Maybe you’ve already worked with Jupyter Notebooks from Project Jupyter to create documents containing runnable code. You can achieve even more with JupyterLab, a tool kit that you can use to document and share your research, teaching, and learning activities. It’s useful in a wide range of disciplines, from data analysis and data visualization to scientific study.
JupyterLab enhances your notebooks by providing a browser-based interface that allows you to use multiple notebooks together effectively. In addition, it offers you a comprehensive Markdown editor, file manager, file viewer, and an infrastructure that enables you to run code from a wide range of files.
In this tutorial, you’ll learn how to:
- Share code between multiple Jupyter Notebooks
- Debug a Jupyter Notebook
- Create and manage Markdown files
- Run embedded code from a range of different files
- Manage and view different file types from a single interface
- Access your operating system from within JupyterLab
Jupyter is a portmanteau word blended from the three programming languages Julia, Python, and R. Although you’ll focus on Python in this tutorial, you can use Jupyter with the other languages as well. Plus, this free application works on macOS, Linux, and Windows environments.
JupyterLab takes Jupyter Notebook usage to a different level, so you’ll get the most out of this tutorial if you’re already familiar with Jupyter Notebook.
Free Bonus: Click here to download notebooks and files that you can play with in JupyterLab.
Installing and Starting JupyterLab
The cleanest way of installing JupyterLab on a computer is to use a virtual environment. This will ensure that your JupyterLab work doesn’t interfere with any other Python projects or environments that you may already have. For this tutorial, you’ll create a new virtual environment named jl_venv. Select your operating system to get JupyterLab up and running:
Of course, once you’ve finished this tutorial, you can delete tutorial_project and add in your own project-specific folders instead.
Note: If you wish, you could create a Samples subfolder within tutorial_project and save this tutorial’s downloadable files into it. These include completed versions of the notebooks that you’ll create later on, as well as some other files. This will also give you some files to play around with and will allow you to fully participate in the tutorial.
JupyterLab will start in your web browser, all ready for you to use. But before you dive in, you might want to know how to end your session:
-
To shut JupyterLab down, make sure everything is saved, and then use File → Shut Down to close the application before closing your browser. This will close everything down cleanly. Closing the browser alone doesn’t close the server, while crashing the server may cause data loss.
-
To restart, open either Powershell or your terminal, navigate to your
jupyterlab_projectsfolder, then activatejl_venv. Finally, create or enter your specific project’s folder then start JupyterLab as before. -
To deactivate your virtual environment, use the
deactivatecommand. Your command prompt will return to normal.
Once you’ve installed and started JupyterLab, its server will start, along with a web browser connection to it. It may take a moment, but soon you’ll be looking at its main interface:
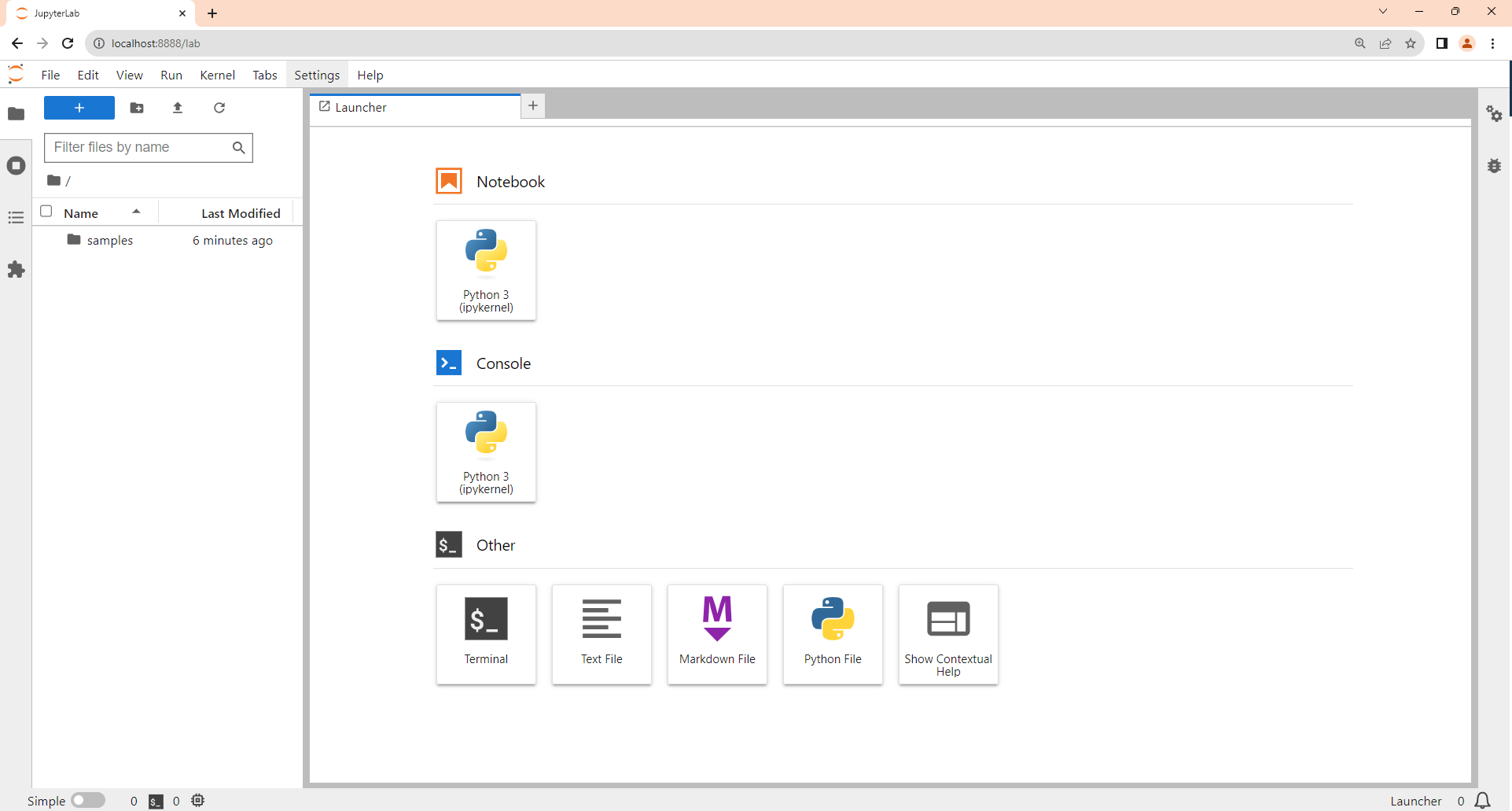
Because this is your first time running JupyterLab, the front screen shown above contains only a single Launcher window. This is where you can access everything else that’s on offer.
Note: Before you start using JupyterLab, you may like to change its appearance to make it easier for you to use. There are several options available to you:
-
You can hide or display various screen regions using View → Appearance. This is useful if you have a small monitor.
-
You can change the overall theme of the interface by opening Settings → Theme. Themes may help you see more clearly.
-
You can also increase and decrease various font sizes using the options under Settings and Settings → Theme. These may help clarify text.
You can even use your favorite coding font by accessing Settings → Settings Editor and then scrolling down the list of settings on the left until you reach Notebook. Once you’re there, fill out the font family and font size according to your preferences. Then close the Settings tab:
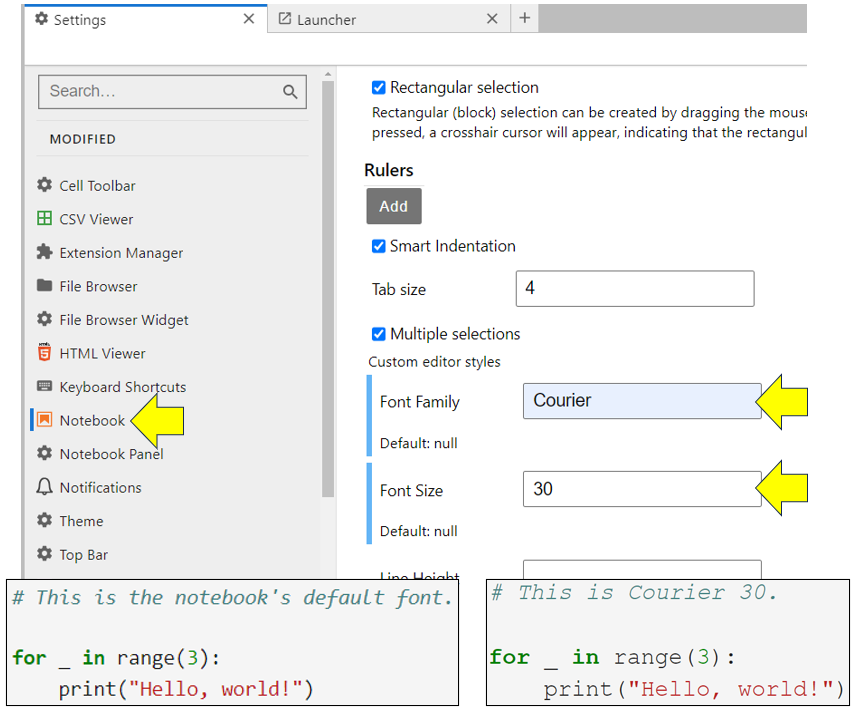
As you can see from the screenshot, you’ve updated the font within your notebooks. If you don’t like your adjustments, then click the big red Restore to Defaults button that appears at the top-right of the Settings screen, and no harm done.
In the upcoming sections, you’ll perform a range of tasks highlighting how JupyterLab’s tools enhance the capability of notebooks. You’ll also see some other interesting features as well.
Understanding JupyterLab Kernels
JupyterLab’s tools support you in your work. Although the tools are self-contained, by using some of them together, you get more out of them. This integration is probably JupyterLab’s most powerful feature.
A good starting point when learning JupyterLab is for you to know what its basic components are and how to make them work together. The diagram below shows an overview of these:
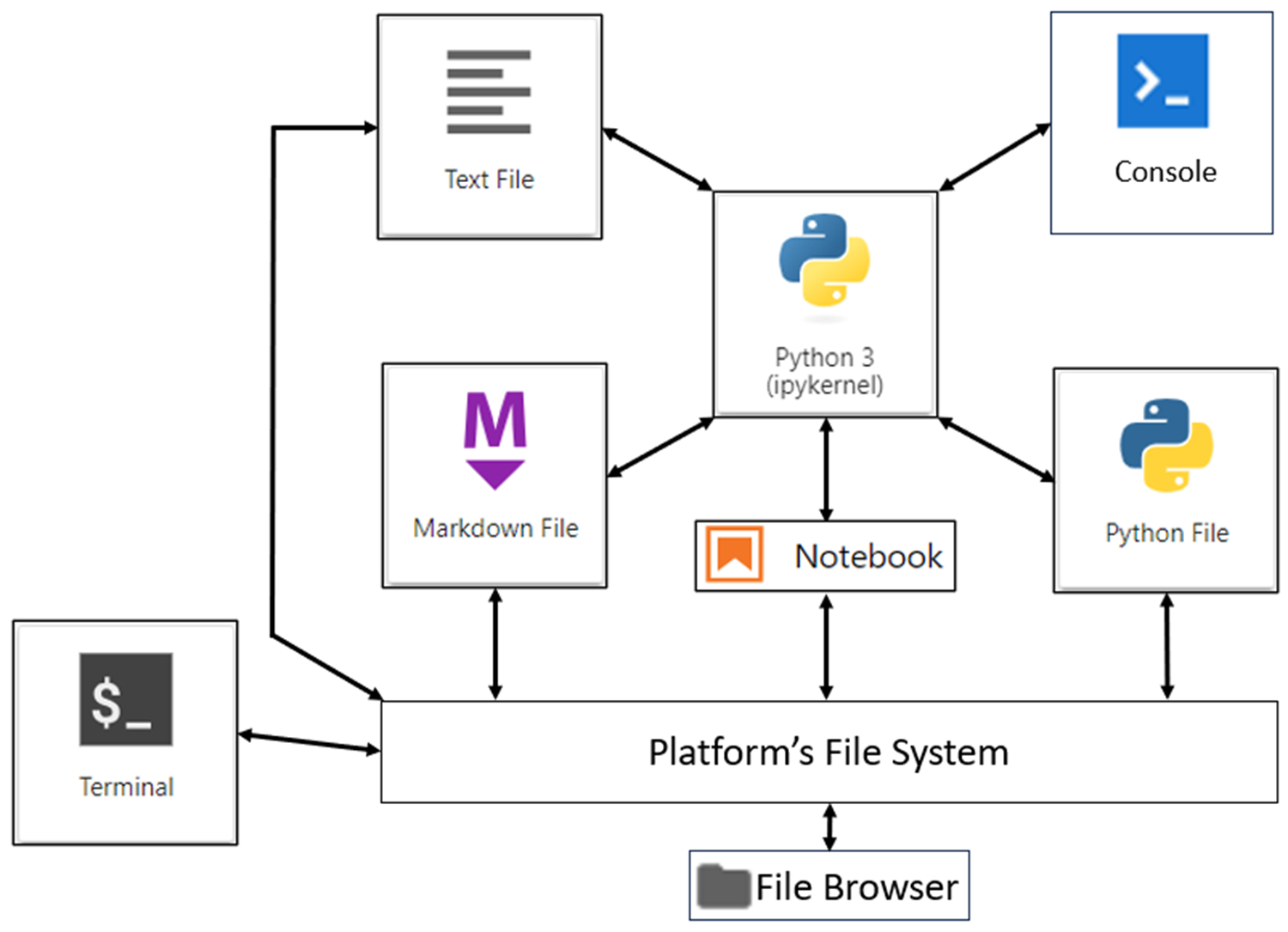
This diagram may look overwhelming at first because there are several parts. Don’t worry, you’ll soon see their relevance. The arrows show how various components interact. These interactions are one of the great benefits of JupyterLab. You’ll start with the central part of the application and the diagram: the kernel.
The most important component of your JupyterLab installation is its kernel. As you can see from the previous diagram, it’s central to the application. Whenever you start a new Jupyter Notebook or console, you click a button that looks like this:

When you click the button, you start an instance of the JupyterLab kernel. This is a process that links your file to a console. The file can be any that contains code such as a notebook, a Python file, a Markdown file, or even a text file. The kernel passes the programming code from the file to the console. The console then runs the code and displays any output. In the case of a Jupyter Notebook, output gets displayed in the notebook itself.
Note: Anytime you read about kernels in the context of JupyterLab, it means a process that links a file to a console. In computing, the word kernel usually refers to the core of your computer’s operating system that allows it to interact with hardware. This has nothing to do with the kernels that you’ll use here, so don’t confuse these different meanings.
Opening a Jupyter Notebook automatically opens a kernel for it. This is why you can immediately run code from within it. Kernels also allow you to run code embedded within other file types, such as Markdown files, as you’ll learn later. The screenshot below shows some open documents, some of which are using kernels:
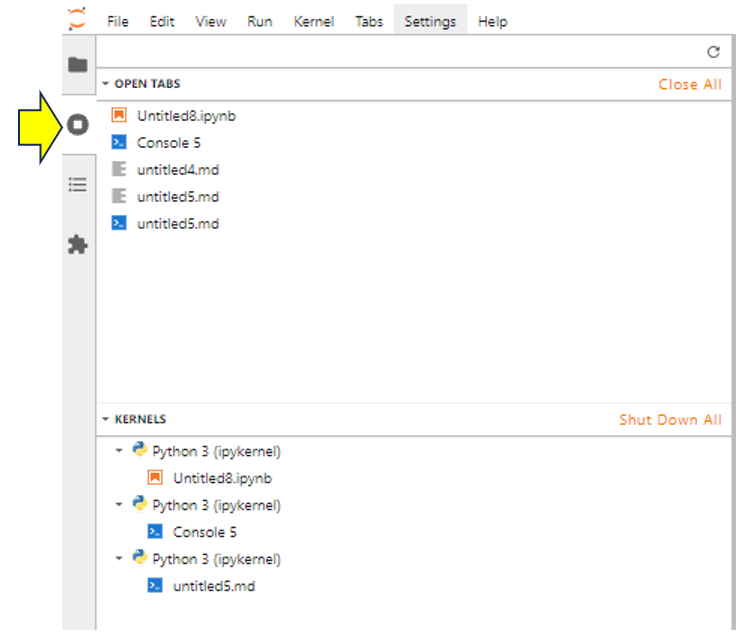
If you look carefully at the output, then you’ll see from the top part there are five open tabs:
Untitled8.ipynb, a Jupyter Notebook that has been assigned automatically to a kernel.Console5, a console that has been automatically assigned to a kernel.- The
untitled4.mdfile, which has no kernel assigned to it. This Markdown file can contain code, but you won’t be able to run it. - The
untitled5.mdfile, which has had a console assigned to it and therefore also has a kernel assigned to it. You could run code contained within this Markdown file.
As you work through the rest of this tutorial, you’ll see how important the kernel is.
Working With Jupyter Notebook in JupyterLab
Although this tutorial isn’t a dedicated Jupyter Notebook tutorial, you’ll now perform some common tasks so you can appreciate what JupyterLab brings to Jupyter Notebooks. Start a new Jupyter Notebook within JupyterLab by clicking the large Python 3 button below the Notebook heading as shown:
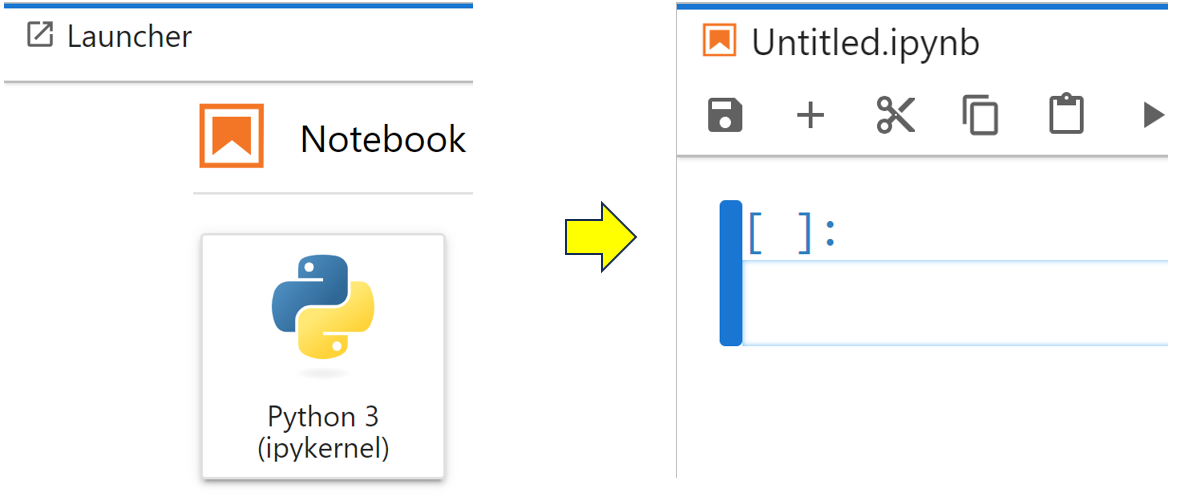
This will open a new Jupyter Notebook named Untitled.ipynb. You’ll most likely want to give it a more descriptive name, and you can do so by right-clicking its tab, selecting Rename Notebook…, then changing the name to something more meaningful. In this example, you choose to rename it Population Data:
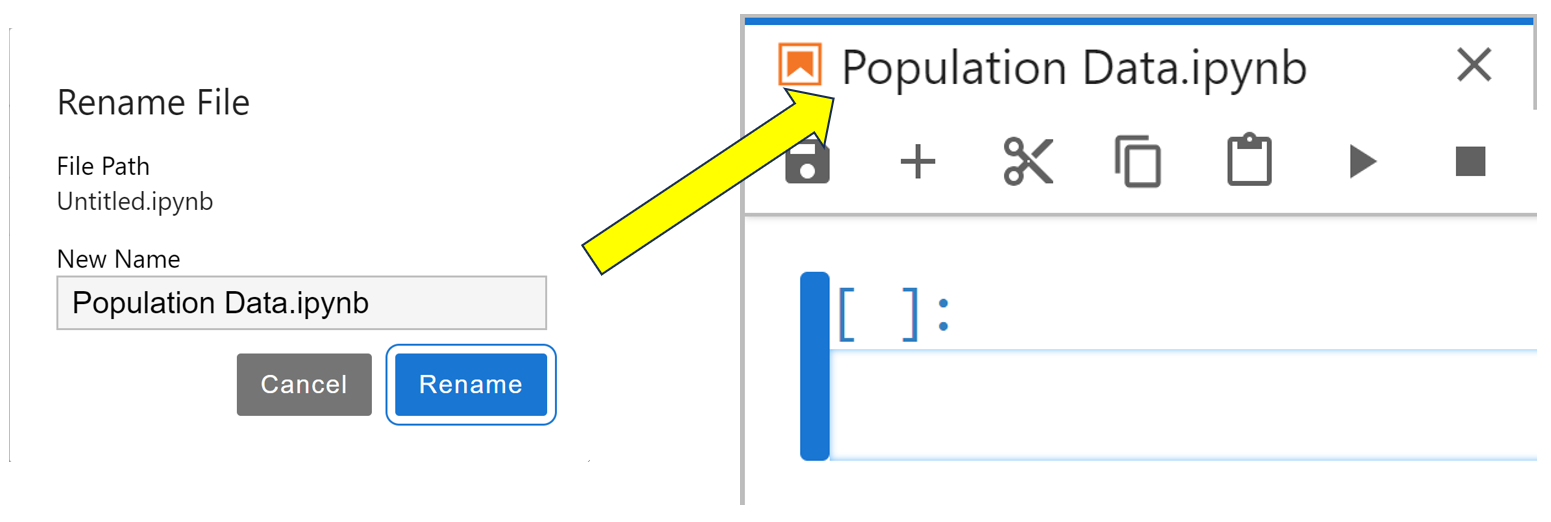
Once you’ve entered the new name, click the blue Rename button to update your notebook with its new name.
When you open a new notebook, it contains a single gray rectangle. This is a code cell as indicated by the Code text shown in a dropdown option of the toolbar above it. You won’t be surprised to learn that this is where you enter program code, but you probably won’t do this immediately. Usually, when you create a notebook, you’ll want to start with some formatted Markdown text as an introduction.
To create some Markdown, select the code cell and then select Markdown from the dropdown menu in the toolbar. This will prepare the cell for you to enter Markdown text into. Now type the following Markdown text into this cell:
### Changes in World Population Since 1960
The data shown below shows how the
[world's population](https://www.worldometers.info/world-population/world-population-by-year/)
has more than doubled since 1960.
This has [implications](https://ugc.berkeley.edu/background-content/population-growth/)
in a variety of areas including:
* Increased extraction of environmental resources.
* Increased fossil fuel usage.
* Increased disease transmission.
* Increased transportation of invasive species.
**The data below shows the population each decade since 1960:**
When you typed in the text, you may have wondered why you used the hashes, asterisks, and brackets. The best way to find out is to run the cell. You can do this either by clicking the small right-pointing triangle beneath the notebook’s tab or by using Shift+Enter. Either way, you’ll run the cell and render its Markdown on-screen:

As you can see, you used the # symbol to specify a heading, while your []() symbols created hyperlinks to the data sources. You created a bulleted list using single asterisks, while double asterisks made your text bold. In other words, you used these characters to define the format of your output.
If your Markdown cell didn’t render correctly, then you can double-click on it and fix it. Rerun it once you’ve changed any errors, and it should render correctly. Remember, each symbol makes a significant difference as to how the result will look.
You may also have noticed that a fresh code cell has appeared below your Markdown cell. You then add in the following code:
decades = [1960, 1970, 1980, 1990, 2000, 2010, 2020]
# World population (billions)
population = [3, 3.7, 4.4, 5.3, 6.1, 7.0, 7.8]
You’ve entered the population data as two Python lists. Your first list contains decades, while the second contains the world’s population for each decade. When you run the cell using Shift+Enter, the code runs and becomes formatted.
Although running this cell produces no output, running it is still important because it sets up the lists and assigns them to their variables. In other words, the notebook’s kernel becomes aware of them, meaning the variables then become available to subsequent cells in your notebook, and even to other notebooks if you share this notebook’s kernel.
While the data makes sense by itself, wouldn’t it be more striking if you displayed it in a chart? Fortunately, you can do this by using the Matplotlib library. As with all third-party libraries, you need to install matplotlib into your Python environment because it’s not part of the Python standard library.
The notebook interface allows you to install third-party packages into your current Python environment directly from a code cell, without needing to switch to a terminal. You can execute shell commands in a code cell by prefixing them with an exclamation point (!).
So, to install the matplotlib library, you type !python -m pip install matplotlib in a new code cell and run it. You’ll know the code cell is running when a [*] appears next to it. This will change to a number in square brackets once the installation is finished. This number indicates the sequence in which that particular code cell was executed.
Once the command is complete, you’ll see some installation output:
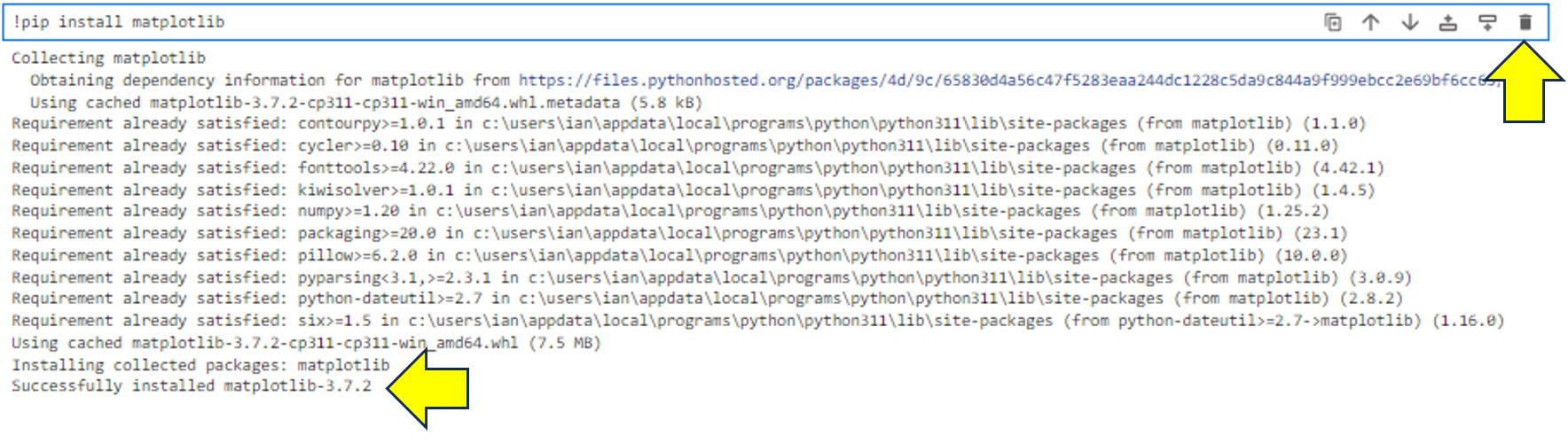
As you can see, a new code cell has appeared below the output of your pip command. You can verify that the installation was successful by reading the last line of output. You can then tidy up the notebook by selecting the cell containing the !python -m pip install matplotlib command and clicking the trash icon as shown. This will delete it. Don’t worry, matplotlib will still be installed, and only the mess will be gone.
Note: You may have noticed the collection of icons to the left of the trash icon. These allow you to manipulate the cells. Hover your mouse over each of them to learn what they do. Feel free to click on any to clarify your understanding. You can also trash anything that you inadvertently create to get rid of it.
Now you display your data in a chart. To do this, type the following code into a new code cell and run it:
from matplotlib import pyplot as plt
plt.plot(decades, population)
plt.xlabel("Year")
plt.ylabel("Population (Billion)")
plt.title("World Population")
plt.show()
First of all, you import pyplot. This provides access to a set of functions that you use to manage your plots. For example, you create the basic plot using pyplot’s plot() function. You also use functions to define the labels on each axis and to give your chart its title. When you type the above code into the new code cell and run it, you chart your data:
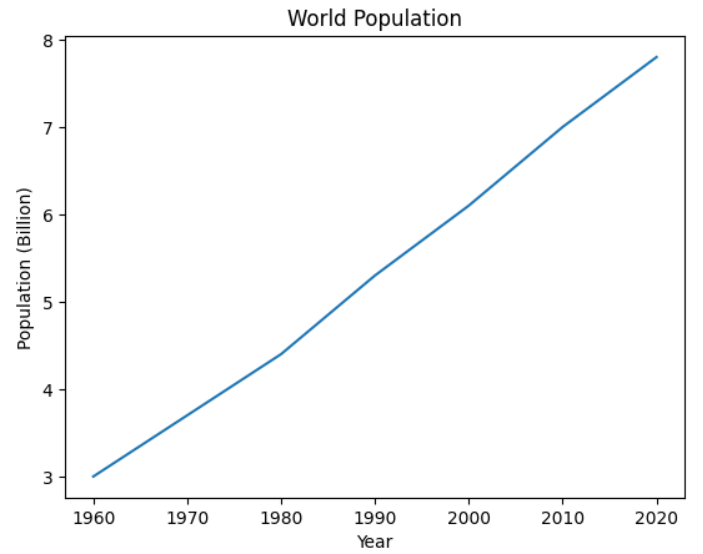
Although you’ve created a simple chart for demonstration purposes, you can further customize your chart any way you like using the capabilities of Matplotlib. After all, your notebook is using the same Matplotlib library that you may already be familiar with from your other programming projects.
Note: If you’re using a function or method inside a Jupyter Notebook, then you can find information about it using the Shift+Tab keys. This will display its docstring content, if it has any. You can try this out by typing plt.title( followed by Shift+Tab.
Suppose you now decide that you no longer want to analyze all the data. Instead, you’re interested in population data from 1980 onwards. All you need to do is update your data and rerun the cells.
Go ahead and update the original cell with the code shown below. You can comment out the original data just in case you want to return to it later:
# decades = [1960, 1970, 1980, 1990, 2000, 2010, 2020]
# World population (billions)
# population = [3, 3.7, 4.4, 5.3, 6.1, 7.0, 7.8]
decades = [1980, 1990, 2000, 2010, 2020]
population = [4.4, 5.3, 6.1, 7.0, 7.8]
Once you’ve made your changes, rerun the cell to update the content of the decades and population list variables. Then, to update the chart, you rerun the cell containing the chart code. With this, you’ve updated your chart, and it should now look like this:
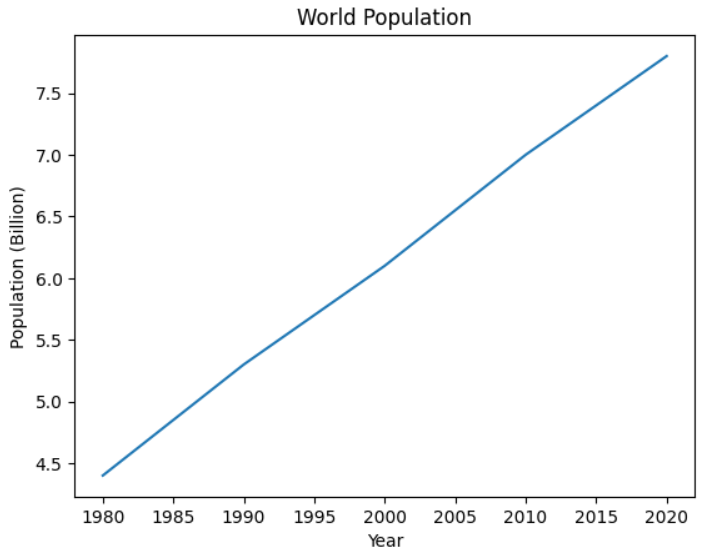
As you can see, only the years 1980 through 2020 are now displayed in your chart.
Note: You may also see a third cell type named raw. Anything that you type into these cells stays exactly the same as you originally typed it. You can’t apply any formatting to it. You’d use these cells for typing data in common formats such as LaTeX source. These cells can, for example, be rendered by passing them to a TeX program.
Earlier you learned that JupyterLab contains features that enhance Jupyter Notebook. It’s now time for you to see this in action.
Working With Multiple Notebooks
Next you’ll learn how JupyterLab helps you work with multiple notebooks. To do this, of course, you’ll need to create another notebook.
Keep your Population Data notebook open and open a second one. To do this, click the New Launcher ‘+’ tab. Now launch another notebook by clicking the Python 3 icon under the Notebook heading. A second notebook will launch in its own tab. Right-click this tab and rename the notebook Population Changes:
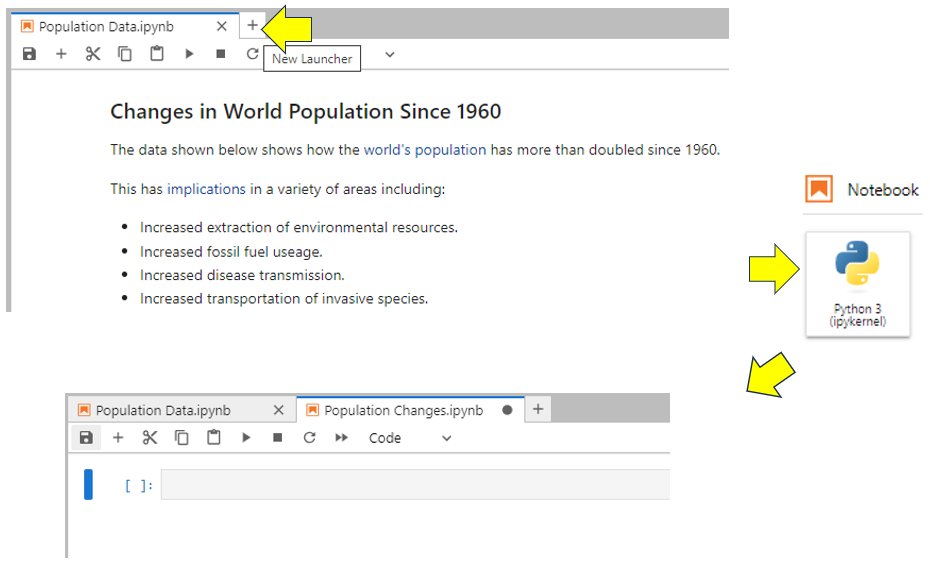
As you can see, the notebook tabs are placed beside each other. To keep things looking professional, you might like to add some Markdown explaining a little about the intended content of your Population Changes notebook:
### Population Changes Since 1980
The data shown below shows the decade-on-decade increases in the
[world's population](https://www.worldometers.info/world-population/world-population-by-year/)
since 1980.
Again, don’t forget to run the Markdown cell using Shift+Enter to render it into the cell.
Although the current notebook arrangement makes it easy to flip between them by clicking their tabs, suppose you wanted to use this second notebook to analyze your world population data. The first thing you’d need to do is add in the population data from your Population Data workbook. You could, of course, copy and paste, but JupyterLab allows you to drag cells directly between different notebooks, provided you can see them both simultaneously:
To display notebooks side by side, you dragged the tab of the Population Changes notebook down and to the right of the Population Data notebook. When you released your mouse, both workbooks became viewable.
Then, to copy the cells between notebooks, you selected the cell containing the decades and population lists in Population Data. You know you’ve selected it when a blue vertical bar appears to the right of the cell.
Finally, you grabbed the margin area as shown and dragged it across onto Population Changes before dropping it. You used the fine blue horizontal line that appeared as a placement guide.
Note: If you’ve moved the cell into the wrong place, select it and drag it vertically to where you want it to go. Also, if you want to move the notebook back to where it was, drag the Population Changes tab back up and next to the Population Data tab where it originally was.
Adding a Python Library Into a Notebook
Next, you’ll analyze the Population Changes notebook. To do this, you need to add some more code and import the pandas library.
In a code cell immediately below the one that you just copied across, add in the following code:
def calculate_differences(data_set):
differences = [0]
for index in range(1, len(data_set)):
differences.append(round(data_set[index] - data_set[index - 1], 1))
return differences
population_change = calculate_differences(population)
Your calculate_differences() function accepts a list of numbers and calculates the differences between each of its elements. These differences are returned as a separate list. The final line of code calls the function and stores the returned list when you run the cell. Nothing will be displayed.
Before you go any further, make sure to run this cell to ensure its content is known to the underlying kernel.
Next you’ll create a pandas DataFrame. Having your data in a pandas DataFrame allows you to perform lots of data analysis on it. Here you’ll settle for a neat table containing the data.
pandas is another module that’s not part of the native Python language, so you’ll need to install it. To do so, add a new code cell and use !python -m pip install pandas. Run the cell, and pandas will install. Check the final line of the output to make sure there were no installation errors. You can then delete the output of the pip install command by selecting its cell and sending it to trash.
Note: The pandas module has actually been installed into the underlying Python programming environment or virtual environment that’s driving each of your notebooks. This means that instead of rerunning the pip command in other notebooks, you only need to import pandas. Also, the next time you restart JupyterLab, pandas will still be there for you.
Once you’ve successfully installed pandas, you can use it to analyze your data any way you wish. Here you only want a DataFrame, so add the following code into a code cell in your notebook:
import pandas as pd
zipped = list(zip(decades, population, population_change))
columns=["Decade", "Population(Bn)", "Change"]
population_df = pd.DataFrame(zipped, columns=columns)
print(population_df)
To use the pandas module that you just installed, you must import it. You then use Python’s built-in zip function to iterate over each of your lists in parallel and produce a collection of tuples with an item from each one. You then pass that collection into the pandas DataFrame constructor to produce a DataFrame. In addition, you specify the columns of the DataFrame using the columns parameter.
As you can see when you run the cell, the DataFrame displays as a neat table:

Did you know that the world’s population is increasing at a nearly constant rate each decade? Oh, the things you learn from Real Python tutorials!
Looking at Views
If you have a long file, you may need to scroll down to view what you’re interested in. To overcome this, JupyterLab allows you to create multiple synchronized views of your files. When you create a new view on a file such as a notebook, you’re creating a new interface for accessing it. Each view allows you to look at separate parts of your file at the same time. What’s more, if you change a notebook, its view updates as well.
Suppose you want to view your Matplotlib chart outside of its notebook. To do this, you create a new view of your chart in its own tab. However, the chart will still be linked to the underlying notebook code. If you change the chart’s data in the notebook, then you’ll update the chart in both the notebook and the view. This is very useful if your notebook is long and you want to see different parts of it at the same time.
Note: While you can’t create views of Markdown cells, you can work around this by creating a view of an entire notebook. To do this, right-click on the tab of the workbook that you wish to create a view on and choose New View for Notebook. Your new view will appear in a separate tab. You can then scroll around the view independently of the original notebook.
Select your Population Data notebook and then the cell containing the Matplotlib code:
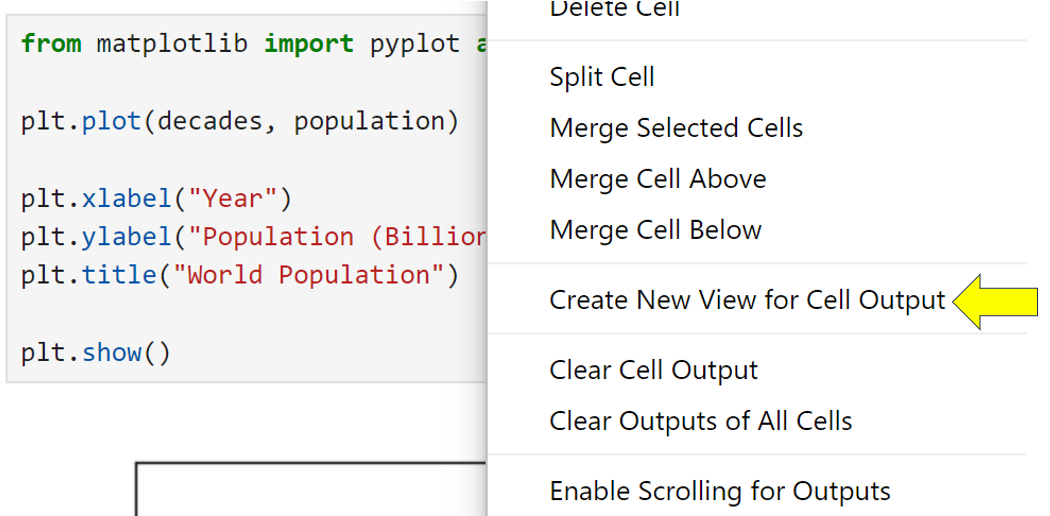
Now right-click on the cell or the existing chart and select Create New View for Cell Output. A new view tab will appear below the notebook. You can move the position of the view around the screen to wherever you wish by dragging and dropping its tab. The view will always display the same content regardless of which cells you’re looking at in its underlying notebook:
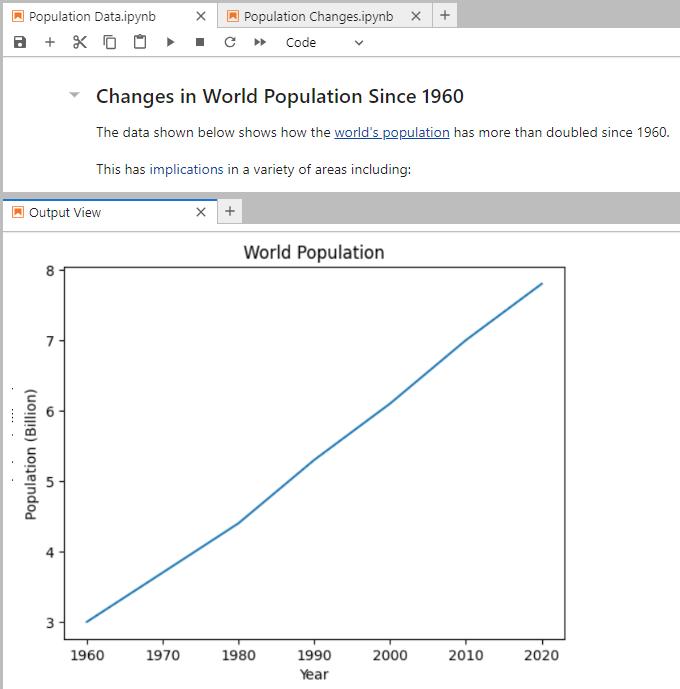
As you can see, the new view appears immediately below the notebook that it’s a view of. Feel free to change the data contained in your population data notebook and rerun its cell as well as the cell containing the chart. In addition to updating the chart in the notebook, this will also update it in the view.
If you close the notebook, you’ll close the view. Unlike notebooks, views aren’t saved. To close the view alone, simply close it by clicking the X on its tab.
Note: Views are most commonly associated with Jupyter Notebooks, but you can actually create them on any file type available within JupyterLab. As an example, you could create two views on a long PDF file that allow you to see both its first and last pages. Also, because all views on a file are looking at the same file, any changes that you make through one view will reflect in the other views.
Of course, creating multiple views when combined with opening multiple files can be very useful, but it would be tiresome having to open everything up again each time you restart JupyterLab. Fortunately, you don’t actually have to, as you’ll see next.
Working With Workspaces
A JupyterLab workspace is a saved layout of its various components, such as open notebooks and terminals. By default, JupyterLab saves changes to your layout automatically. This allows you to continue with the same layout that you had when you last closed it. You’ll find this very useful if you perform your analysis over many sessions.
If you’re working on multiple projects that all need their own sets of files or other components opened simultaneously, you can save their layout as a custom workspace so that you can quickly return to it again later.
A workspace is a JSON file containing information about the files it contains and their layout on-screen. This means that if you delete the workspace file, you won’t delete any files that it references.
It’s possible to save the layout of the contents of a JupyterLab session, including its views. To do this, you save the workspace. First of all, make sure you’ve saved everything. You can do this quickly by choosing the File → Save All menu option. To save the layout, select File → Save Current Workspace As, and then give it a name such as population_analysis.jupyterlab-workspace. This will add a workspace layout file to the file browser:
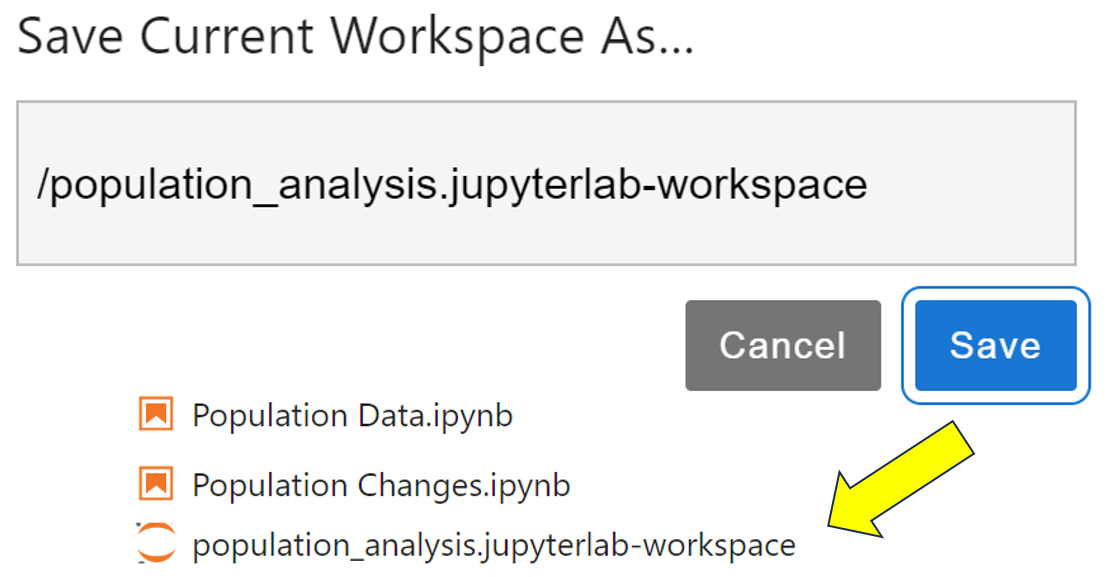
The next time you open JupyterLab, it’ll display everything the way it was when you last closed the program because it automatically updates workspaces as you change them. To return to a saved workspace, double-click on its file from the browser, and everything will reset to the way it was when you last saved it. When you make changes to a layout, choose File → Save Current Workspace to update your saved workspace.
Sharing Code Between Notebooks
If you need to perform lots of analysis in a notebook, there’s a danger that your notebook will become long and difficult to work with. Instead of creating a single large notebook, it’d be better to split your analysis down into separate notebooks. One way would be to duplicate your data, but this creates data management issues whenever your data changes. Fortunately, JupyterLab allows you to share data from one notebook with others.
Earlier you learned that the kernel is responsible for passing the code from a notebook to a console for running. Once the code has finished, the kernel returns its output back to your Jupyter Notebook for display. So, the kernel provides access to any data or functions that your program uses. By linking additional notebooks to the kernel of a notebook, its content becomes available to those additional notebooks.
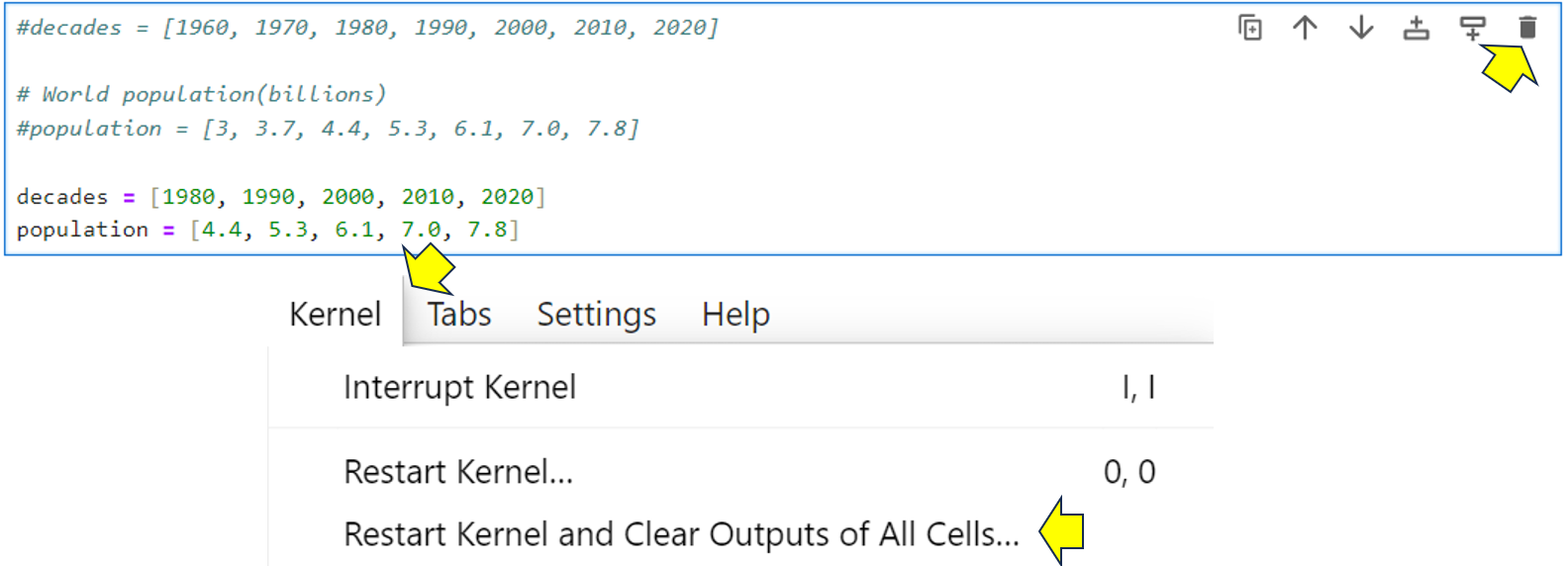
Locate the cell in your Population Changes notebook that contains the Python population data lists that you copied earlier and delete it by clicking the trash can icon in the top-right corner of the cell. At this point, the notebook’s kernel will still hold the data. To fix this, choose Kernel → Restart Kernel → Clear Outputs of All Cells from the menu. This will reset your notebook. It’ll still contain its content, but not its output:
Now rerun the Population Changes cell that contains your calculate_differences() code and watch as it fails:
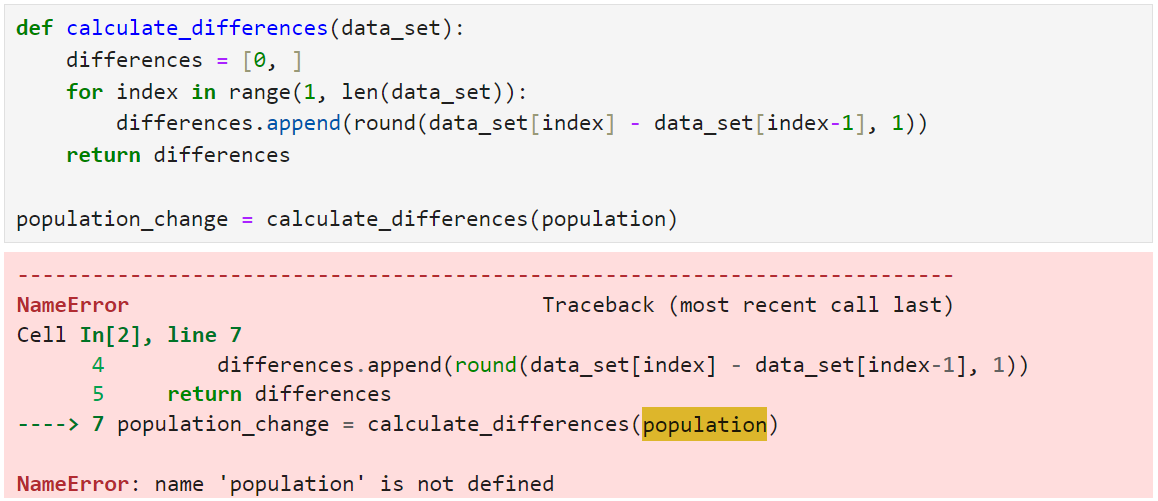
As you can see from the traceback, your code has raised a NameError. This has happened because your code can no longer find the population list that it needs. That’s because the list was removed from the kernel when you cleared it and is now unknown to your code.
To deal with this and make sure you use the same data source as your original Population Data notebook, you must share the kernel that Population Data is using with Population Changes. You can do this by selecting the Population Changes notebook and clicking the Switch kernel button in its top-right corner. From the dropdown, select the Population Data kernel as shown:
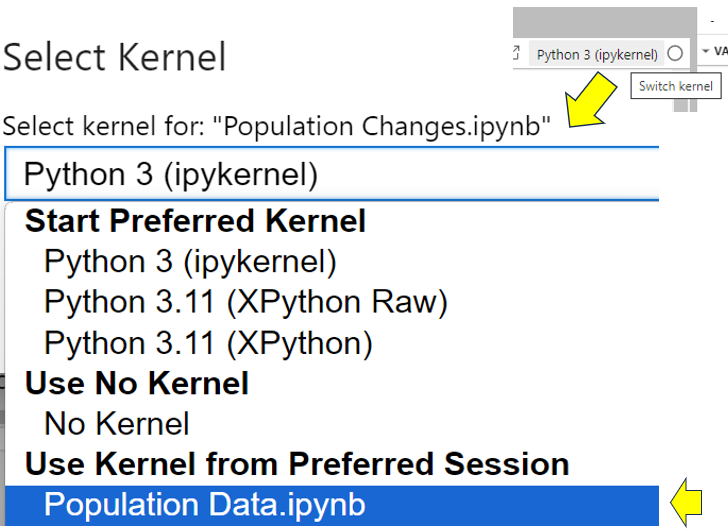
Now when you rerun all the cells in Population Changes, everything works as before. The population list is available once more.
If you like, you can experiment by changing the data in your Population Data notebook and rerunning both notebooks again. If you do, just remember to rerun the cell where you changed your data to update the shared kernel.
Checkpointing Your Notebook
When you work with a Jupyter Notebook, it automatically saves any changes that you make. However, it’s also possible to manually save a notebook. In the language of JupyterLab, this is called checkpointing, and you do it using Ctrl+S in Windows and Linux or Cmd+S in macOS. You can also click the Save and create checkpoint icon as shown:
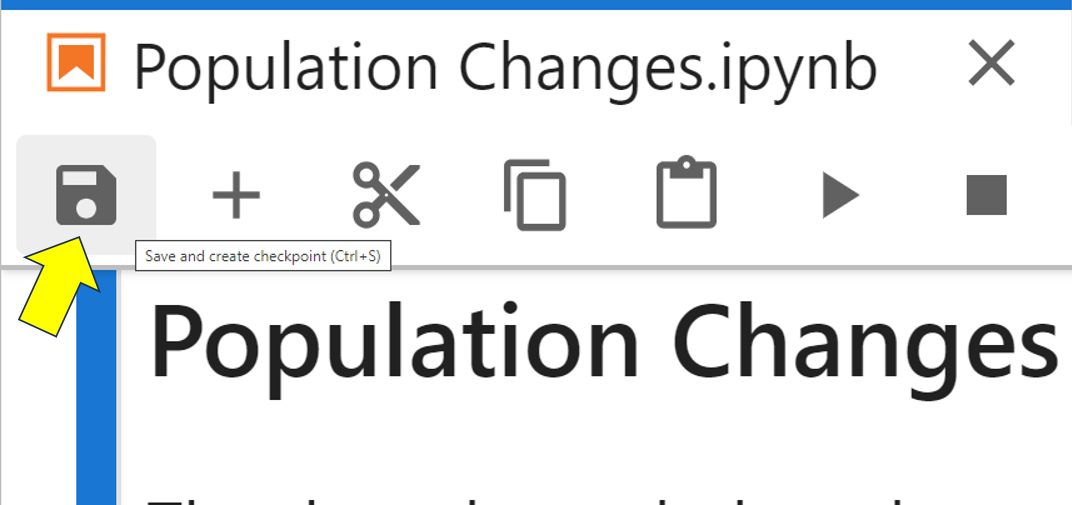
When you first create a new notebook file, JupyterLab creates a file with an .ipynb file extension. In addition, it also creates a second .ipynb checkpoint file. This starts with the same name as the original notebook file, only with -checkpoint appended to it. This checkpoint file gets placed inside a hidden folder named .ipynb_checkpoints in the same folder as your original notebook.
By default, the initial notebook file and its checkpoint will be blank. When you add content to your notebook, the original notebook file gets automatically saved every two minutes. The checkpoint file remains untouched.
If you want to update the checkpoint file as well as the notebook file, then you do so by performing a manual save using Ctrl+S in Windows or Linux, Cmd+S in macOS, or File → Save Notebook from the menu. Doing this overwrites your previous checkpoint. If you then make changes to your notebook, JupyterLab autosaves them every two minutes, but again, the checkpoint is untouched.
Although autosaving is useful, it does mean that any incorrect changes that you make are also automatically saved. This is where checkpoints can help you. It’s possible to roll your notebook back to the last checkpoint by using File → Revert Notebook to Checkpoint….
To test this, add a new raw cell below the last cell of your Population Changes notebook and enter the text As you can see, the population has increased each decade. A raw cell contains completely unformatted and unformattable text. Now manually save the notebook to update its checkpoint:
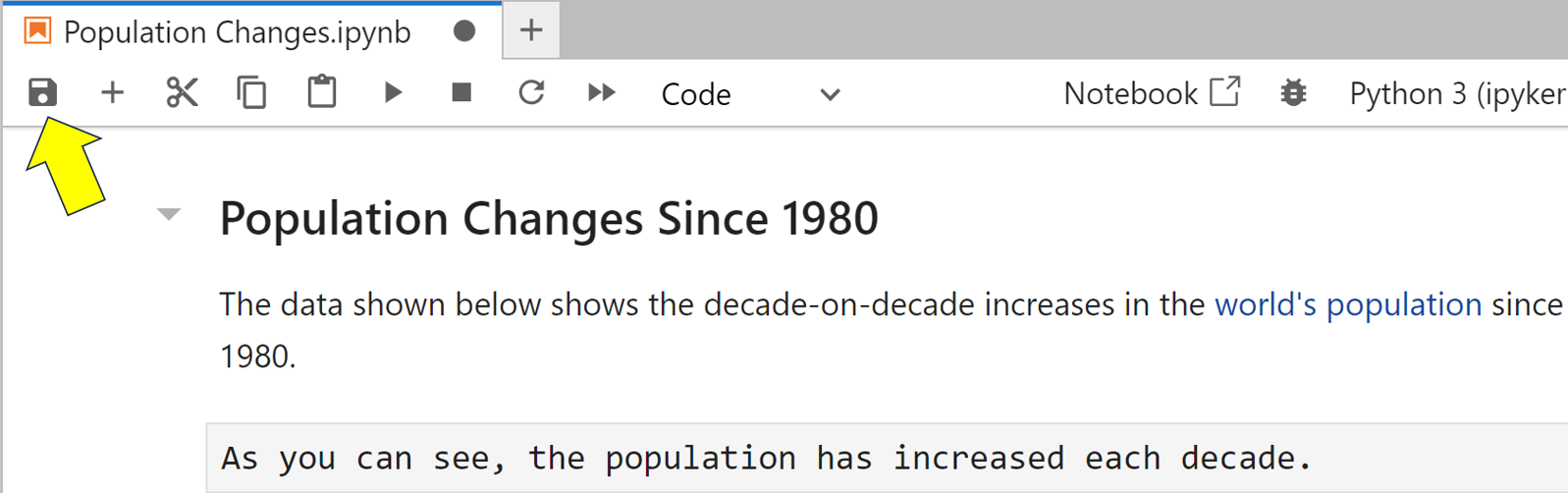
Next double-click on your raw cell to edit it, and change this cell to read As you can see, the population has decreased slightly each decade. Wait at least two minutes then close your notebook without saving it, and shut down the server. Next restart the JupyterLab server once more. When you reopen your notebook, these changes should still be in it. If not, you haven’t waited long enough. Try again, but this time be more patient.
Now you realize you wish you hadn’t made this change. To revert back, select the File → Revert Notebook to Checkpoint menu option. When you’re asked to confirm, click the red Revert button. Now take a look at the cell that you changed:
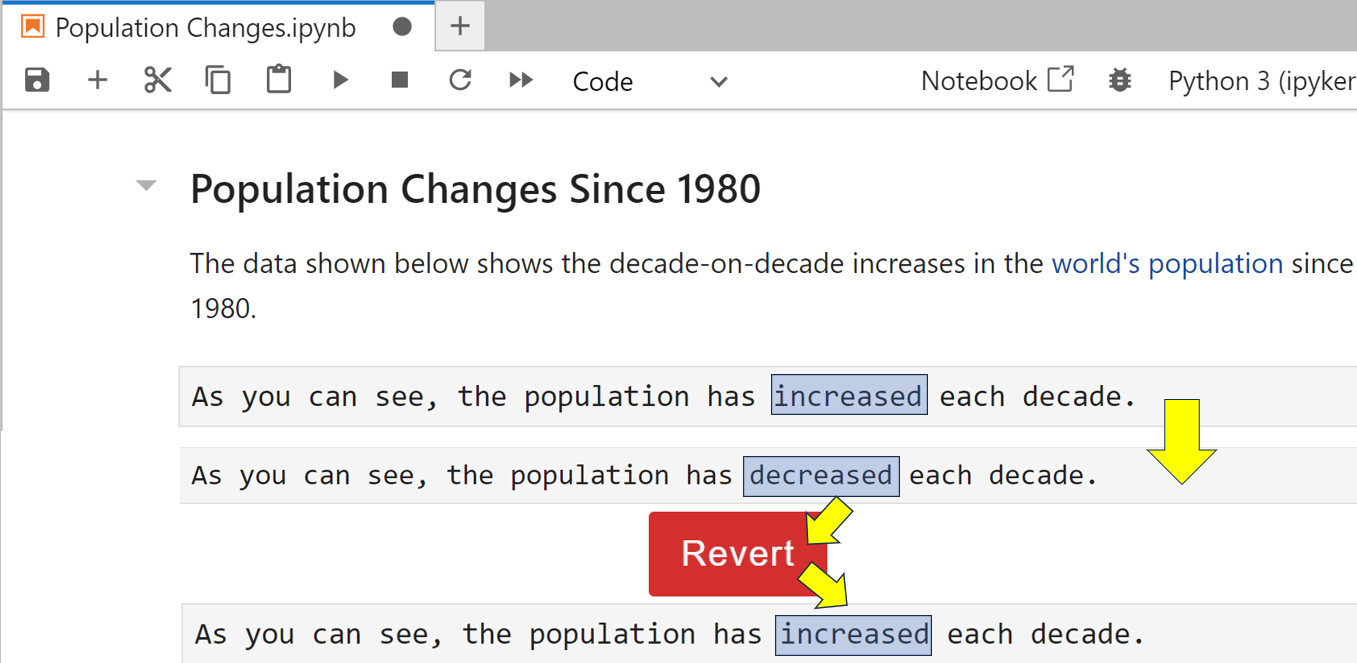
As you can see, decreased has rolled back to increased. Thankfully, your invalid changes are gone.
The checkpointing feature within JupyterLab is fairly primitive. In essence, it offers you the capability to revert to the last manually saved version. You can only revert back to the last checkpoint, and once you’ve done so, you can’t roll back any further or even roll forward again. Before you perform a manual save, make sure your changes are safe for permanent saving. You can’t undo this if they’re not.
If you find that you’re making changes to your notebooks and want to retain earlier versions, the only way within JupyterLab is to create multiple versions of each file by using File → Save Notebook As and giving each a slightly different filename. Obviously, this could still leave you with version control issues.
Note: Although you may be disappointed that JupyterLab’s support for version management is somewhat primitive, there’s a package called nbdime that can improve things. It provides tools that allow you to highlight differences between, or merge together, two notebooks. The package name, nbdime, is in fact short for notebook diff and merge.
Before you move on to some of the other features of JupyterLab, you’ll finish off by learning how to debug notebooks. This is something that you may not have seen, even if you’ve used Jupyter Notebooks before.
Debugging Your Notebook
JupyterLab uses the integrated debugger found within later versions of Jupyter Notebook. The integrated debugger allows you to perform common debugging tasks such as running code one line at a time to verify that it’s working the way you expect it to. You can also monitor the values of variables to make sure they contain what you expect them to.
As an example, you’ll run the debugger against your calculate_differences() function in your Population Changes notebook. Although this function works just fine, you’ll still use it to gain experience in operating the debugger.
To enable the integrated debugger inside your notebook, click the small bug icon in the top-right corner. The bug will turn orange to show that the integrated debugger is switched on:
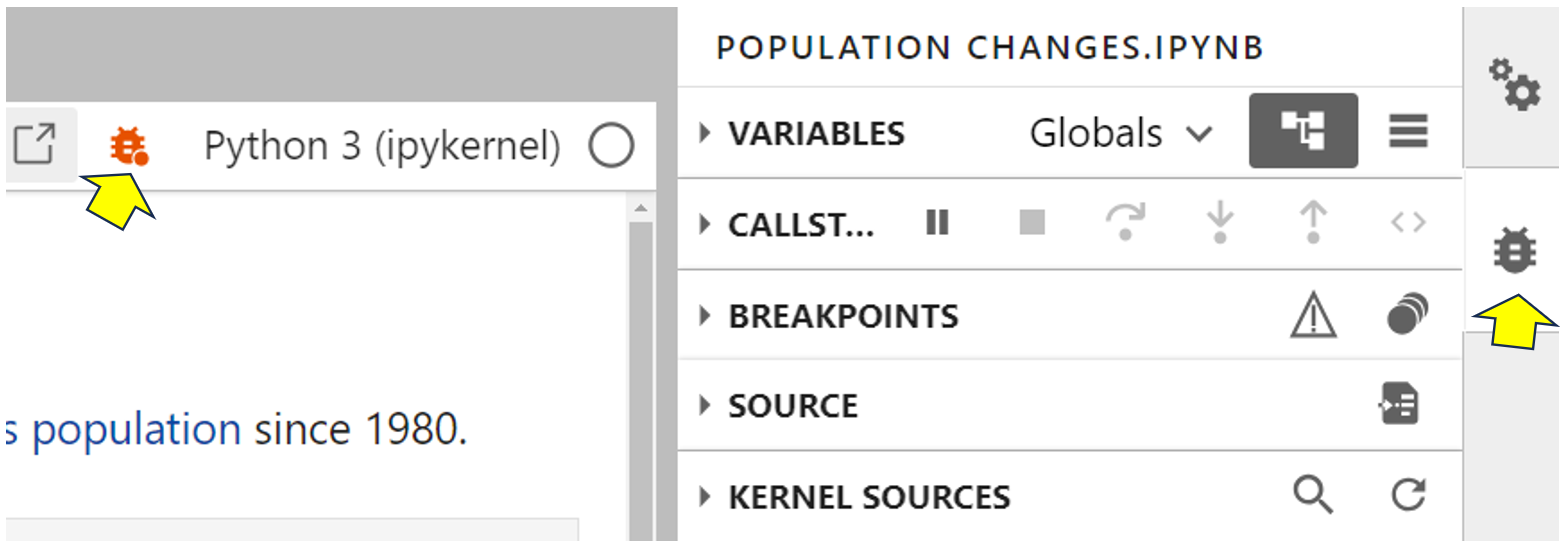
With the debugger on, the debugger tab will be selected at the right of your screen. This tells you what your code is doing while it runs. The debugger contains various sections, including Variables, Callstack, and Breakpoints. Some of them will already be expanded, but they’re all collapsed for convenience here. Also, with the debugger switched on, each code cell gets line numbers. You can use these for reference during debugging.
Start off by running all the cells in your notebook. The quickest way to do this is to choose Run → Run All Cells from the menu. This will allow you to learn how the debugger displays the notebook’s variables.
Expand the variables section of the integrated debugger. Click the Table View icon, and you’ll see the complete set of variables that your notebook’s code uses, along with their current values:

Take a moment to look through the information on display. You can see the content of the various lists, the DataFrame, and even the zipped list that you used to create the DataFrame. This screen is one of the most important when using the debugger.
To see the debugger in action, you first of all clear everything from the notebook’s memory. To do this, you need to select Kernel → Restart Kernel and Clear Outputs From All Cells, then click Restart:
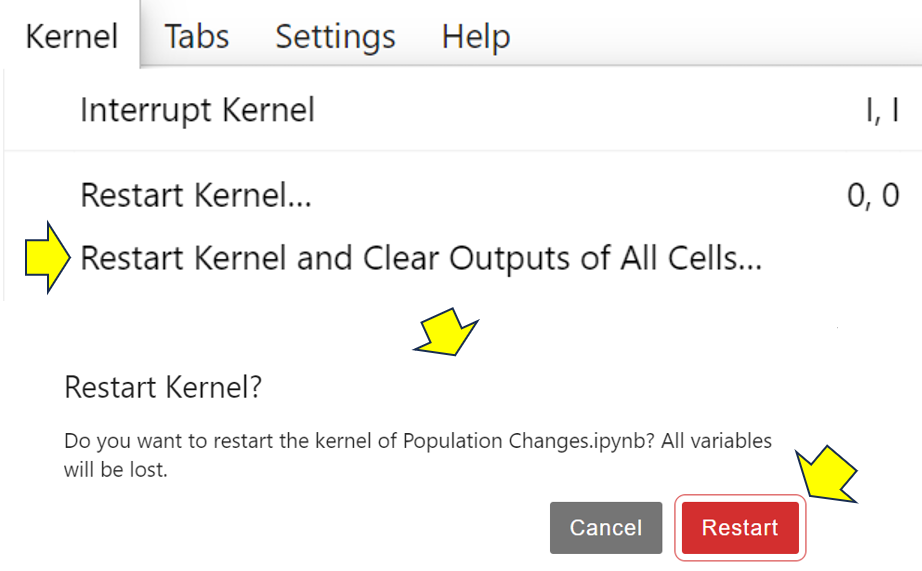
This will clear all outputs and variables from the notebook. If you now look at the list of variables, then you’ll see that you’ve cleared all of them. Each notebook has its own kernel, allowing you to clear each one independently of the others. In restarting the kernel, you’ve also disabled debugging.
Next, to see how to use the integrated debugger, you’ll debug your code. To begin with, enable the debugger once more and arrange the Variables, Callstack, and Breakpoints sections as shown. Also set a breakpoint by clicking on the margin next to your decades list as shown below:
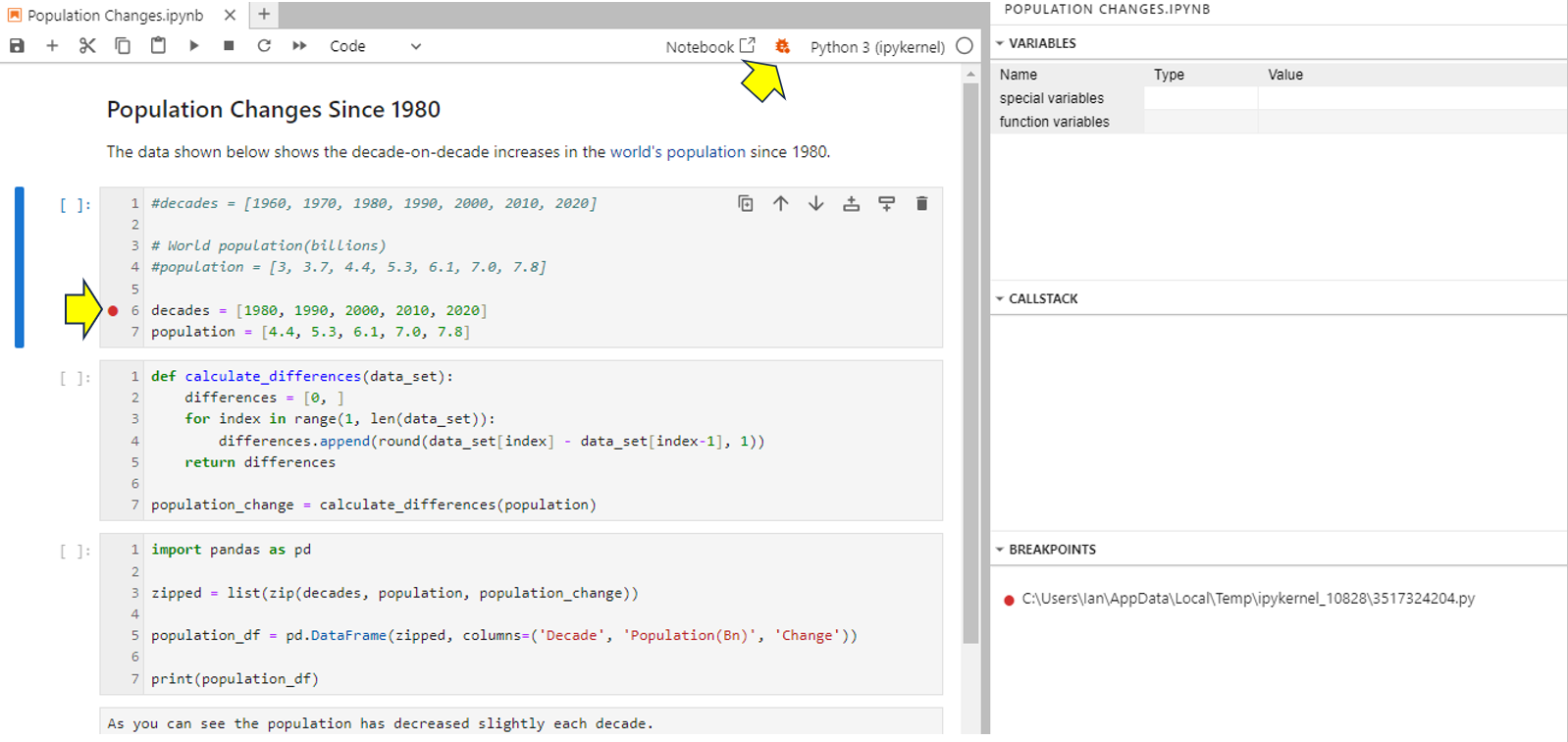
You’ll see the breakpoint added to the Breakpoints section of the debugger. A small red dot appears next to the line to indicate that it has a breakpoint. Your code will run normally up to the breakpoint, and then it’ll enter debug mode. Once in debug mode, you can run the code at your own pace to monitor it. In this case, your entire code will run in debug mode because you’ve created a breakpoint at its first line.
To start debugging, make sure debugging is switched on, and then choose Run → Run All Cells from the menu. Your code will stop at the first breakpoint that it encounters, which will be highlighted:

Your notebook’s code has now paused processing and is awaiting your instruction on how it should proceed next. The choices are displayed visually in the bar above the callstack section of the debug window:
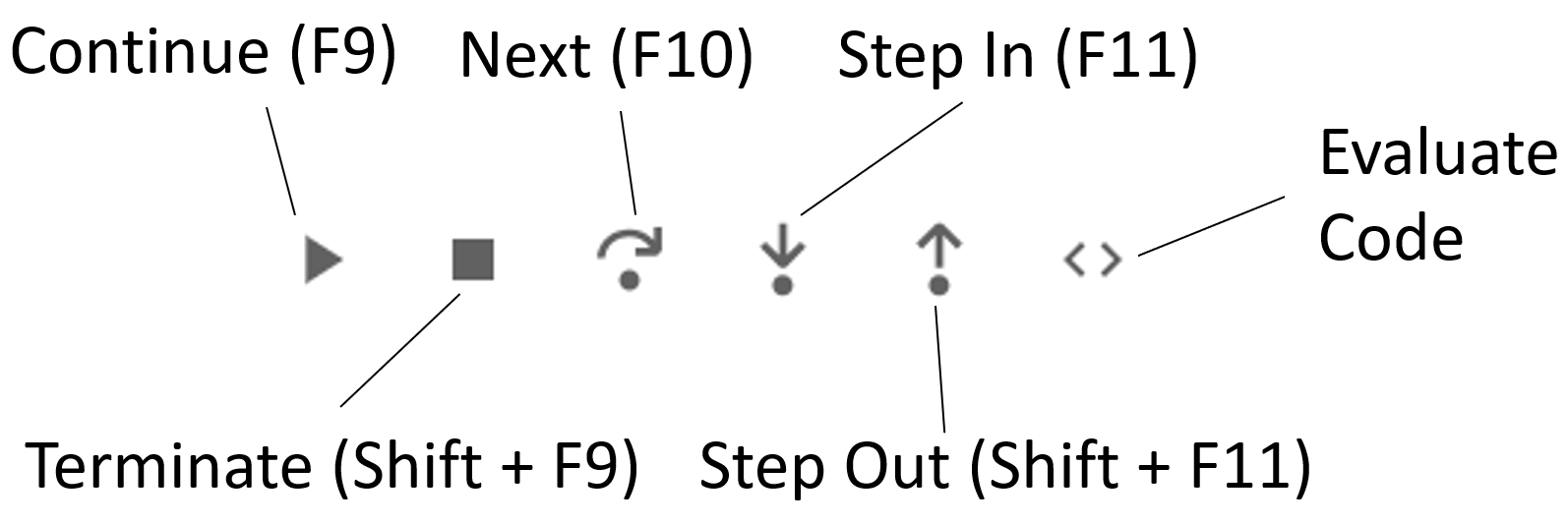
When you click on each of these icons, the program behaves slightly differently. As a starting point, consider the first three options:
-
Continue will cause the rest of your code in the cell to run at normal speed, unless you’ve inserted a second breakpoint, in which case it’ll run normally to that breakpoint and then reenter debug mode.
-
Terminate will immediately stop the code in the cell from running.
-
Next will run the next line of code and then pause to await your further instruction. This is how you run an entire program one line at a time, automatically updating the variables section as each variable is populated. This is one of the most common operations that you use when debugging code.
To understand the debugger better, with the notebook still awaiting you instructions, select Next or tap F10. The code will progress to the next line and pause once more:
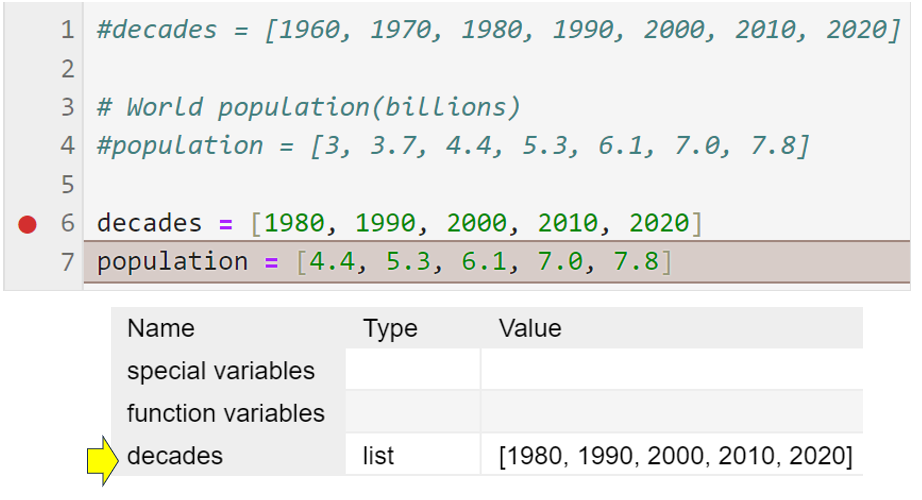
Pay particular attention to the variables section on the right, and you’ll see that the decades variable now has some data assigned to it. This has happened because line 6 ran successfully. By noting this information, you can verify that this line of code is working as expected.
Now tap F10 once more. As you might expect, the population variable now contains data. The program has moved to the top of the next cell containing your calculate_differences() function, and then it stops.
Now tap F10 once more, and control moves to the first line beyond the function. This is because only the line containing the function header has been processed. The function body can only run when your code calls it. In processing the header, your code now knows the function exists.
At this point, you have a choice to make. If you tap F10 again, you assign the population_variable its data, and the program ends. You may have expected the debugger to enter your calculate_differences() function and run through it. In fact, the function did run, but it did so at full speed. Selecting F10 runs a complete line of code at full speed, including any calls to functions. This is why the Next icon has an arrow jumping over a dot.
You can verify that the function has indeed run because if you look at the list of variables, you’ll see that population_change now has content:
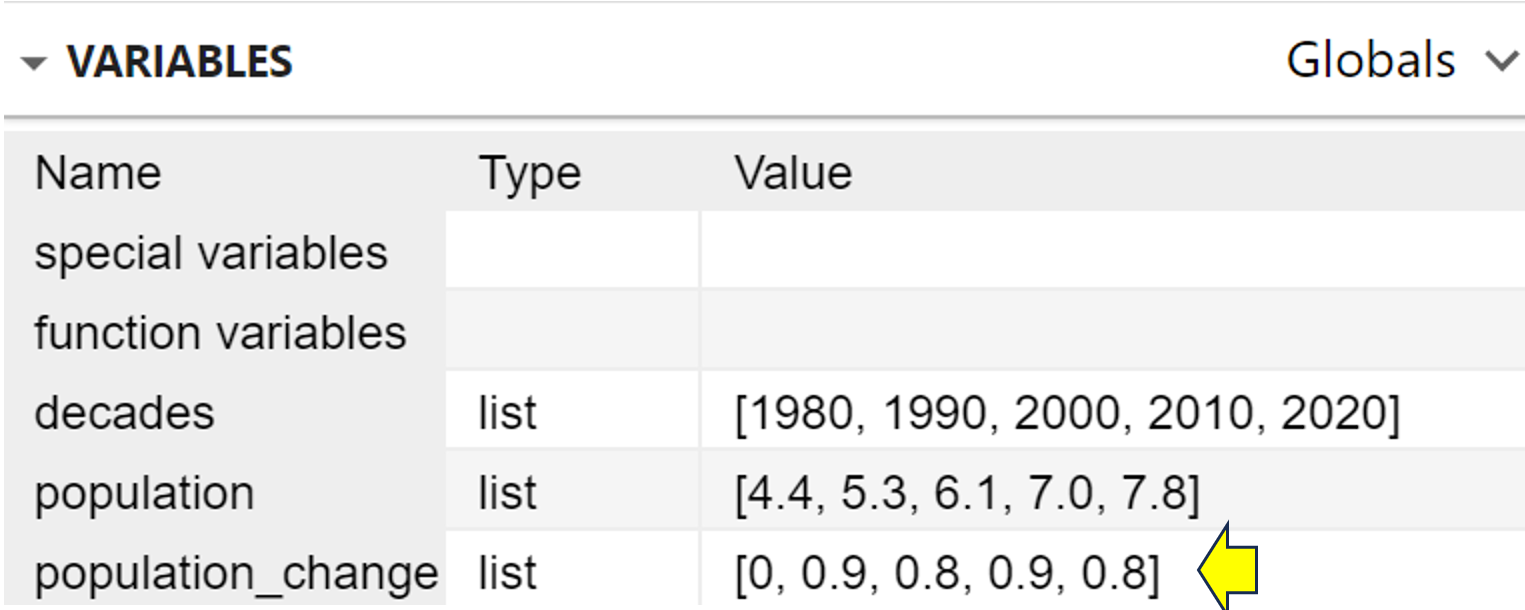
As you can see, the population changes now show up in the population_change list.
Of course, there will be times when you need to run the debugger through the function code. To do this, tap the Terminate button in the callstack section or use Shift+F9. This will stop the debugger. Now restart the debugger and repeat the previous instructions until your notebook has stopped at the function call line. You’ll have tapped F10 three times to get there.
This time, instead of using F10, tap F11 or choose the Step In option in the callstack section instead. As its name and icon suggest, this will move into the code by entering the function’s body:
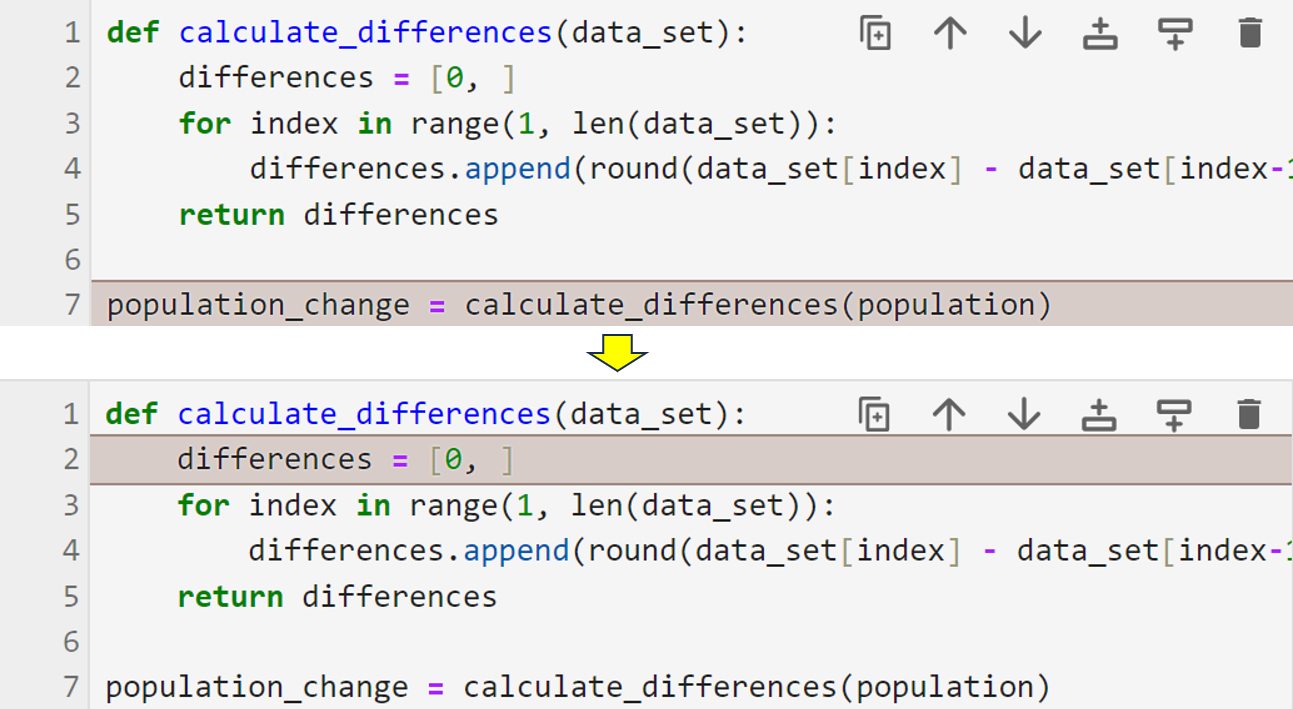
As you can see, the debugger now allows you to step through the function’s code, and it has stopped at the first line of the function’s body. Notice that the data_set variable, which only exists within the function, now contains data. Also, the callstack tells you that program control has left line 7 in the main module and entered line 2, which is in the calculate_differences() function. This information allows you to monitor the program’s flow.
Tap F10 a few times more until you’ve completed at least one iteration of the for loop. Keep an eye on the variables section, and you’ll see the variables change as the loop iterates. Again, you could run through the entire function one line at a time if you wanted to.
Once you’re satisfied that your function is working correctly, you can tap the Step Out button or use Shift+F11 to run the remainder of the function at normal speed and jump back to line 7, where you called it. Tap F10 once more, and this final line of code will run, completing the cell.
If you have the debugger switched on and don’t set any breakpoints, then running the code causes it to to run at normal speed. However, the debug window will still contain the value of every variable. This can be useful if you want to see what values your program is storing without printing.
Finally, you can remove an individual breakpoint by clicking on its red circle. The quickest way to switch all breakpoints off is by clicking the red bug symbol to switch debugging off and then clicking it again to switch debugging back on again.
While notebooks are by far the most commonly used component of JupyterLab, they’re not the only one. You’ll now turn your attention to some of its other interesting features.
Using the Markdown Editor
When you write a program that’s intended for others to use, it’s important that you document it so that your users understand it and other developers can maintain it. Documentation also serves as a future reference to allow you to remember how the program works.
Although you can write documentation using a variety of tools, a common one is the Markdown language. Markdown is a user-friendly markup language that allows you to create editable formatted documents. JupyterLab provides a Markdown editor and viewer for you. However, unlike most others, JupyterLab’s version also allows you to run any code snippets that you place within your Markdown files.
It’s time for you to get the heads-up on Markdown.
Creating and Previewing a Markdown Document
To create a new Markdown file, make sure the Launcher page is displayed. If it’s not, then click any of the + symbols next to the tabs of any existing open content, and a new Launcher will appear. Then click the purple Markdown File icon:

You’ll now be looking at a blank Markdown file. Right-click its tab and rename it Handling Exceptions.md. Now it’s time to add content.
In this example, you’ll provide a short note that explains how Python can handle exceptions. This will allow you to practice some basic formatting. In addition, you’ll add some code and run it from within the Markdown file.
While Markdown isn’t terribly complicated, it’s still helpful to see what the formatted output will look like. Jupyter allows you to do this as you type the Markdown by displaying the Markdown preview. The preview automatically synchronizes with your Markdown file and lets you see what the final product will look like as you write it.
To open a Markdown preview, right-click on the blank Markdown file and choose Show Markdown Preview:
As you can see, a second preview window appears to the right of the Markdown file. It’ll be blank because you haven’t added any content to the Markdown file. You’ll fix this now and see another example of JupyterLab’s synchronization abilities. You decide to add the following to your Markdown file:
# Dealing With Exceptions
## What is an Exception?
An **Exception** gets **raised** when code encounters an occasional,
but not unexpected, error. Although exceptions are an unavoidable
part of software, because you are aware that exceptions may occur,
you should write code to deal with or **handle** them.
Unhandled exceptions will cause a program to crash.
## How Do You Handle Them?
You implement [*exception handling*](https://realpython.com/python-exceptions/)
to handle exceptions. In its most basic form, this provides both a *try*
and one or more *except* blocks:
* The *try* block contains the code you wish to monitor for exceptions.
Any exceptions raised within *try* will be eligible for handling.
* One or more *except* blocks are where you define code that will run
when exceptions occur and handle them. This is how you stop the exception
from crashing the code.
## What Are Some Common Exceptions
The Python language supports more than sixty common exceptions.
Two of the more common are:
| Exception | Cause |
|:----------------------|:--------------------------------------------|
| **ZeroDivisionError** | Raised when you attempt to divide by zero |
| **ValueError** | Raised when you pass an inappropriate value |
## Example
```python
try:
first_number = float(input("Enter your first number"))
second_number = float(input("Enter your second number"))
print(f"{first_number} / {second_number} = {first_number / second_number}")
except ZeroDivisionError:
print("You can't divide by zero")
except ValueError:
print("You must supply a number")
``` .
Don’t worry if some of these characters look odd to you. You’ll learn what they mean below. In the meantime, if you’ve typed everything in correctly, then your Markdown and preview will look like this:

If you notice any differences between your output and what’s shown above, then go back and check your Markdown source carefully.
Note: The Markdown preview that you generated above is actually a view of the original Markdown file. If you change your Markdown file, then the Markdown preview will also change.
Here’s how you used Markdown symbols:
- To create headings, you used one or more
#characters. A single#produces a heading, while##produces a subheading. - To make your text bold, you surrounded it with
**. To italicize your text, you surrounded it with*. - To create hyperlinks, you enclosed the link text in
[]and the URL in(). In your Markdown, clicking the exception handling link text will take your readers to a tutorial on the subject. - To create the table, you separated its data with
|and used:-to specify left alignment. - To define a code block, you wrote its code between triple backticks (```) followed by the word
python, and you put another set of triple backticks at the end of the code block. This not only formats it neatly but also allows you to run the code by clicking inside the box.
As you can see, you can quickly create a neatly formatted document using a few common pieces of Markdown syntax. These will most likely meet most of your needs, but more involved formatting options are available if you need them. However, writing Markdown isn’t the only thing you can do with your Markdown files in JupyterLab.
Running Code Embedded Within a Markdown File
Although basic Markdown is good for providing information about program code, JupyterLab goes a step further and allows you to run the code embedded within it. This is a great way of ensuring that your code does what you expect it to.
If you want to run your code from a code block, then you need to create a console for it to run in. To do this, right-click anywhere in your Markdown file and choose Create Console for Editor from the menu. You must then choose a kernel. Unless you need to access data stored in an existing kernel, selecting Python3 (ipykernel) will link in the new kernel to manage the running of the code in the new console window that has appeared:
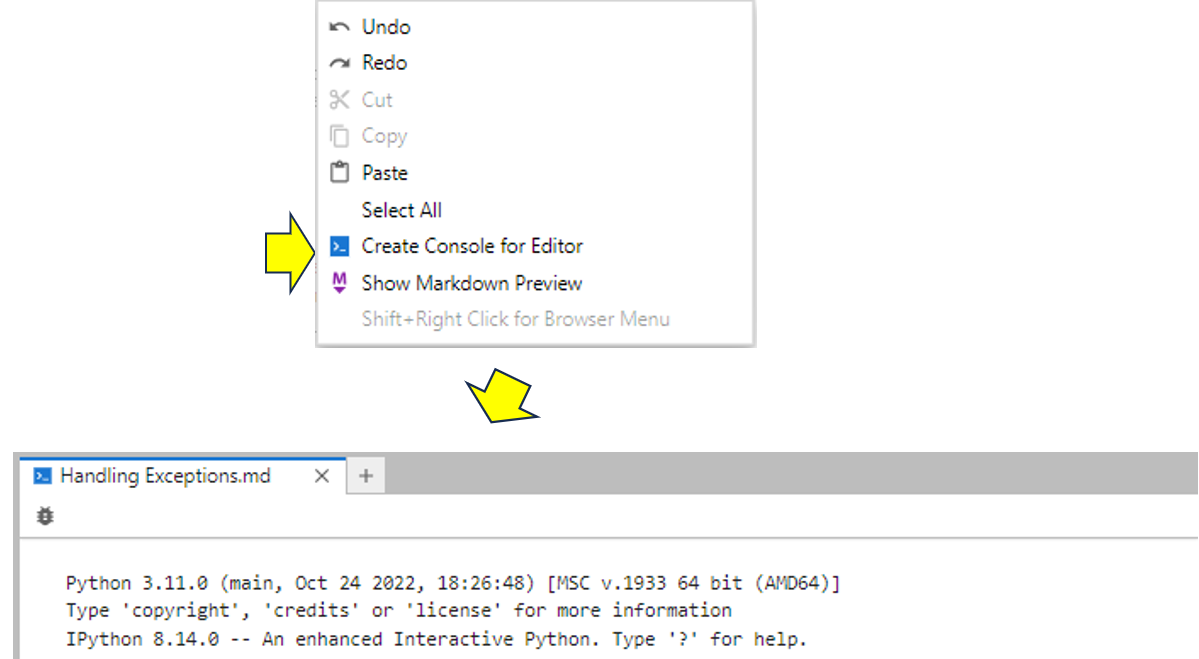
Now that you’ve created a console and linked a kernel to your Markdown file, you can run the code. To actually run the code, you put your cursor anywhere inside the Python block—for example, to the left of the first except keyword—and then tap Shift+Enter to run it:
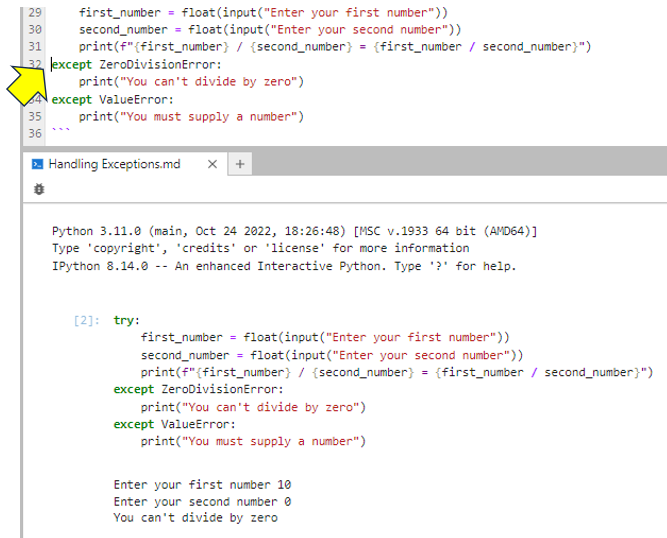
As you can see, the code gets passed to the console and runs. In this test case, the zero that you entered as the second input caused your code to raise and handle a ZeroDivisionError. Feel free to run the cell once more, but this time, enter "ten" as the first input and see how your code reacts.
One of the other cool things that JupyterLab allows you to do is to run small snippets of your code. This can be useful if you’re analyzing a specific part of it. To do this, select the lines of code that you want to run and tap Shift+Enter to run that portion:
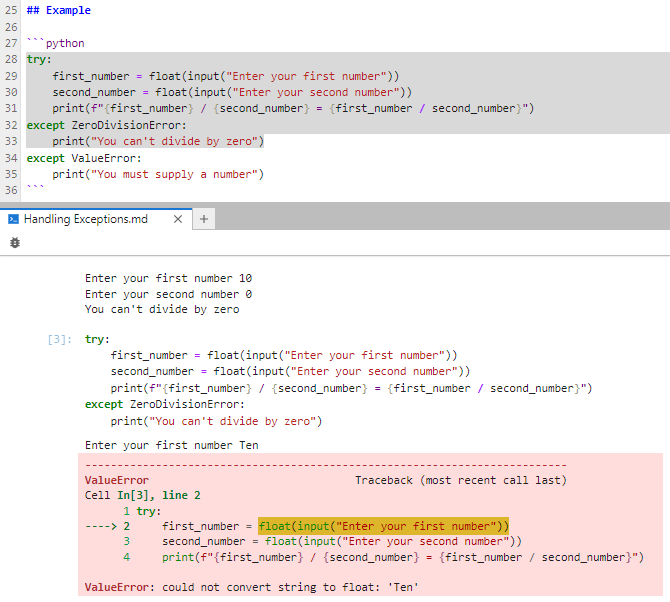
This time, you only selected lines 28 through 33. When you tapped Shift+Enter, only those lines ran. When you entered an invalid value for one of the numbers, a ValueError got raised but remained unhandled because you didn’t select the handler for it in lines 34 and 35.
Although this is a useful feature, be careful when selecting small parts of your code. You need to make sure that you select enough to form a complete program. For example, selecting lines 32 and 33 alone will cause a crash because the selected code is a syntax error by itself.
Note: You can also run embedded code from within plain text files and .py files by linking a console to them. Isn’t that a great time-saver?
As you can see, JupyterLab allows you to write Markdown files that contain code that you can document and run. So not only can you view your Markdown the way you want your readers to see it, but by attaching a console to your Markdown file, you can test your code as well. That means you can avoid creating Markdown documents with incorrect code.
Using a Table of Contents With a Markdown File
As a convenience, if you have a long Markdown file, you can jump to specific sections within it by generating a table of contents. To do this, click the Table of Contents icon as shown:
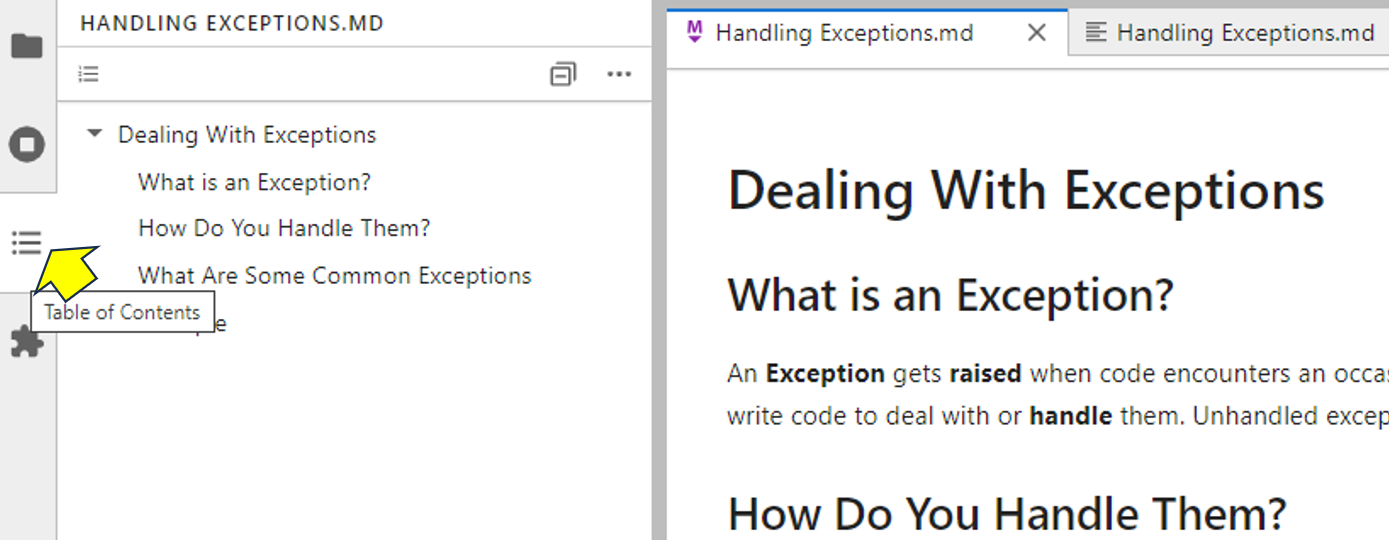
If you select the Markdown file preview then click any of the table of contents entries, then your Markdown preview file will jump to that heading. Similarly, if you select the Markdown file first, then it’ll jump to the position that you select from the table of contents.
Managing and Viewing Different Files
JupyterLab contains its own file browser that enables you to perform common file management tasks plus view and edit common file types. The file browser is always available when you select its icon as shown:
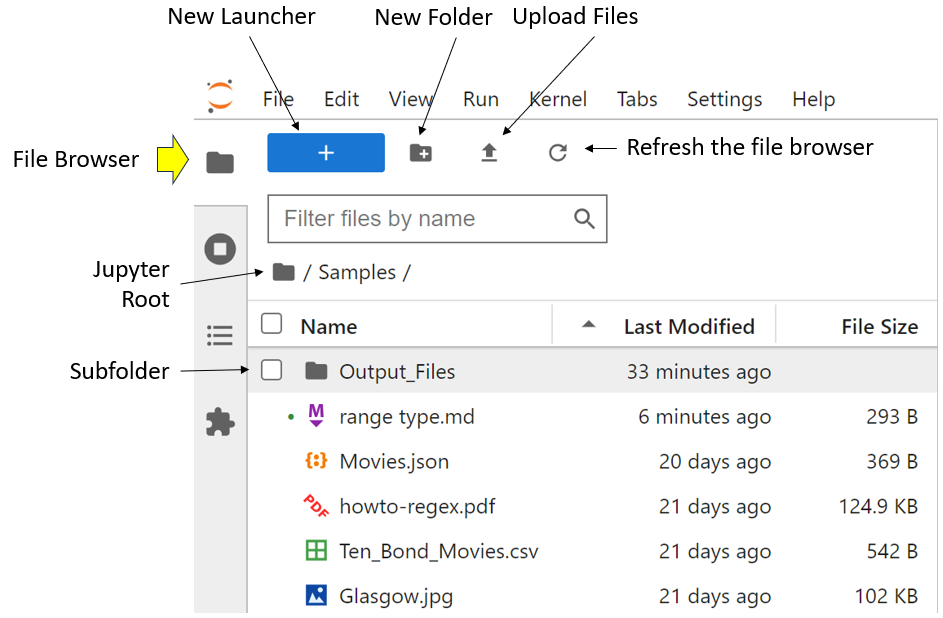
The file browser tools available to you are:
-
New Launcher, which opens a new Launcher page to allow you to access the various Jupyter components.
-
New Folder, which allows you to create a new subfolder within the current folder. In the screenshot above, you created a new
Output_Filessubfolder. -
Upload Files, which allows you to upload files into the current folder. This is really designed for networked systems where your JupyterLab server is running on a computer elsewhere on a network. If you’re running both the client and its server on the same computer, then you can upload files into your current folder from anywhere on your local computer.
-
Refresh the file browser makes sure that the list of files displayed in the file browser is up to date. This is also designed for networked environments where remote changes may not immediately show up in the Jupyter interface on your local machine.
-
Filter files by name allows you to limit the files that are displayed. This is very useful if you have lots of files and are looking for a specific file or similar files. For example, typing
ipynbinto this field will display only your Jupyter Notebook files. -
Jupyter Root will display the files in the folder where you started JupyterLab. As far as JupyterLab is concerned, this is the top of the file system. It’s not possible to access files from any folder above the Jupyter root folder from the file browser, unless you upload files as discussed earlier.
The files that you see listed in the screenshot are in your Samples folder. You can access the folder by double-clicking on it. To access a parent folder, click on its breadcrumb to the right of the root icon. As you can see, navigating through the file system is quite straightforward.
Note: You may have also noticed a green dot next to the range type.md file in the above screenshot. This means there’s a running kernel associated with the file. Why not open your copy of this file from the Samples folder then see if you can replicate the dot with your copy?
You can further manage individual files by right-clicking them. The resulting pop-up menu allows you to perform common tasks such as deleting, renaming, and duplicating your files. You can even create new notebooks from here as well. Strangely, you can’t create Markdown.
To view files, double-click them:
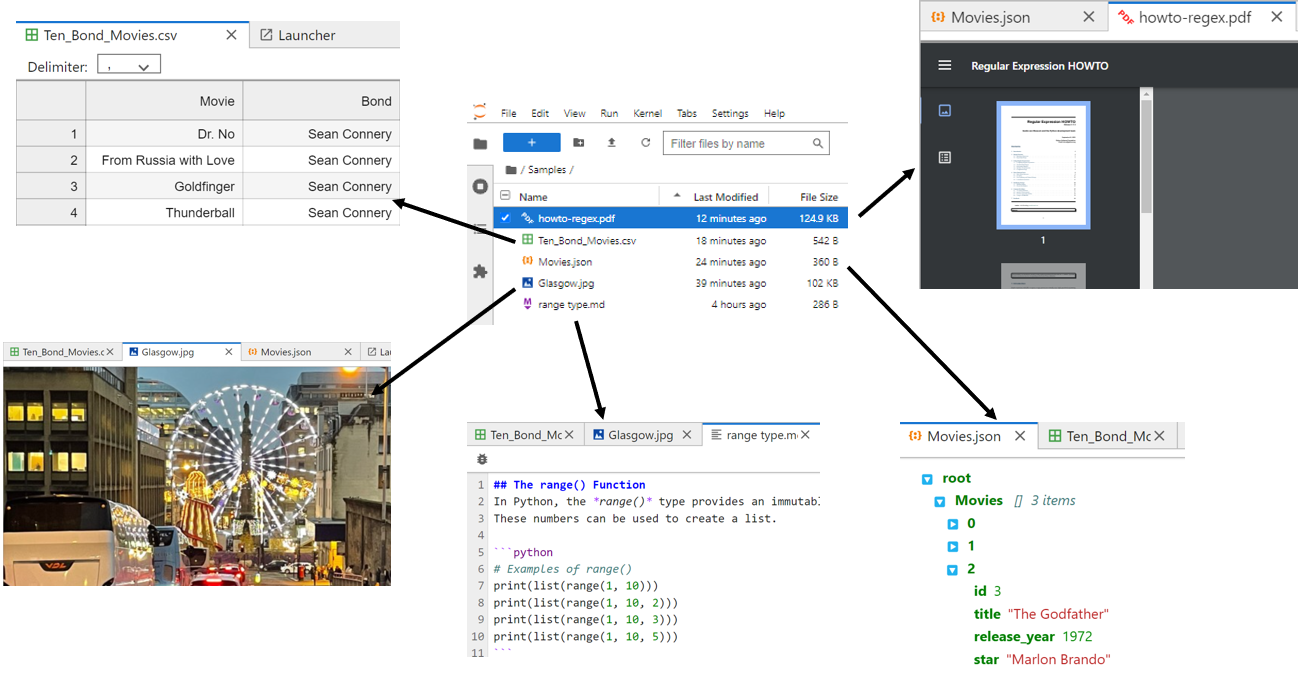
After you double-click, your file opens in its own read-only tabbed window. In the screenshot above, you’ve managed to successfully open .pdf, .csv, .json, .jpg, and .md files for viewing. You can edit some files by right-clicking on them in the file browser and choosing Open With → Editor. Feel free to open some of the files in your Samples folder.
JavaScript Object Notation, or JSON, is an open standard file and data interchange format for storing data and passing it between different systems. Although you can work directly with JSON files in Python, you can also view and edit them in JupyterLab. But there is a caveat.
If you need to have one JSON file open for editing and another for viewing in its formatted form, then creating a simple view won’t work. If you have a JSON file opened for editing and create a new view of it, then you end up with two views for editing. To overcome this, you must open the file twice: first for editing and again for reading. Thankfully, JupyterLab will still create two views on the same file meaning both will be synchronized.
The screenshot below shows the Movies.json file from your Samples folder, which you opened by double-clicking it in your file browser. By default, this opens it for viewing. Now if you right-click on the file’s name in the file browser and choose Open With → Editor, then you’ll open a second copy for editing. If you drag the tab of the second file to the right side of the screen, then you’ll see both simultaneously:
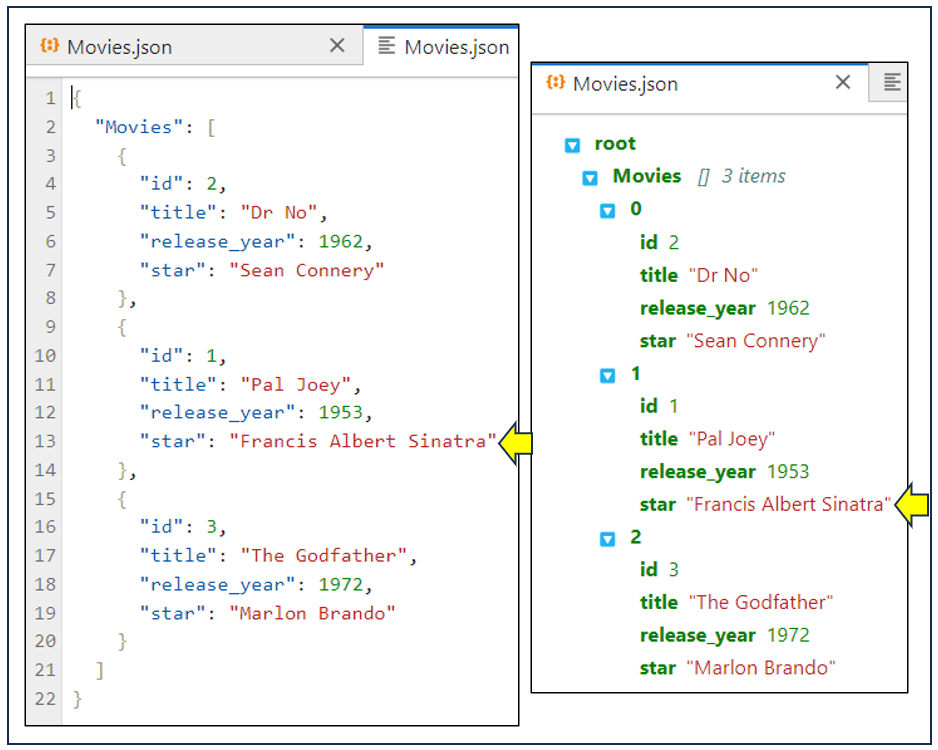
As you can see, the left-hand side of the screenshot shows a file available to you for editing, while the right-hand side shows the same file available for read-only viewing.
Finally, suppose you decide to change the highlighted text:
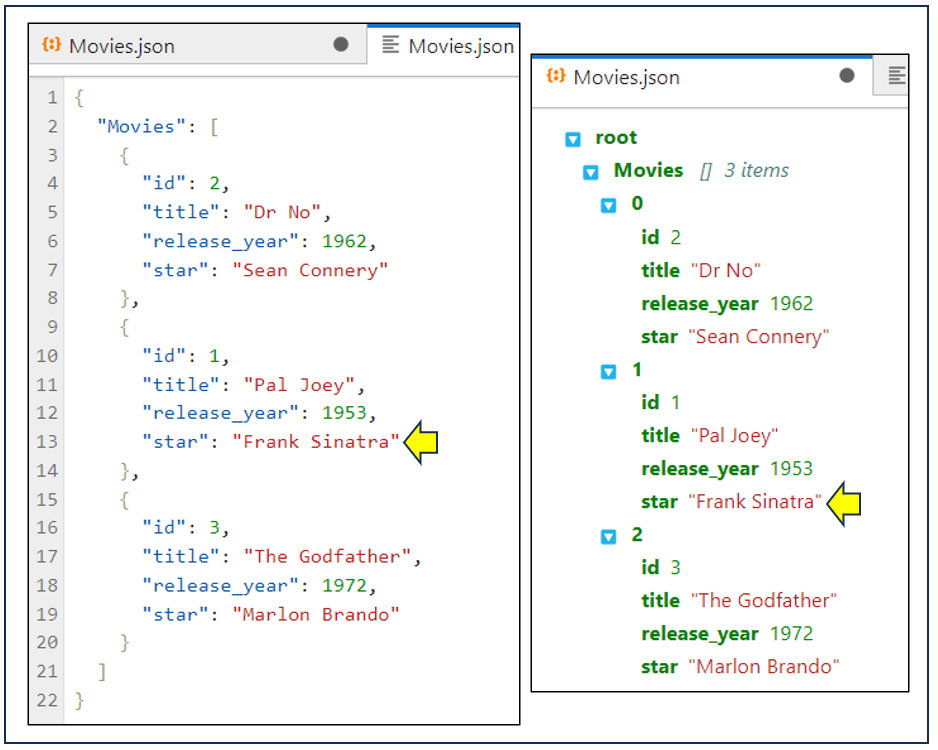
When you make a change to the editable version on the left, then the read-only version on the right immediately reflects it. This isn’t a huge surprise. You’re looking at the same thing, after all.
The ability to view files directly not only gives you another great time-saver but also helps you quickly view any files that your code needs or creates. Having each of your files open in its own tab also means that viewing them is only a mouse click away.
Using Your Operating System Without Leaving Jupyter
JupyterLab allows you to directly access your operating system’s command-line environment. To do this, you click the Terminal button as shown:

In Windows, this opens PowerShell. In Linux, it’s usually a Bash shell, while macOS usually uses a Zshell. Once you have a command line, you can then enter the operating system commands that you need. Just remember that you’re running the commands with the same privileges as those that you’ve used to access JupyterLab, so unless you run with administrator privileges, you won’t be able to run all commands.
The screenshot below shows a Windows PowerShell terminal that you’ve accessed from within JupyterLab:
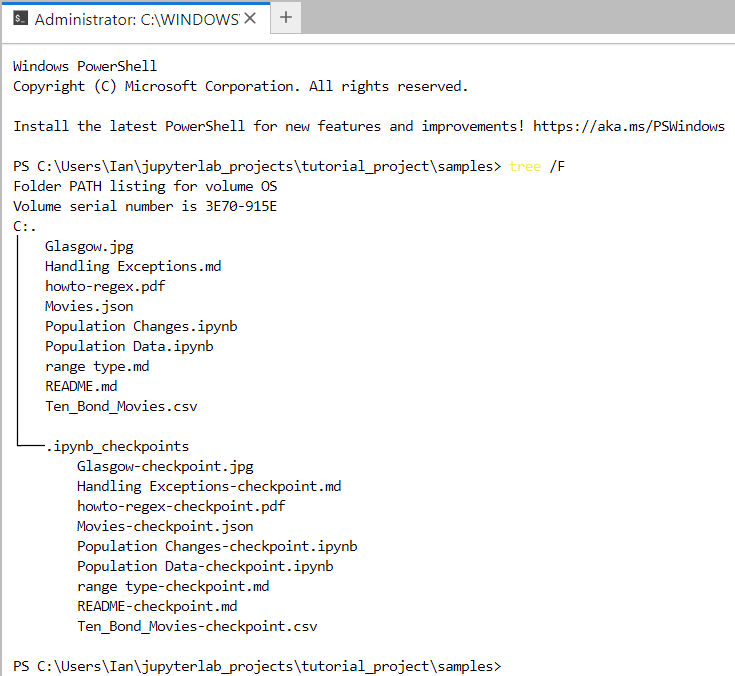
Here you’ve inspected the contents of the Samples folder using the tree command. As you can see, there are nine files plus one subfolder containing checkpoint information about some of your files. This folder is actually hidden, and you don’t need to worry about its content.
The terminal is useful if you need to use the command line to install a module.
Note: When you start a terminal, it runs within the same Python environment where JupyterLab is running. So if you’re running JupyterLab in a virtual environment, then all the packages that you install with this terminal will install into your virtual environment. This means that they’ll be available to your notebooks, consoles, and other terminals, but they won’t interfere with any Python installations outside of the virtual environment.
You can also use the terminal to run additional Python code and keep it separate from the code that you’re running elsewhere in JupyterLab. Each time you open a terminal, it gets its own kernel, meaning you can have multiple terminals and commands running without interfering with each other.
Using Other Tools
At this stage, you’ve covered the main tools in JupyterLab. However, there are some more available. Take a look at the Other section, and you’ll see that you’re not quite finished yet:
Clicking Text File will open a text editor that allows you to create plain text files. JupyterLab allows you to create multiple views of them and, by attaching a console to them, run any code within them.
Clicking Python file allows you to create a file with an extension of .py. In essence, this is a text file, but its content will be color coded to highlight the Python keywords that you’re using. As with text files, you can create multiple views of these files and run any code within them by attaching a console. Of course, you can also run them as Python scripts using python filename.py.
Clicking Python 3 allows you to create a stand-alone console:

This uses IPython, which provides an environment like the Python REPL, where you can type code in directly or drag and drop it from a notebook or Markdown file, and then run it. This code has its own kernel process, so it won’t interfere with anything else that you have running elsewhere in JupyterLab. The screenshot below shows some code inserted into the lower part of a console:
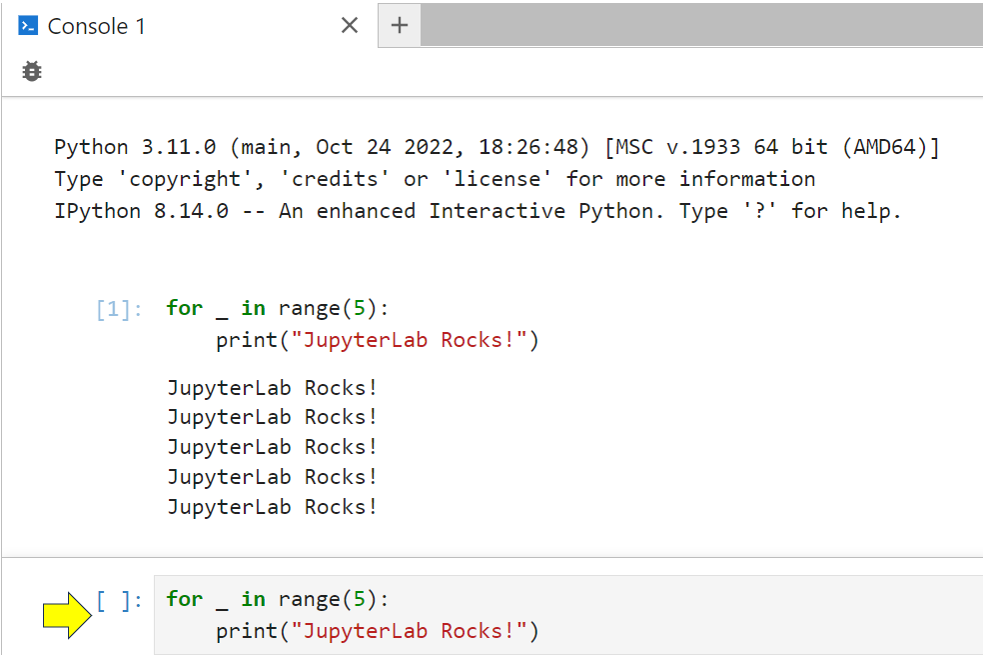
All you need to do to run your code in a console is tap Shift+Enter. As you can see, the output shows up in the upper part of the console.
FAQs
You now have some experience with many of the common tools and techniques available within JupyterLab. You’ve covered a lot of ground, but here, you’ll find a few questions and answers that sum up the most important concepts that you’ve covered in this tutorial.
You can use these questions to check your understanding or to recap and solidify what you’ve just learned. After each question, you’ll find a brief explanation hidden in a collapsible section. Click the Show/Hide toggle to reveal the answer. Time to dive in!
JupyterLab provides you with several tools including Jupyter Notebooks, a Markdown editor, and even a text editor. You can display a wide range of files neatly and even run the Python code embedded within them. You can also move or share data between notebooks. It even offers debugging features.
JupyterLab is a browser-based interface that will assist you in documenting and sharing your research, teaching, and learning activities. It’s a very popular tool for data analysis. Its core tool is Jupyter Notebook, but JupyterLab enhances the functionality of your notebooks by integrating them with other JupyterLab tools.
The designers of JupyterLab are keen for you to use keyboard shortcuts, so they’ve made the complete set accessible using Ctrl+Shift+H in Windows and Linux, Cmd+Shift+H in macOS, or the Help → Show Keyboard Shortcuts menu option. Several menu items also contain keyboard shortcuts, as do the various tooltips that appear when you hover your mouse over an item. Throughout this tutorial, you’ve learned several of the most common keyboard shortcuts.
The kernel controls the link between code within a JupyterLab file and its runtime environment. Kernels can also access a program’s data, so by sharing a kernel between notebooks, you can share one notebook’s data with another.
When you close a Jupyter Notebook, you don’t close its kernel. This is because other notebooks may also be sharing it. Leaving a kernel running is usually okay, but if you want to close it, then you can select it, right-click, and choose Shut Down Kernel from the pop-up menu.
JupyterLab allows you to display multiple notebooks, move content and share code between them, and view different parts of them simultaneously. You can even debug their code. It also provides tools for working with Markdown files, text files, and several other common formats, as well as the ability to run code embedded within them.
JupyterLab is part of Project Jupyter. This is an evolving project, so you’re encouraged to keep up with the latest developments and improvements. A good starting point for that is the official documentation. Why not get involved in the JupyterLab community and help make your favorite program even better?
If you have any comments or want to share your use of JupyterLab, feel free to reach out in the comments section below.
Free Bonus: Click here to download notebooks and files that you can play with in JupyterLab.







