ┆ Manhattan ┆ null ┆ 3 ┆ 24 │
│ Manhattan ┆ Manhattan ┆ null ┆ 8 ┆ 35 │
└───────────┴───────────┴────────────┴──────────┴──────┘
First of all, you import the Polars library using the conventional pl alias. You then use the scan_parquet() function to read rides.parquet. This makes your LazyFrame aware of the data file’s content. A LazyFrame doesn’t contain data but instead contains a set of instructions detailing what processing is to be carried out. To access the data, you need to materialize your LazyFrame by calling its .collect() method. This creates a DataFrame and reads the data.
In this example, .collect() shows there are 3,076,903 rows and five columns of data, as indicated by its shape.
Using LazyFrames may seem like a strange way of working given that you have to materialize them into DataFrames to view the data. You might wonder why not just stick with DataFrames instead. As you’ll see later, despite their name, LazyFrames offer an extremely efficient way to work with data. With their lazy evaluation capabilities, LazyFrames should be your preferred way to work with data in Polars whenever possible.
Next, you’ll learn the main ways you can create LazyFrames.
Take the Quiz: Test your knowledge with our interactive “How to Work With Polars LazyFrames” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
How to Work With Polars LazyFramesThis quiz will challenge your knowledge of working with Polars LazyFrames. You won't find all the answers in the tutorial, so you'll need to do some extra investigating. By finding all the answers, you're sure to learn some interesting things along the way.
How to Create a Polars LazyFrame
You can create LazyFrames in three main ways:
- From a data file using any of the available scan functions, such as
scan_parquet()orscan_csv(). - By passing a dictionary, a sequence such as a list, a NumPy array, or even a pandas DataFrame to the
LazyFrame()constructor. - By using the
.lazy()method to convert an existing Polars DataFrame to a LazyFrame.
The most common way to create a LazyFrame is by using one of the various scan functions to analyze your data file. You saw this in action earlier when you used scan_parquet() to create a LazyFrame based on the content of your rides.parquet file. You can also read other file formats lazily using functions such as scan_csv() and scan_ndjson().
Note: Using a scan function is just one way to work with data files. Polars also contains a larger collection of read functions such as read_parquet(), read_csv(), and read_excel(). However, these all read data into DataFrames, not LazyFrames.
While using DataFrames may seem like a backward step, you’ll see later that some analysis procedures can’t be carried out on LazyFrames, so DataFrames are still very much an important part of Polars.
A second way to create a LazyFrame is to pass the data you want to use to the LazyFrame() constructor. This is used for very small LazyFrames. The code below shows you how to create one from a dictionary:
>>> import polars as pl
>>> programming_languages = {
... "language_id": range(5),
... "language": ["Pascal", "C", "C++", "Python", "Java"],
... "creator": [
... "Niklaus Wirth",
... "Dennis Ritchie",
... "Bjarne Stroustrup",
... "Guido van Rossum",
... "James Gosling",
... ],
... "year": [1970, 1973, 1985, 1991, 1995],
... }
>>> pl.LazyFrame(programming_languages).collect()
shape: (5, 4)
┌─────────────┬──────────┬───────────────────┬──────┐
│ language_id ┆ language ┆ creator ┆ year │
│ --- ┆ --- ┆ --- ┆ --- │
│ i64 ┆ str ┆ str ┆ i64 │
╞═════════════╪══════════╪═══════════════════╪══════╡
│ 0 ┆ Pascal ┆ Niklaus Wirth ┆ 1970 │
│ 1 ┆ C ┆ Dennis Ritchie ┆ 1973 │
│ 2 ┆ C++ ┆ Bjarne Stroustrup ┆ 1985 │
│ 3 ┆ Python ┆ Guido van Rossum ┆ 1991 │
│ 4 ┆ Java ┆ James Gosling ┆ 1995 │
└─────────────┴──────────┴───────────────────┴──────┘
You define a programming_languages dictionary that contains the data you want. The keys of your dictionary are used to form the column headings of the LazyFrame, while the dictionary values, which in this case are a range() object and three lists, form its data. This information is then used by Polars to construct the LazyFrame. To see data produced by the LazyFrame, you materialize it by calling .collect(), which produces the output shown.
When reading a data file, Polars applies a suitable data type to each of its columns, but this might not always be the most efficient choice. As you can see from the resulting DataFrame, the language_id and year columns have been read as 64-bit integers (i64), which are larger than needed. This wastes space.
In addition, Polars uses data type coercion. This means it’ll adjust the size of data internally to the minimum size needed to ensure an operation succeeds. For example, 64-bit integers may be coerced into 32-bit integers provided, of course, the calculation still works. This allows internal data processing to run on minimal required memory, but the output might still not be what you want.
Fortunately, it’s possible to define the data types you wish Polars to use. To do this, you can pass them in as a dictionary to the schema parameter of the LazyFrame() constructor:
>>> import polars as pl
>>> programming_languages = {
... "language_id": range(5),
... "language": ["Pascal", "C", "C++", "Python", "Java"],
... "creator": [
... "Niklaus Wirth",
... "Dennis Ritchie",
... "Bjarne Stroustrup",
... "Guido van Rossum",
... "James Gosling",
... ],
... "year": [1970, 1973, 1985, 1991, 1995],
... }
>>> d_types = {
... "language_id": pl.Int32,
... "language": pl.String,
... "creator": pl.String,
... "year": pl.Int32,
... }
>>> pl.LazyFrame(programming_languages, schema=d_types).collect()
shape: (5, 4)
┌─────────────┬──────────┬───────────────────┬──────┐
│ language_id ┆ language ┆ creator ┆ year │
│ --- ┆ --- ┆ --- ┆ --- │
│ i32 ┆ str ┆ str ┆ i32 │
╞═════════════╪══════════╪═══════════════════╪══════╡
│ 0 ┆ Pascal ┆ Niklaus Wirth ┆ 1970 │
│ 1 ┆ C ┆ Dennis Ritchie ┆ 1973 │
│ 2 ┆ C++ ┆ Bjarne Stroustrup ┆ 1985 │
│ 3 ┆ Python ┆ Guido van Rossum ┆ 1991 │
│ 4 ┆ Java ┆ James Gosling ┆ 1995 │
└─────────────┴──────────┴───────────────────┴──────┘
This time, you create a d_types dictionary containing the data types you want. Its keys match the column headings defined in the programming_languages dictionary and the LazyFrame headings, while its values define the data types you desire. You then assign this second dictionary to the schema parameter of LazyFrame(). As with all LazyFrames, you must remember to materialize it to see its data, which you do with .collect().
As the highlighted line proves, both numeric columns are now 32-bit integers.
Note: If you want to see what data types your LazyFrame is using without performing a full materialization, you can use .collect_schema() instead:
>>> pl.LazyFrame(programming_languages, schema=d_types).collect_schema()
Schema({'language_id': Int32, 'language': String,
⮑ 'creator': String, 'year': Int32})
The .collect_schema() method shows that your LazyFrame is using the data types defined in your d_types dictionary.
If you want to write the analyzed results out to a file, then you can use one of several DataFrame methods such as .write_parquet() to do so. In the previous example, using lf.collect().write_parquet("analysis_results.parquet") would write your results into a parquet file. However, this only works if your DataFrame fits into your computer’s RAM and can be problematic otherwise. You’ll see how to avoid this later.
The third way to create a LazyFrame is to use the .lazy() method on a Polars DataFrame. You commonly use this to flip between eager mode, which uses DataFrames, and lazy mode. Some operations can’t work lazily because they need data to work with. However, you may want to apply further processing to a DataFrame that can make use of the LazyFrame efficiencies.
You’ll learn more about flipping between lazy and eager modes later, but for now, here’s how to use the .lazy() method on a DataFrame:
1>>> languages_df = pl.read_csv("programming_languages.csv")
2>>> type(languages_df)
3<class 'polars.dataframe.frame.DataFrame'>
4
5>>> languages_lf = languages_df.lazy()
6>>> type(languages_lf)
7<class 'polars.lazyframe.frame.LazyFrame'>
This time, you use the read_csv() function to read the data contained within programming_languages.csv into languages_df. To confirm that you’ve created a DataFrame, you use the built-in type() function. As you can see from line 3, everything is as expected.
In line 5, you use .lazy() to transform languages_df into the languages_lf LazyFrame. As before, type() confirms that a LazyFrame is now present.
Now that you know how to create a LazyFrame, next you’ll delve a little deeper and see why they’re such cool tools.
How to Monitor LazyFrame Efficiency
While traditional DataFrames contain data, LazyFrames contain a set of instructions, known as a query plan, that define the operations that should be carried out on the data. As you saw earlier, you need to materialize the LazyFrame into a DataFrame to see the data. So why bother with LazyFrames? Why not just stick to the tried and trusted DataFrames? Here’s why!
The query plan of a LazyFrame is optimized for efficient analysis of the data source before any data is analyzed. The LazyFrame reads and processes the data only when it’s materialized. So, although your LazyFrame contains multiple instructions, no data is read until materialization, eliminating data read delays during its construction.
LazyFrames are the recommended way of working whenever possible. Unfortunately, there are exceptions where lazy mode isn’t an option and you’ll look at these later on. For now, you can put these to one side and concentrate on the positives.
To compare the efficiency of LazyFrames versus DataFrames, you’ll time an identical analysis of some data using both a LazyFrame and a DataFrame. To make sure that both examples end at the same position, you’ll call .collect() on the LazyFrame to make sure it reads the data after optimization.
In this first test, you’ll work with a DataFrame created by running read_parquet() on the rides.parquet file. Create the following Python file and name it dataframe_timer.py:
dataframe_timer.py
1import time
2import polars as pl
3
4start = time.perf_counter()
5
6for _ in range(10):
7 rides = pl.read_parquet("rides.parquet")
8 (
9 rides
10 .filter(pl.col("pick_up") == pl.col("drop_off"))
11 .group_by(pl.col("pick_up"))
12 .agg(pl.col("fare").mean())
13 .filter(
14 pl.col("pick_up").is_in(
15 ["Brooklyn", "Bronx", "Queens", "Manhattan"]
16 )
17 )
18 )
19
20end = time.perf_counter()
21
22print(f"Code finished in {(end - start)/10:.4f} seconds.")
To time your Python code efficiently, you use perf_counter() from the built-in time module. This is a simple but accurate way of timing Python code. When you call time.perf_counter(), the function takes a reading from your computer’s clock. By doing this at the start and end of the test, you can work out how long the code is taking to run, and by averaging over ten iterations, you can improve the accuracy of the result.
The analysis you’re timing consists of the carrying out of several operations on the DataFrame. At line 7, you read the rides.parquet file into a DataFrame using the read_parquet() function.
In line 10, you use .filter() to include only rows where the trip started and ended within the same borough. To do this, you pass the expression pl.col("pick_up") == pl.col("drop_off") to .filter(), which ensures that the code returns only those rows with identical values in both their pick_up and drop_off columns.
Then, in lines 11 and 12, you group together the records by their pick_up field value. For each aggregate group of locations you’ve created, you work out the average cost of each journey. This will yield a single value for each of the different boroughs in the data.
You do this by passing the column you wish to group the data by to group_by(), and the column you want to perform the averaging calculation on to .agg(). You also use .mean() on the column passed to .agg(), to allow the average journey cost to be calculated for each pick_up location.
Finally, in lines 13 to 16, you apply a second filter. Again, you filter on pick-up location, but this time, because you only want to see records from some locations, you supply a list of the pick_up column locations you want to .is_in().
When you run your code, you’ll see how long it took:
$ python dataframe_timer.py
Code finished in 0.1178 seconds.
When your code runs, it reads all of the data from the file into memory ten separate times, and each time repeats the same processing. As each processing step completes, the data in the result DataFrame changes until it mutates into its final form. Polars carries each step out on the DataFrame in the order they’re specified in the code. This might not be the best order of execution.
A combination of having to read all of the data into memory, the constant updates, and their inefficient order wastes the computer’s resources. As a consequence of this, the time taken to run this test is relatively slow, as you’ll see in the next test.
Note: The timings produced here and elsewhere in this tutorial will be different to those you see on your computer. This is because of different system specifications and configurations. Still, you should see the same relative trends.
Next, you’ll repeat the previous test only this time, you’ll work with a LazyFrame. Create lazyframe_timer.py as follows:
lazyframe_timer.py
import time
import polars as pl
start = time.perf_counter()
for _ in range(10):
rides = pl.scan_parquet("rides.parquet")
(
rides
.filter(pl.col("pick_up") == pl.col("drop_off"))
.group_by(pl.col("pick_up"))
.agg(pl.col("fare").mean())
.filter(
pl.col("pick_up").is_in(
["Brooklyn", "Bronx", "Queens", "Manhattan"]
)
)
).collect()
end = time.perf_counter()
print(f"Code finished in {(end - start)/10:.4f} seconds.")
To create the LazyFrame, you pass rides.parquet to scan_parquet() as highlighted, instead of to read_parquet() as before. To make sure both versions of your code produce a DataFrame, you also call the .collect() method to materialize it. Apart from these two changes, the rest of the code is identical.
Again, you run your code to time your LazyFrame:
$ python lazyframe_timer.py
Code finished in 0.0919 seconds.
This time, when you run your code, each processing step doesn’t process the data directly. Instead, it simply adds instructions. Remember, LazyFrames are nothing more than a set of instructions defining what’s to be done to the data.
When you call .collect() to see the result, the query won’t necessarily be applied to the data in the same order written in your code. Instead, Polars will optimize the LazyFrame before running it so that when the instructions are applied, they process the data efficiently. This ability of Polars to optimize its queries produces the faster time than that obtained earlier in your DataFrame test. You’ll learn more about how this is done next.
How LazyFrames Achieve Efficiency
In this section, you’ll take a look at how query plans are optimized before they’re run. This is the secret to LazyFrame efficiency. There are two types of query plans: the optimized query plan and the sub-optimized query plan. The optimized query plan is used by LazyFrames to process data as efficiently as possible, while the sub-optimized query plan is used by DataFrames to apply the query steps in the order they are defined in the code.
Investigating the Sub-Optimized Query Plan
Before you can understand how query plans are optimized, you need to learn how to view and read one. You’ll start with the sub-optimized version:
To see a query plan, you use LazyFrame.explain() to display it:
1>>> import polars as pl
2
3>>> rides = pl.scan_parquet("rides.parquet")
4
5>>> print(
6... (
7... rides
8... .filter(pl.col("pick_up") == pl.col("drop_off"))
9... .group_by(pl.col("pick_up"))
10... .agg(pl.col("fare").mean())
11... .filter(
12... pl.col("pick_up").is_in(
13... ["Brooklyn", "Bronx", "Queens", "Manhattan"]
14... )
15... )
16... ).explain(optimized=False)
17... )
18FILTER col("pick_up").is_in([Series]) FROM
19 AGGREGATE
20 [col("fare").mean()] BY [col("pick_up")] FROM
21 FILTER [(col("pick_up")) == (col("drop_off"))] FROM
22 Parquet SCAN [rides.parquet]
23 PROJECT */5 COLUMNS
In line 16, you requested that the sub-optimized plan be displayed by passing optimized=False to .explain(). Also, for clarity, you used the built in print() function in line 5. Without this, the output is less readable.
As you can see, the textual representation uses indentation to display the main query operations. The query plan consists of four main operations: FILTER, AGGREGATE, FILTER, and SCAN. While this can certainly be read, it can be a bit overwhelming the first time you see it. A better way is to use the free Graphviz software to render your query plans. This makes each step in the plan easier to visualize.
If you want to display your query plans graphically, you must first install Graphviz. The specific procedure you follow will depend on your operating system:
Once you’ve installed Graphviz, you’ll also need to install Matplotlib if you didn’t earlier. You can install the package using python -m pip install matplotlib. When both are installed, you can then use Graphviz to view query plans graphically.
Now you’ll take a look at the same query plan, only this time a graphical version:
>>> import polars as pl
>>> rides = pl.scan_parquet("rides.parquet")
>>> (
... rides
... .filter(pl.col("pick_up") == pl.col("drop_off"))
... .group_by(pl.col("pick_up"))
... .agg(pl.col("fare").mean())
... .filter(pl.col("pick_up")
... .is_in(
... ["Brooklyn", "Bronx", "Queens", "Manhattan"]
... )
... )
... ).show_graph(optimized=False)
Although your code creates the same LazyFrame as before, this time you replace .explain(optimized=False) with .show_graph(optimized=False) to display the sub-optimized query plan using Graphviz. This graphical version is shown below:
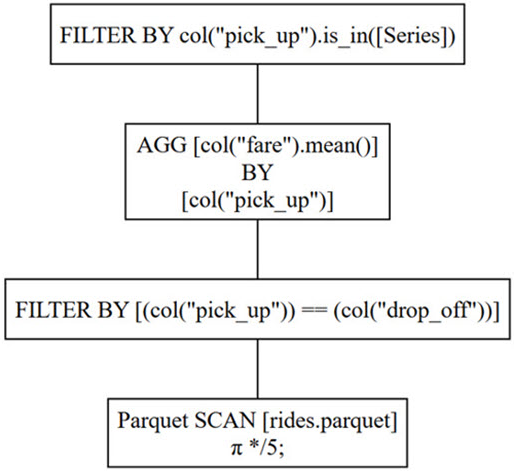
When you’re interpreting any query plan, it’s best to read it from the bottom up.
The bottom instruction means your code will first read all five columns from the rides.parquet file. The Greek letter pi (π) indicates a projection, which means that columns are to be read, while */5 specifies that your code will read all five columns.
Once the projection is complete, the next instruction up defines the first of the filter criteria your code will apply to the data. In this case, only those rows whose pick_up locations match their drop_off locations are considered.
When the correct rows have been determined, the grouping and aggregation comes next. As you learned earlier, your data is grouped by pick_up location before the mean fare is calculated.
Finally, you apply a second filter to include only those rows where the pick_up location values are within a series. Although the series is not specified in the plan, it refers to the four boroughs defined in the code.
It’s important to remember that since this query plan is the sub-optimal version, it’ll never be used by the LazyFrame. In this plan, the order of the steps mirror those of the code. This query plan is how the data would have been processed had you used .read_parquet() to create a DataFrame, instead of .scan_parquet() to create a LazyFrame.
Now that you’ve seen a graphical representation of a query plan, look back at the textual representation shown first and it’ll be easier to understand. As you can see, the textual representation uses indentation instead of boxes. However, each of the four indentations in the textual representation corresponds to one of the four individual boxes in the Graphviz diagram.
Now that you’ve been introduced to the idea of a query plan, next you’ll see how they’re actually used by LazyFrames.
Investigating the Optimized Query Plan
To understand what actually happens when you run LazyFrame code, you need to view the all-important, optimized query plan:
>>> rides = pl.scan_parquet("rides.parquet")
>>> (
... rides
... .filter(pl.col("pick_up") == pl.col("drop_off"))
... .group_by(pl.col("pick_up"))
... .agg(pl.col("fare").mean())
... .filter(pl.col("pick_up")
... .is_in(
... ["Brooklyn", "Bronx", "Queens", "Manhattan"]
... )
... )
... ).show_graph(optimized=True)
To view the optimized query plan, you pass optimized=True to either .show_graph(), or to .explain(). Despite this being only a small change, the effects are significant:
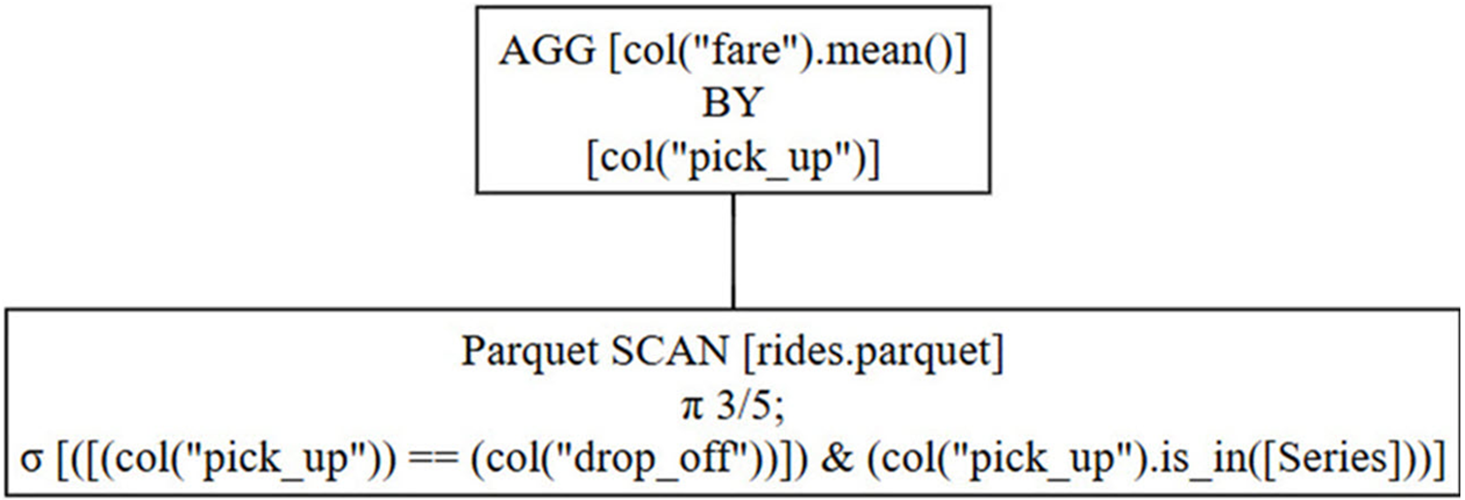
This time, Polars has merged both the original filters into a single selection instruction as annotated by the Greek letter sigma (σ). This means that right from the start of this optimized query, only those rows which are needed are actually read. When DataFrames are used, all rows are read. Moving the row selection to the start of the query is called predicate pushdown.
Notice that the projection instruction (π 3/5) means that Polars will read only three of the five columns, since these are all it needs. These are the pick_up, drop_off, and fare columns. Selecting only those columns necessary is called projection pushdown.
Once Polars has retrieved the data it needs, which will be quicker than reading all of it, it performs the same aggregation as before. However, with less data to process, the calculation runs faster, reducing the overall computational load.
In addition to both predicate and projection pushdown, the LazyFrame’s schema also plays a part in achieving efficiency. Polars consults the LazyFrame’s schema and uses it to verify the correctness of its optimized query plan before the query runs. In contrast, DataFrames read the data first and will only fail when they attempt to process it.
You can view the schema using .collect_schema():
>>> rides.collect_schema()
Schema(
⮑ {'pick_up': String,
⮑ 'pu_time': Datetime(time_unit='ns', time_zone=None),
⮑ 'drop_off': String,
⮑ 'do_time': Datetime(time_unit='ns', time_zone=None),
⮑ 'passengers': Int32,
⮑ 'distance': Int32, 'fare': Int32}
⮑)
For example, there’d be no point in Polars working out the mean pick_up field value since it has a data type of String. The query will fail quickly because the optimized query knows this up front from the schema. Conversely, when DataFrames are used, .mean() will still fail, but only after reading the entire dataset, potentially wasting time and resources.
LazyFrames also achieve efficiency by running their query plans in parallel. This allows multiple operations in a plan to be run simultaneously, their results cached, and then combined together to produce a further result.
For example, if a query requires data from multiple files, it’s likely that each of the files will be read in parallel, and then both datasets analyzed together. Of course the LazyFrame efficiencies will be applied before each file read begins.
While these are the main ways Polars can optimize data analysis when working in lazy mode, it has several other tricks up its sleeve. Altogether, this means that working with LazyFrames should be your first choice whenever possible.
So far, the code examples assume that all your data can fit within your computer’s memory for processing. Next, you’ll see how Polars can be made to cope when it doesn’t.
How LazyFrames Cope With Large Volumes of Data
LazyFrames use something called streaming to allow them to work with large volumes of data. Streaming allows LazyFrames to deal with data that would otherwise be too large to fit into RAM. In this section, you’ll learn how it works, when to use it, and when not to.
Using Streaming to Deal With Large Volumes
When streaming is enabled, Polars reads its data from the file in batches instead of all at once. Also, batches may be cached temporarily on disk, then swapped back into RAM when needed. Without streaming, storing large volumes of data in RAM will most certainly affect performance, and may even cause a system crash.
Streaming isn’t switched on by default, but must be activated within collect() by setting its streaming parameter to True.
In this section, you’ll run a script to generate a version of 2021_Yellow_Taxi_Trip_Data.csv that’s publicly available on the U.S. Data.gov site. However, even though their file is 3GB in size, it’s still too small for the code you’ll use in this section. Instead, you’ll run one of the taxi_rides.py scripts included in your downloads to produce your own version.
There are various versions of the taxi_rides.py script available to enable you to generate files with sizes between 16GB to 80GB. For example, taxi_rides_80GB.py will generate an 80GB file of taxi ride data for you to use. You should choose the taxi_rides.py file that generates more data than the RAM you’ve installed on your computer.
Before you go any further, please read the the following:
Note: The code in this section will generate and process a very large data file. If you decide to run it, please save any data you wish to keep first. There’s also a chance that your computer will freeze, or even crash. Again, save anything you need before you proceed, just to be safe.
Also, when working with these large files, avoid using a Jupyter notebook because notebooks are configured to use a small amount of the RAM on your system.
If you’d rather not run the code yourself, you can still read through it to gain a deeper understanding of how to activate streaming.
To begin with, open a command prompt on your system and run the appropriate script. For example, if you’ve 64GB of RAM in your computer, you’d run the taxi_rides_80GB.py script as shown:
$ python taxi_rides_80GB.py
When you run your chosen script, it’ll produce a 2021_Yellow_Taxi_Trip_Data.csv in the same directory the program was run. You’ll know the script completes when the command prompt becomes available to you again. A better approach might be to open another terminal and run the dir or ls -l command every so often:
This will let you see the size of the 2021_Yellow_Taxi_Trip_Data.csv as its grows, and allow you to estimate how long it’ll take to be created on your computer.
To investigate the configuration and effects of streaming, you’ll perform an analysis of the 2021_Yellow_Taxi_Trip_Data.csv data file with streaming enabled.
The code for doing this is shown below, but do remember to save everything and be prepared to wait:
>>> import polars as pl
>>> rides = pl.scan_csv("2021_Yellow_Taxi_Trip_Data.csv")
>>> print(
... (
... rides
... .group_by(pl.col("PULocationID"))
... .agg(pl.col("total_amount").sum())
... ).collect(streaming=True)
... )
shape: (265, 2)
┌──────────────┬──────────────┐
│ PULocationID ┆ total_amount │
│ --- ┆ --- │
│ i64 ┆ f64 │
╞══════════════╪══════════════╡
│ 197 ┆ 2.2632e8 │
│ 176 ┆ 2.2658e8 │
│ 212 ┆ 2.2638e8 │
│ 236 ┆ 2.2647e8 │
│ 209 ┆ 2.2639e8 │
│ … ┆ … │
│ 207 ┆ 2.2643e8 │
│ 187 ┆ 2.2648e8 │
│ 43 ┆ 2.2647e8 │
│ 82 ┆ 2.2633e8 │
│ 175 ┆ 2.2617e8 │
└──────────────┴──────────────┘
Your code calculates the total of the fares for each pick-up location for the entire content of 2021_Yellow_Taxi_Trip_Data.csv. Most importantly, to use streaming, you need to enable it by setting the streaming parameter to True when you materialize your LazyFrame.
You’ve managed to successfully use streaming to process a huge data file. Polars read the data in batches and used your hard disk to free up memory for both processing and storage of other reads. In addition, Polars only read in the columns it needed, again saving on RAM usage.
Note: Don’t re-run the previous code using read_csv(). This will read all of the data rows and columns in the file into a DataFrame, and will most certainly consume all of your computer’s memory and cause you problems.
Although streaming is certainly powerful, there are some limitations as you’ll see next.
Deciding When Streaming Should Be Used
At this point, you might be wondering if you should always enable streaming regardless of data size. The answer is no. In cases where data can comfortably fit into RAM, disabling streaming is the best option. Provided the RAM can easily cope with the volume of data being read, having it all in RAM is best. Conversely, if you enable streaming on a small dataset, Polars wastes time organizing data batching, which slows things down.
In general, a LazyFrame with no streaming is the best option when data can fit into RAM, while streaming should be used when data will exceed RAM. If you need to perform the same processing on multiple instances of similar data, it might be worthwhile timing your analysis with streaming both enabled and disabled to see which works best for your use case.
Be aware that displaying the materialized result of a LazyFrame query that has streaming enabled may still cause you memory problems if the result still greatly exceeds your available RAM. To avoid this, you can write the result out to disk using a LazyFrame method such as .sink_parquet() or .sink_csv(). Methods such as these write results directly to file and avoid overloading RAM by not displaying it first.
Depending on what you’re doing, you may still run into issues if your data are too large and you request streaming. You can’t assume just because you passed streaming=True to .collect() that streaming will be used. This is because some operations don’t support streaming. If there’s an operation for which streaming isn’t supported, Polars will use non-streaming mode instead.
If you’re unsure as to whether or not any of your operations support streaming, the documentation provides the current list of operations that do. Alternatively, you can pass both streaming=True and optimized=True to .explain() to find out:
1>>> import polars as pl
2
3>>> rides = pl.scan_parquet("rides.parquet")
4
5>>> print(
6... (
7... rides
8... .filter(pl.col("pick_up") == pl.col("drop_off"))
9... .group_by(pl.col("pick_up"))
10... .agg(pl.col("drop_off").mean())
11... .filter(
12... pl.col("pick_up").is_in(
13... ["Brooklyn", "Bronx", "Queens", "Manhattan"]
14... )
15... )
16... ).explain(streaming=True, optimized=True)
17... )
18STREAMING:
19 AGGREGATE
20 [col("drop_off").mean()] BY [col("pick_up")] FROM
21 Parquet SCAN [rides.parquet]
22 PROJECT 2/5 COLUMNS
23 SELECTION: [([(col("pick_up")) == (col("drop_off"))])
24⮑ & (col("pick_up").is_in([Series]))]
The query plan shows that this entire query supports streaming. The STREAMING marker at line 18 shows this.
In this second example, some of the operations can’t work with streaming:
>>> import polars as pl
>>> rides = pl.scan_parquet("rides.parquet")
>>> print(
... (
... rides
... .filter(pl.col("pick_up") == pl.col("drop_off"))
... .with_columns(
... pl.col("fare")
... .mean()
... .over(pl.col("pick_up"))
... .alias("mean fare")
... )
... ).explain(streaming=True, optimized=True)
... )
WITH_COLUMNS:
[col("fare").mean().over([col("pick_up")]).alias("mean fare")]
STREAMING:
Parquet SCAN [rides.parquet]
PROJECT */5 COLUMNS
SELECTION: [(col("pick_up")) == (col("drop_off"))]
This time, the STREAMING marker is within the query plan. Again reading from the bottom, this means the SCAN, PROJECT, and SELECTION processes all support streaming, while the WITH_COLUMNS part doesn’t. The reason is that in order for the query to calculate the mean fare, it needs all of the data, so streaming isn’t an option. In this case, the entire query will run without streaming even if that was your intention.
Next, you’ll learn, despite their power, LazyFrames have their limitations.
How to Decide if LazyFrames Are Suitable
At this point, you’ve learned about the many benefits that LazyFrames provide over DataFrames. Indeed, you may even be wondering why anyone would want to work with DataFrames at all. However, while LazyFrames are powerful, they’re not always suitable because some processing requires the underlying data to be present in a DataFrame before it’ll work.
A pivot table is a common tool used in data analysis to summarize large volumes of data by grouping it into categories and performing an aggregation on those categories. Suppose you wanted to see the total passengers carried between the different locations. You could do this using a pivot table:
>>> import polars as pl
>>> rides = pl.scan_parquet("rides.parquet")
>>> (
... rides
... .pivot(
... on="pick_up",
... index="drop_off",
... values="passengers",
... aggregate_function="sum",
... )
... )
Traceback (most recent call last):
...
AttributeError: 'LazyFrame' object has no attribute 'pivot'.
⮑ Did you mean: 'unpivot'?
In this code, you’ve attempted to create a LazyFrame that will contain a separate column for each pick_up, and a separate row for each drop_off. At each row/column intersection, the sum of the number of passengers transported between them should be calculated. Unfortunately, the code failed with an AttributeError because LazyFrames don’t support .pivot().
To fix this, you need to use a DataFrame:
>>> (
... rides
... .collect()
... .pivot(
... on="pick_up",
... index="drop_off",
... values="passengers",
... aggregate_function="sum",
... )
... )
shape: (8, 9)
┌───────────────┬───────────┬────────┬─────────┬───┬
│ drop_off ┆ Manhattan ┆ Queens ┆ Unknown ┆ … ┆
│ --- ┆ --- ┆ --- ┆ --- ┆ ┆
│ str ┆ i32 ┆ i32 ┆ i32 ┆ ┆
╞═══════════════╪═══════════╪════════╪═════════╪═══╪
│ Manhattan ┆ 3041648 ┆ 256376 ┆ 4686 ┆ … ┆
│ Queens ┆ 111178 ┆ 115640 ┆ 629 ┆ … ┆
│ Brooklyn ┆ 68712 ┆ 66116 ┆ 333 ┆ … ┆
│ Bronx ┆ 12006 ┆ 10396 ┆ 59 ┆ … ┆
│ Unknown ┆ 9668 ┆ 1016 ┆ 7512 ┆ … ┆
│ N/A ┆ 6312 ┆ 17630 ┆ 66 ┆ … ┆
│ Staten Island ┆ 346 ┆ 718 ┆ 2 ┆ … ┆
│ EWR ┆ 12759 ┆ 806 ┆ 27 ┆ … ┆
└───────────────┴───────────┴────────┴─────────┴───┴
┬──────┬───────┬──────┬───────────────┐
┆ N/A ┆ Bronx ┆ EWR ┆ Staten Island │
┆ --- ┆ --- ┆ --- ┆ --- │
┆ i32 ┆ i32 ┆ i32 ┆ i32 │
╪══════╪═══════╪══════╪═══════════════╡
┆ 113 ┆ 3749 ┆ 14 ┆ 11 │
┆ 148 ┆ 830 ┆ 1 ┆ 3 │
┆ 20 ┆ 924 ┆ 1 ┆ 38 │
┆ 23 ┆ 1785 ┆ null ┆ null │
┆ 37 ┆ 13 ┆ 10 ┆ null │
┆ 2974 ┆ 82 ┆ 25 ┆ 5 │
┆ null ┆ null ┆ null ┆ 45 │
┆ 131 ┆ 6 ┆ 1034 ┆ 3 │
┴──────┴───────┴──────┴───────────────┘
This time, everything works as expected. Even though you started out with a LazyFrame, because you called .collect() on it to materialize it, the .pivot() method worked as expected because it was using actual data stored in a DataFrame. DataFrames are quite happy using .pivot(), so the code ran without error. You have the result you want, which has been split into two parts for display purposes.
To maximize efficiency, you can also run part of an analysis query in lazy mode and part in eager mode. Although you’re happy with the result above, suppose you decide you only want to see the details for Brooklyn, Bronx, and Queens. To do this, you again use filter():
1>>> boroughs = ["Brooklyn", "Bronx", "Queens"]
2>>> (
3... rides
4... .filter(pl.col("pick_up").is_in(boroughs))
5... .filter(pl.col("drop_off").is_in(boroughs))
6... .collect()
7... .pivot(
8... on="pick_up",
9... index="drop_off",
10... values="passengers",
11... aggregate_function="sum",
12... )
13... )
14shape: (3, 4)
15┌─────────────┬────────┬──────────┬───────┐
16│ drop_off ┆ Queens ┆ Brooklyn ┆ Bronx │
17│ --- ┆ --- ┆ --- ┆ --- │
18│ str ┆ i32 ┆ i32 ┆ i32 │
19╞═════════════╪════════╪══════════╪═══════╡
20│ Brooklyn ┆ 66116 ┆ 18854 ┆ 924 │
21│ Queens ┆ 115640 ┆ 3442 ┆ 830 │
22│ Bronx ┆ 10396 ┆ 862 ┆ 1785 │
23└─────────────┴────────┴──────────┴───────┘
As you saw earlier, .filter() can operate on LazyFrames so you can apply it here. In the example above, this means that lines 3 through 5 will run optimally in lazy mode. Then, because .pivot() can’t work in lazy mode, you call .collect() to create a DataFrame containing the data for pivot() to work with. This time, .pivot() will only be using the data from the three desired locations.
Had there been further processing that did support lazy mode, but that first required a DataFrame to be present, you’d flip things back across using .lazy().
For example, suppose you want to add additional analysis that allows you to view only the row where the maximum number of passengers appears. You can do this using .select(). While .select() works in both eager and lazy mode, you should work lazily whenever possible:
>>> boroughs = ["Brooklyn", "Bronx", "Queens"]
>>> (
... rides
... .filter(pl.col("pick_up").is_in(boroughs))
... .filter(pl.col("drop_off").is_in(boroughs))
... .collect()
... .pivot(
... on="pick_up",
... index="drop_off",
... values="passengers",
... aggregate_function="sum",
... )
... .lazy()
... .select(pl.max("*"))
... ).collect()
shape: (1, 4)
┌─────────────┬────────┬──────────┬───────┐
│ drop_off ┆ Queens ┆ Brooklyn ┆ Bronx │
│ --- ┆ --- ┆ --- ┆ --- │
│ str ┆ i32 ┆ i32 ┆ i32 │
╞═════════════╪════════╪══════════╪═══════╡
│ Queens ┆ 115640 ┆ 18854 ┆ 1785 │
└─────────────┴────────┴──────────┴───────┘
To allow .select() to work in the more desirable lazy mode, you flip the query back into lazy mode using .lazy() as highlighted. Once you’re working lazily again, you use .select(pl.max("*")) to select the row containing the highest value. In this case, it’s the row containing 115640. You also remembered to use .collect() to materialize the data—otherwise, you’d only see the LazyFrame object with its sub-optimized query plan.
Note: If you want to see a list of Polars operations that aren’t supported in lazy mode but only on DataFrames, then run the following code in your favorite Python REPL:
>>> df_ops = {
... x for x in dir(pl.DataFrame()) if not x.startswith("_")
... }
>>> lazy_ops = {
... x for x in dir(pl.LazyFrame()) if not x.startswith("_")
... }
>>> print(sorted(df_ops - lazy_ops))
['corr', 'drop_in_place', 'equals', 'estimated_size', 'extend', 'flags',
⮑ 'fold', 'get_column', 'get_column_index', 'get_columns', 'glimpse',
⮑ 'hash_rows`, 'height', 'hstack', 'insert_column', 'is_duplicated',
⮑ 'is_empty', 'is_unique', ... ]
The code creates two Python set data structures named df_ops and lazy_ops. These contain the various DataFrame and LazyFrame operations whose names don’t begin with the underscore (_) character. These represent the complete set of operations for both DataFrames and LazyFrames. To identify operations that apply to DataFrames but not LazyFrames, you can compute the difference between the two sets df_ops and lazy_ops.
You also call the built in print() function to print some of the output. The full output is quite extensive, so you only show a sample.
This code is based on that found in the book Effective Polars Optimized Data Manipulation by Matt Harrison.
Congratulations on completing this tutorial. You can now look forward to using LazyFrames to analyze your data efficiently.
Conclusion
In this tutorial, you’ve learned how to work with Polars LazyFrames. To begin with, you learned how to create one before diving a little deeper to understand how they achieve efficiency. You then learned the techniques that allow your LazyFrames to deal with large volumes of data before wrapping up with an understanding of their limitations.
As you can see, LazyFrames may not solve every data analysis problem, but they do provide an efficient solution for many. Looking forward, Polars is a library that’s still growing and its capabilities are expanding. Be sure to keep an eye on the latest developments in this exciting data analysis tool.
Get Your Code: Click here to download the free sample code that shows you how work with Polars LazyFrames.
Take the Quiz: Test your knowledge with our interactive “How to Work With Polars LazyFrames” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
How to Work With Polars LazyFramesThis quiz will challenge your knowledge of working with Polars LazyFrames. You won't find all the answers in the tutorial, so you'll need to do some extra investigating. By finding all the answers, you're sure to learn some interesting things along the way.
Frequently Asked Questions
Now that you have some experience with Polars LazyFrames in Python, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
In Polars, a LazyFrame is a structure that holds a set of instructions or a query plan to efficiently process data, without actually containing the data itself.
In Polars, you use .collect() to materialize a LazyFrame into a DataFrame by executing its query plan and fetching the actual data, while .fetch() isn’t a method used in Polars.
You read a CSV file in Polars by using the pl.scan_csv() function to create a LazyFrame or the pl.read_csv() function to load the data into a DataFrame.







