
Sorting strings in Python is something that you can almost take for granted if you do it all the time. Yet, it can become surprisingly tricky considering all the edge cases lurking in the vast Unicode standard. Understanding Unicode isn’t an easy feat, so prepare yourself for a whirlwind tour of surprising edge cases and effective ways of dealing with them.
Note: In this tutorial, you’ll often use the term Unicode string to mean any string with non-Latin letters and characters like emoji. However, strings consisting of Basic Latin letters also fall into this category because the underlying ASCII table is a subset of Unicode.
Python pioneered and popularized a robust sorting algorithm called Timsort, which now ships with several major programming languages, including Java, Rust, and Swift. When you call sorted() or list.sort(), Python uses this algorithm under the surface to rearrange elements. As long as your sequence contains comparable elements of compatible types, then you can sort numbers, strings, and other data types in the expected order:
>>> math_constants = [6.28, 2.72, 3.14]
>>> sorted(math_constants)
[2.72, 3.14, 6.28]
>>> fruits = ["orange", "banana", "lemon", "apple"]
>>> sorted(fruits)
['apple', 'banana', 'lemon', 'orange']
>>> people = [("John", "Doe"), ("Anna", "Smith")]
>>> sorted(people)
[('Anna', 'Smith'), ('John', 'Doe')]
Unless you specify otherwise, Python sorts these elements by value in ascending order, comparing them pairwise. Each pair must contain elements that are comparable using either the less than (<) or greater than (>) operator. Sometimes, these comparison operators are undefined for specific data types like complex numbers or between two distinct types. In these cases, a comparison will fail:
>>> 4 + 2j < 2 + 4j
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'complex' and 'complex'
>>> 3.14 < "orange"
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: '<' not supported between instances of 'float' and 'str'
In most cases, you’ll be working with homogeneous sequences comprising elements of the same type, so you’ll rarely run into this problem in the wild. However, things may start to fall apart once you throw strings with non-Latin characters into the mix, such as letters with diacritics or accents:
>>> polish_names = ["Zbigniew", "Ludmiła", "Żaneta", "Łukasz"]
>>> sorted(polish_names)
['Ludmiła', 'Zbigniew', 'Łukasz', 'Żaneta']
In this example, you run into a common challenge associated with sorting strings. When a string contains characters whose ordinal values extend beyond the usual ASCII range, then you might get unexpected results like what you have here. The name Łukasz ends up after Zbigniew, even though the letter Ł (pronounced like a w sound in English) occurs earlier than Z in the Polish alphabet. Why’s that?
Python sorts strings lexicographically by comparing Unicode code points of the individual characters from left to right. It just so happens that the letter Ł has a higher ordinal value in Unicode than the letter Z, making it greater than any of the Latin letters:
>>> ord("Ł")
321
>>> ord("Z")
90
>>> any("Ł" < letter for letter in "ABCDEFGHIJKLMNOPQRSTUVWXYZ")
False
Code points are unique yet arbitrary identifiers of Unicode characters, and they don’t inherently agree with the alphabetical order of spoken languages. So, lexicographic sorting won’t be appropriate for languages other than English.
Different cultures follow different rules for sorting strings, even when they share the same alphabet or parts of it with other cultures. For example, the ch digraph is considered two separate letters (c and h) in Polish, but it becomes a stand-alone letter placed between h and i in the Czech alphabet. This is known as a contraction in Unicode.
Note: Language rules occasionally change. For instance, the Spanish alphabet treated the ch and ll digraphs as single letters until 1994, when the official language regulation institution, RAE, declared them separate.
At some point, the accent ordering in French changed from backward to forward everywhere in the world except for Canada, which still sticks to the old tradition:
| Accent Ordering | |
|---|---|
| France | cote, coté, côte, côté |
| Canada | cote, côte, coté, côté |
In modern French, words are compared from left to right. The earliest letter with an accent, which is ô in the example above, corresponds to a greater sort key, pushing the word to the end of the list. On the other hand, in Canada, words are compared backward from right to left, so the last accent’s position determines the final order.
Depending on their geographic location worldwide, individuals speaking the same language may expect a slightly different sorting order.
Moreover, the sorting order can sometimes differ within the same culture, depending on the context. For example, most German phone books tend to treat letters with an umlaut (ä, ö, ü) similarly to the ae, oe, and ue letter combinations. However, other countries overwhelmingly treat these letters the same as their Latin counterparts (a, o, u).
There’s no universally correct way to sort Unicode strings. You need to tell Python which rules to apply to get the desired ordering. So, how do you sort Unicode strings alphabetically in Python?
Get Your Code: Click here to download the free sample code that shows you how to sort Unicode strings alphabetically with Python.
How to Sort Strings Using the Unicode Collation Algorithm (UCA)
The problem of sorting Unicode strings isn’t unique to Python. It’s a common challenge in any programming language or database. To address it, Technical Report #10 in the Unicode Technical Standard (UTS) describes the collation of Unicode strings, which is a consistent way of comparing two strings to establish their sorting order.
The Unicode Collation Algorithm (UCA) assigns a hierarchy of numeric weights to each character, allowing the creation of binary sort keys that account for accents and other special cases. These keys are defined at four levels that determine various features of a character:
- Primary: The base letter
- Secondary: The accents
- Tertiary: The letter case
- Quaternary: Other features
Later in this tutorial, you’ll learn how to leverage these weight levels to customize the Unicode collation algorithm by, for example, ignoring the letter case in case-insensitive sorting.
Note: This hierarchical nature of character weights allows you to compare sort keys incrementally to increase performance. It also helps conserve memory. For example, some implementations of the UCA take advantage of the trie data structure to efficiently store and retrieve the weights for a given string.
While the UCA supplies the Default Unicode Collation Element Table (DUCET), you should generally customize this default collation table to the specific needs of a particular language and application. It’s virtually impossible to ensure the desired sort order for all languages using only one character table. Therefore, software libraries implementing the UCA usually rely on the Common Locale Data Repository (CLDR) to provide such customization.
This repository contains several XML documents with language-specific information. For example, the collation rules for sorting text in Polish explain the relationship between the letters z, ź, and ż in both uppercase and lowercase:
&Z<ź<<<Ź<ż<<<Ż
Without going into the technical details of the collation rule syntax, you can observe that z comes before ź, which comes before ż. The same rule applies regardless of whether the letters are uppercase or lowercase.
To use the Unicode Collation Algorithm in Python, you can install the pyuca library into your virtual environment. While this library is slightly obsolete and only supports Unicode up to version 10, you can download the latest DUCET table from Unicode’s official website and supply the corresponding filename when creating a collator object:
>>> import pyuca
>>> collator = pyuca.Collator("allkeys-15.0.0.txt") # Unicode version 15.0.0
>>> collator.sort_key("zb")
(9139, 8397, 0, 32, 32, 0, 2, 2, 0)
>>> collator.sort_key("ża")
(9139, 8371, 0, 32, 46, 32, 0, 2, 2, 2, 0)
>>> collator.sort_key("zb") < collator.sort_key("ża")
False
Alternatively, you can create a collator instance without specifying the file, in which case it’ll use an older version that was distributed with the library. Calling the collator’s .sort_key() method on a string reveals a tuple of weights that you can use in a comparison.
Notice that weights at the first index in both tuples are identical, meaning that the letters z and ż are essentially treated as equal, disregarding accents. This is an intended behavior of the default collation table in UCA when you leave it without customization, but as you’ll soon learn, this isn’t ideal.
The second weight, which corresponds to the following letter, determines the sorting order of both strings. The remaining weights are irrelevant at this point.
You can sort a sequence of Unicode strings using pyuca by providing the reference to your collator’s .sort_key() method as the key function:
>>> polish_names = ["Zbigniew", "Ludmiła", "Żaneta", "Łukasz"]
>>> sorted(polish_names, key=collator.sort_key)
['Ludmiła', 'Łukasz', 'Żaneta', 'Zbigniew']
Remember to omit the parentheses at the end of the method name to avoid calling it! You want to pass a reference to a function or method that Python will later call for each item in the list. If you were to call your method here, then it would execute immediately, returning a single value instead of the callable object that sorted() expects.
As you can see, the default collation table in UCA doesn’t conform to the Polish language rules, as the name Żaneta should sort after Zbigniew. Unfortunately, pyuca doesn’t let you specify custom rules to alleviate that. While you could manually try editing the downloaded text file before supplying it to the collator, it’s a tedious and error-prone task.
Not only is pyuca limited in this regard, but it also hasn’t been actively maintained for a few years now. As a pure-Python library, it might negatively affect the performance of more demanding applications. Overall, you’re better off finding an alternative tool like PyICU, which is a Python binding to IBM’s open-source International Components for Unicode (ICU) library implemented in C++ and Java.
Note: PyICU is only available as a source distribution, so you need to have a C++ compiler and, on select platforms, a few third-party dependencies to install it. Follow the official instructions in the README file if you face any difficulties.
Once you have PyICU installed, getting started is pretty straightforward and doesn’t look much different than using pyuca. Here’s an example of how you can create a collator and supply an optional set of rules specific to a given language:
>>> from icu import Collator, Locale
>>> collator = Collator.createInstance(Locale("pl_PL"))
>>> sorted(polish_names, key=collator.getSortKey)
['Ludmiła', 'Łukasz', 'Zbigniew', 'Żaneta']
In this case, you use the Polish flavor of the Unicode collation rules, which results in the expected sort order of names. To get a complete list of all available languages, use the following code snippet:
>>> from icu import Locale
>>> Locale.getAvailableLocales().keys()
['af',
'af_NA',
'af_ZA',
'agq',
'agq_CM',
⋮
'zu',
'zu_ZA']
These languages are built into the library and shipped with it using a binary format, independently of your operating system, which may support a different set of languages. You can use any of these to customize your collator instance.
Additionally, you may build a collator from scratch with entirely custom rules expressed in a format similar to the one you’ve seen in the XML file before:
>>> from icu import RuleBasedCollator
>>> collator = RuleBasedCollator(
... """
... &A<ą<<<Ą
... &C<ć<<<Ć
... &E<ę<<<Ę
... &L<ł<<<Ł
... &N<ń<<<Ń
... &O<ó<<<Ó
... &S<ś<<<Ś
... &Z<ź<<<Ź<ż<<<Ż
... """
... )
>>> sorted(polish_names, key=collator.getSortKey)
['Ludmiła', 'Łukasz', 'Zbigniew', 'Żaneta']
You’ve created an instance of the RuleBasedCollator with the collation rules for sorting text in Polish, which you borrowed from the Common Locale Data Repository (CLDR). As a result, the Polish names are now arranged correctly.
This is barely scratching the surface of what’s possible with PyICU. The library isn’t just for sorting Unicode strings. It can also help you develop multilingual applications for users worldwide.
The biggest downside of PyICU is its potentially cumbersome installation. It’s also a relatively large library, both in terms of size on disk and an extensive API. If one of these becomes a deal-breaker for you, or if you can’t use any third-party libraries, then consider alternative options.
Next up, you’ll learn about the locale module in Python’s standard library.
Leverage Python’s locale Module to Sort Unicode Strings
Python’s official sorting how-to guide recommends using the standard library module locale to respect cultural and geographical conventions when sorting strings. It’s a Python interface to C localization functions that expose the regional settings on a POSIX-compatible operating system. Some of them include:
- Address and phone formats
- Currency symbol
- Date and time format
- Decimal symbol (for example, point vs comma)
- Language
- Measurement units
- Paper size (for example, A4 vs Letter)
These parameters are collectively known as locale. You can control them globally through a set of environment variables, like LC_ALL, which will apply to your entire operating system. Alternatively, you can selectively override some of them within your program when it runs.
Note: The concept of locale in computing is closely related to internationalization (i18n) and localization (L10n), which are about designing and adapting software to support multiple languages, respectively.
The locale is about so much more than a language. For example, English has several dialects spoken on many continents. Each dialect may have distinct traits, such as these:
| American | British | |
|---|---|---|
| Spelling | color | colour |
| Vocabulary | truck | lorry |
| Measurement System | imperial | metric |
| Currency | dollars | pounds |
| Pronunciation | uh-loo-muh-nuhm | al-yoo-min-ee-um |
Even regions of the same country sometimes exhibit slight variations. To account for these possible differences, a locale identifier consists of two mandatory and two optional parts:
- Language: A two-letter, lowercase language code (ISO 639)
- Territory: A two-letter, uppercase country code (ISO 3166)
- Charmap: An optional character encoding
- Modifier: An optional modifier for specific locale variations
For example, the identifier ca_ES.UTF-8@valencia represents the Catalan language spoken in Spain using the Valencian dialect with the UTF-8 character encoding. On the other hand, en_US is another valid identifier that corresponds to English spoken in the United States with your operating system’s default character encoding.
If you’re on macOS or a Linux distribution, then you can check your current locale by typing the locale command at your command prompt:
$ locale
LANG=en_US.UTF-8
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
You get information about specific locale categories and their values. The LC_COLLATE category controls how strings are compared, which determines the sorting order of Unicode strings.
To reveal the complete list of available locales installed in your system, append the -a flag to the locale command:
$ locale -a
C
C.UTF-8
en_GB.utf8
en_US.utf8
pl_PL.utf8
POSIX
The C and POSIX locales are defaults defining a minimal set of regional settings that must comply with the C programming language on a POSIX-compliant system.
To install an additional locale, pick one from a list of the supported locales and then generate the corresponding localization files from the chosen template. If you’re on Linux, then you can list the supported locales by revealing the contents of a special file:
$ cat /usr/share/i18n/SUPPORTED | grep pt
pt_BR.UTF-8 UTF-8
pt_BR ISO-8859-1
pt_PT.UTF-8 UTF-8
pt_PT ISO-8859-1
pt_PT@euro ISO-8859-15
$ sudo locale-gen pt_BR.UTF-8
Generating locales (this might take a while)...
pt_BR.UTF-8... done
Generation complete.
These commands enable a new locale for Portuguese as spoken in Brazil. If you’d like your operating system to pick it up, then you must also install the corresponding language pack before changing the current locale:
$ sudo apt install language-pack-pt
$ export LC_ALL="pt_BR.UTF-8"
The package name that you should install may vary. For instance, the one above is suitable for Linux distributions based on Debian. After changing the current locale, most of the standard Unix commands will reflect that in their output:
$ cat no-such-file
cat: no-such-file: Arquivo ou diretório inexistente
When you try to print the contents of a missing file with cat, you get an error message in Portuguese. Note that setting environment variables has only a temporary effect that will last until you close the current terminal session. To apply the new locale permanently, edit your shell configuration file accordingly.
Now, how do you control the locale in Python? You’ve already seen that the default lexicographic sorting in Python may lead to incorrect results. To fix that, you can try using locale.strxfrm(), which transforms a string into a locale-aware counterpart, as the sort key:
>>> import locale
>>> locale.getlocale()
('en_US', 'UTF-8')
>>> polish_names = ["Zbigniew", "Ludmiła", "Żaneta", "Łukasz"]
>>> sorted(polish_names) # Lexicographic sorting
['Ludmiła', 'Zbigniew', 'Łukasz', 'Żaneta']
>>> sorted(polish_names, key=locale.strxfrm)
['Ludmiła', 'Łukasz', 'Żaneta', 'Zbigniew']
Depending on your current locale, the list may end up sorted differently than without the custom key. However, the result can still be incorrect when you don’t specify the right locale. In such a case, Python relies on your operating system’s default locale, which may be unsuitable for the given language.
Note: You’ll also find another function locale.strcoll(), which compares two strings according to the current locale. It used to be convenient in legacy Python versions, whose sorting functions accepted the cmp parameter, which was dropped in Python 3.
When sorting strings, you always want to override the collation rules to match the language in question:
>>> locale.setlocale(locale.LC_COLLATE, "pl_PL.UTF-8")
'pl_PL.UTF-8'
>>> sorted(polish_names, key=locale.strxfrm)
['Ludmiła', 'Łukasz', 'Zbigniew', 'Żaneta']
At last, you get the expected result by setting the collation category to the Polish locale.
Note: You must have the correct locale installed in your operating system before using it in your programs. Otherwise, Python will silently fall back to the operating system’s default locale without raising an error:
>>> locale.setlocale(locale.LC_COLLATE, "pl_PL.UTF-8")
'pl_PL.UTF-8'
>>> sorted(polish_names, key=locale.strxfrm)
['Ludmiła', 'Zbigniew', 'Żaneta', 'Łukasz']
>>> locale.getlocale()
(None, 'UTF-8')
If the default locale is unset or doesn’t match the language that you wish to work with, then you’ll still get an incorrect sorting order.
Unfortunately, calling locale.setlocale() is a global setting that won’t help you with sorting words in more than one language simultaneously. It also isn’t thread-safe, so you’d typically invoke it once after starting your program, as opposed to handling the incoming HTTP requests in a multi-threaded web application, for example.
Apart from being able to handle at most one language at a time, locale will only work on POSIX-compliant systems, making it less portable than other solutions. It requires the correct locale to be installed in your system, and it supports ISO 14651, which is a subset of the complete Unicode Collation Algorithm. That said, it may be enough in more straightforward use cases.
Transliterate Foreign Characters Into Latin Equivalents
You don’t always care about precise collation rules of foreign languages. Instead, you may prefer to make the sort order appear correct to an English speaker by converting each string into a Latin script that best approximates the original. In linguistics, such conversion is known as the romanization of text, and it can take a few forms, including a combination of these:
- Transliteration: Swapping letters from one script with another
- Transcription: Representing a foreign script phonetically
The basic idea behind transliteration is to replace every non-ASCII letter with its closest Latin counterpart before comparing the strings. You can also use this technique to represent Unicode on a legacy system that only supports ASCII characters or to create a clean URL. Note that simply stripping any character beyond ASCII would alter the text, removing too much information.
Here are a few examples of words transliterated from different alphabets:
| Alphabet | Original | Transliteration |
|---|---|---|
| Cyrillic | Петроград | Petrograd |
| Greek | Κνωσός | Knosos |
| Kurdish | Xirabreşkê | Xirabreske |
| Norwegian | Svolvær | Svolvaer |
| Polish | Łódź | Lodz |
This method works best with alphabets derived from Latin or Greek, as opposed to other alphabets like Arabic, Chinese, or Hebrew. To handle non-Roman languages, you’ll need to devise a way of transcribing sounds associated with the visual symbols.
As an example, take a look at these city names and their transcriptions:
| Alphabet | Original | Transcription |
|---|---|---|
| Arabic | الرياض | Riyadh |
| Chinese | 北京 | Beijing |
| Hebrew | יְרוּשָׁלַיִם | Jerusalem |
| Japanese | 東京 | Dongjing (Tokyo) |
| Korean | 서울 | Seoul |
Transcribing a given text is inherently more complicated than transliterating it, so you’ll only consider transliteration from now on.
One way to strip accents or diacritics from Latin letters is by taking advantage of Unicode equivalence, which states that alternative sequences of code points can encode semantically identical characters. Even if two Unicode strings look the same to a human reader, they may have different lengths and contents, affecting the sort order. For example, the letter é has two canonically equivalent Unicode representations:
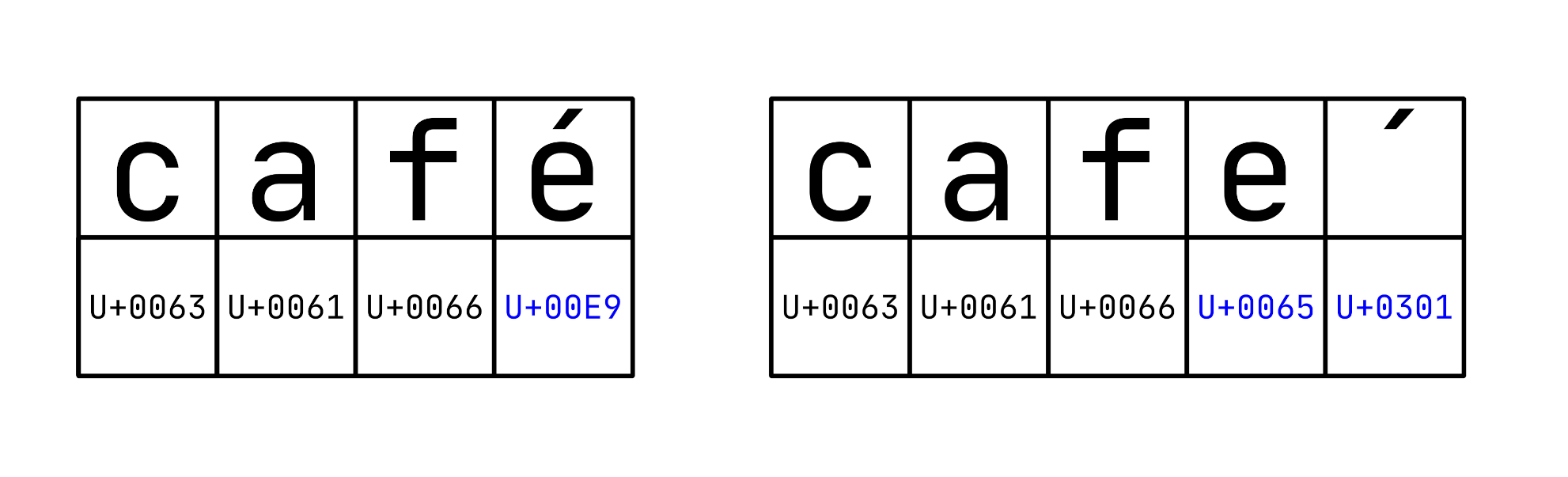
The representation on the left encodes the last letter in the word café using Unicode code point U+00E9. Conversely, the representation on the right encodes the same letter using two code points: U+0065 for the Latin letter e, followed by U+0301, which is the acute accent that combines with the preceding letter. The combining characters like these don’t stand on their own but modify how other characters render.
Note: These alternative Unicode string representations as code points are independent of their encoded byte representations, such as UTF-8 or UTF-16.
The Unicode standard specifies four normal forms and the corresponding algorithms for converting between them through a process called Unicode normalization. In Python, you can use the standard-library module unicodedata to perform such a normalization:
>>> cafe_precomposed = "caf\N{latin small letter e with acute}"
>>> cafe_combining = "cafe\N{combining acute accent}"
>>> cafe_precomposed
'café'
>>> cafe_combining
'café'
>>> len(cafe_precomposed)
4
>>> len(cafe_combining)
5
>>> cafe_precomposed == cafe_combining
False
>>> import unicodedata
>>> decompose = lambda x: unicodedata.normalize("NFD", x)
>>> compose = lambda x: unicodedata.normalize("NFC", x)
>>> decompose(cafe_precomposed) == cafe_combining
True
>>> cafe_precomposed == compose(cafe_combining)
True
Notice that the two variables render the same glyphs when you evaluate them, but the underlying strings have different lengths and don’t compare as equal. Normalizing either of the strings into the common Unicode representation allows for an apples-to-apples comparison.
Note: Some fonts may miss certain glyphs or render them in a strange way. For example, if your font doesn’t contain either the precomposed or decomposed variant of the acute accent, then you won’t see the whole picture:
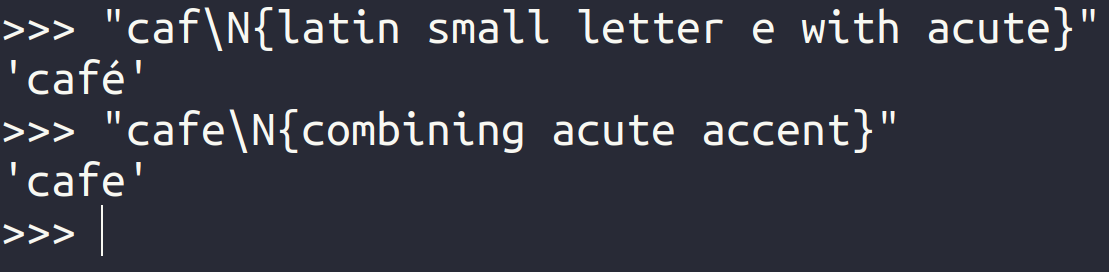
In this case, even though the second string contains two separate code points representing the letter é, it appears as a plain e on the screen. To learn more about fonts, check out Choosing the Best Coding Font for Programming.
Unicode’s NFD form allows you to decompose a Unicode string into plain Latin letters while discarding any combining characters that may result from this normalization. To make your life easier, define the following helper function, which you’ll evolve later:
>>> import unicodedata
>>> def transliterate_v1(text: str) -> str:
... return (
... unicodedata.normalize("NFD", text)
... .encode("ascii", errors="ignore")
... .decode("ascii")
... )
...
After decomposing a string, you .encode() it into a sequence of bytes while ignoring ordinal values that can’t fit in the ASCII range. Then, you .decode() the resulting bytes into a Python string again, which you return to the caller.
To verify if your function works as expected, you can test it against a few pangrams, which are humorous and often nonsensical sentences containing every letter from the given alphabet:
>>> pangrams = {
... "Czech": "Příliš žluťoučký kůň úpěl ďábelské ódy",
... "Polish": "Pójdźmyż haftnąć z wklęsłości guberń",
... "Icelandic": "Kæmi ný öxi hér, ykist þjófum nú bæði víl og ádrepa",
... }
>>> for label, pangram in pangrams.items():
... print(label, pangram, transliterate_v1(pangram), "", sep="\n")
...
Czech
Příliš žluťoučký kůň úpěl ďábelské ódy
Prilis zlutoucky kun upel dabelske ody
Polish
Pójdźmyż haftnąć z wklęsłości guberń
Pojdzmyz haftnac z wklesosci gubern
Icelandic
Kæmi ný öxi hér, ykist þjófum nú bæði víl og ádrepa
Kmi ny oxi her, ykist jofum nu bi vil og adrepa
You define and iterate through a Python dictionary of three pangrams before printing their transliterations on the screen. Unfortunately, while your solution works fine with most letters, it sometimes removes them instead of finding a replacement.
Apparently, certain letters with diacritics don’t have a corresponding combining character in Unicode. For example, the Polish letter Ł is a standalone character with an inseparable stroke, making it already normalized:
>>> from unicodedata import decomposition, is_normalized, normalize
>>> polish_diacritics = "ĄĆĘŁŃÓŚŻŹ"
>>> for letter in polish_diacritics:
... print(letter, is_normalized("NFD", letter), decomposition(letter))
...
Ą False 0041 0328
Ć False 0043 0301
Ę False 0045 0328
Ł True
Ń False 004E 0301
Ó False 004F 0301
Ś False 0053 0301
Ż False 005A 0307
Ź False 005A 0301
>>> normalize("NFD", "Ł")
'Ł'
Trying to decompose Ł yields the same letter because it’s already decomposed. You can mitigate this unwanted behavior by allowing your transliteration function to accept an optional character mapping to .translate() the string with:
>>> import sys
>>> import unicodedata
>>> def transliterate_v2(text: str, mapping: dict[str, str] = None) -> str:
... combining_characters = "".join(
... character
... for code_point in range(sys.maxunicode)
... if unicodedata.combining(character := chr(code_point))
... )
... if mapping:
... src, dst = ["".join(x) for x in zip(*mapping.items())]
... table = str.maketrans(src, dst, combining_characters)
... else:
... table = str.maketrans(dict.fromkeys(combining_characters))
... return unicodedata.normalize("NFD", text).translate(table)
...
You use a generator expression to prepare a string with all the combining characters in Unicode. If the caller provided a custom mapping, then you separate its keys and values into two strings called src and dst, which you pass to str.maketrans() to build a translation table. Otherwise, you build a translation table that just removes all combining characters. Finally, you normalize the text to the NFD form before applying the translation table.
This new function helps deal with special cases, but it doesn’t scale too well, as you still have to manually build the translation table yourself each time. Moreover, it doesn’t let you map a single code point, such as U+00E6 representing the letter æ, into more than one character, which might be necessary:
>>> transliterate_v2("Łukasz źle złożył łóżko", {"Ł": "L", "ł": "l"})
'Lukasz zle zlozyl lozko'
>>> transliterate_v2("Kæmi", {"æ": "ae"})
Traceback (most recent call last):
...
ValueError: the first two maketrans arguments must have equal length
To handle most corner cases of transliteration and even address elements of transcription, you can install Unidecode or another third-party library:
>>> import unidecode
>>> def transliterate_v3(text: str) -> str:
... return unidecode.unidecode(text)
...
>>> text = "Kæmi ný öxi hér, ykist þjófum nú bæði víl og ádrepa"
>>> print(text, transliterate_v3(text), sep="\n")
Kæmi ný öxi hér, ykist þjófum nú bæði víl og ádrepa
Kaemi ny oxi her, ykist thjofum nu baedi vil og adrepa
Unlike your earlier attempts at transliteration, calling the unidecode() function can make the resulting string longer than the original, so no information gets lost during the process.
Note: You can also do transliteration with the PyICU library that you’ve seen before:
>>> import icu
>>> tr = icu.Transliterator.createInstance("Any-ASCII")
>>> tr.transliterate("Kæmi ný öxi hér, ykist þjófum nú bæði víl og ádrepa")
'Kaemi ny oxi her, ykist thjofum nu baedi vil og adrepa'
When creating a transliterator instance, you must provide the source and target writing script identifiers.
Now, if you want to sort a sequence of Unicode strings according to their transliterations but without altering them, then you can use your transliteration function as the sort key:
>>> words = ["wklęsłości", "kæmi", "žluťoučký", "þjófum"]
>>> sorted(words, key=transliterate_v3)
['kæmi', 'þjófum', 'wklęsłości', 'žluťoučký']
This won’t give you an accurate result, but it should look right to most English-speaking audiences.
Another common challenge associated with sorting Unicode strings, which also requires Unicode normalization, is case-insensitive comparison. It’s quite widespread in real-life scenarios, so you’ll read about it now.
Perform Case-Insensitive Sorting of Unicode Strings
When you sort strings comprising only ASCII characters, then uppercase letters always come first because of their underlying ordinal values:
>>> animals = ["Turtle", "hedgehog", "monkey", "Hystrix", "fish"]
>>> sorted(animals)
['Hystrix', 'Turtle', 'fish', 'hedgehog', 'monkey']
Whether this is desired depends on the language and context. Either way, string sorting in Python is case-sensitive by default. To disregard the letter case when comparing strings, you can convert all letters to lowercase or uppercase and use them as the sort key:
>>> sorted(animals, key=str.lower)
['fish', 'hedgehog', 'Hystrix', 'monkey', 'Turtle']
Now, your strings are sorted alphabetically regardless of their letter case. Unfortunately, while this quick fix works for most English words, it breaks down when encountering accented letters like the French é:
>>> animaux = ["Tortue", "hérissonne", "Éléphant", "poisson", "éléphant"]
>>> sorted(animaux, key=str.lower)
['hérissonne', 'poisson', 'Tortue', 'Éléphant', 'éléphant']
Under the surface, you still sort your strings lexicographically using character code points. So, even though you compare a lowercase letter é against lowercase h, the latter comes first because it has a smaller ordinal value.
It’s worth noting that the concept of uppercase and lowercase letters isn’t universal to all writing systems like it appears in the Latin alphabet. Besides, as you spend more time working with foreign texts, you may run into some really surprising edge cases in Unicode.
For instance, the German letter ß (sharp S) never occurs at the start of a word. Therefore, for a long time, it was only available as a lowercase letter without an uppercase variant in the alphabet:
>>> "ß".islower()
True
>>> "ß".upper()
'SS'
When you try uppercasing it in Python, you get a double-S digraph instead. But, some fonts do provide a capital form of sharp S, and Unicode even assigns a dedicated code point (U+1E9E) to it:
>>> capital_sharp_s = "\N{latin capital letter sharp s}"
>>> capital_sharp_s
'ẞ'
>>> capital_sharp_s.lower()
'ß'
>>> capital_sharp_s.lower().upper() == capital_sharp_s
False
Nevertheless, you can’t restore its original capital form using chained calls to .lower() and .upper() in Python. At the same time, various dialects of the German language in countries like Switzerland don’t use sharp S at all.
Another interesting quirk is the Greek letter Σ (sigma), which has two alternative lowercase forms depending on where you put it in a word:
>>> "Σ".lower()
'σ'
>>> "ΔΣ".lower()
'δς'
>>> "σ".upper() == "ς".upper()
True
At the end of a word, a lowercase sigma takes the final form ς, but everywhere else, it appears as the more traditional σ.
Uppercase versions of the Latin b, Greek β, and Cyrillic в have an identical visual appearance despite having distinct code points:
>>> for lowercase in ("b", "β", "в"):
... uppercase = lowercase.upper()
... print(uppercase, hex(ord(uppercase)))
...
B 0x42
Β 0x392
В 0x412
As you can see, there are far too many corner cases to try and cover them all by hand.
Fortunately, Python 3.3 introduced a new string method called str.casefold(), which adds support for Unicode case folding for the purpose of caseless comparison of text. According to the Unicode glossary, folding lets you temporarily ignore certain distinctions between characters. In general, case folding works similarly to lowercasing a string, but there are a few notable exceptions:
>>> "Ą".lower(), "Ą".casefold()
('ą', 'ą')
>>> "ß".lower(), "ß".casefold()
('ß', 'ss')
>>> "\u13ad".lower(), "\u13ad".casefold()
('ꭽ', 'Ꭽ')
Special cases like the German sharp S are handled differently, letting you compare words like GROSS and groß as equal. Also, starting from Unicode version 8.0, Cherokee letters like U+13AD representing Ꭽ fold to uppercase letters in order to give the stability guarantees required by case folding.
That’s great! Can you now use str.casefold() instead of str.lower() or str.upper() as your key function for case-insensitive sorting of Unicode strings in Python? Well, not exactly.
First of all, it won’t address the problem associated with arbitrary ordinal values of accented letters. Secondly, the strings that you wish to compare must share a common Unicode representation. Because case folding doesn’t always preserve the normal form of the original string, you should generally perform the normalization after folding your strings.
So, to implement a case-insensitive key function for sorting strings, as specified by the Unicode Standard, you must combine str.casefold() with Unicode normalization:
>>> import functools
>>> import unicodedata
>>> def case_insensitive(text: str) -> str:
... nfd = functools.partial(unicodedata.normalize, "NFD")
... return nfd(nfd(text).casefold())
...
>>> case_insensitive("groß") == case_insensitive("GROSS")
True
>>> case_insensitive("groß") == case_insensitive("grób")
False
Using the functools module, you define a partial function nfd() that takes a string as an argument and applies the Unicode canonical decomposition to it. You then call this function twice to normalize the string before and after the case folding. Calling it twice acts as an extra safeguard against rare edge cases involving one particular combining character in Greek that requires special treatment to fully comply with the Unicode Standard.
Note: This code is adapted from Python’s official Unicode how-to guide, which explains how to correctly compare strings in a case-insensitive way. It follows the formal specification from Section 3.13 Default Case Algorithms in Chapter 3 of the Unicode Standard.
Having this new key function in place, you can now sort your French animals alphabetically while ignoring the letter case:
>>> sorted(animaux, key=case_insensitive)
['Éléphant', 'éléphant', 'hérissonne', 'poisson', 'Tortue']
Success! While exploring the quirks of Unicode is undoubtedly a great learning experience, you can achieve a similar effect with much less effort using the Unicode Collation Algorithm (UCA).
If you already have the PyICU library installed, then you can ignore the letter case entirely by tweaking your collator object:
>>> from icu import Collator, Locale
>>> collator = Collator.createInstance(Locale("fr_FR"))
>>> collator.setStrength(Collator.SECONDARY)
>>> sorted(animaux, key=collator.getSortKey)
['Éléphant', 'éléphant', 'hérissonne', 'poisson', 'Tortue']
By decreasing the collator’s strength to secondary, you make it disregard the subsequent levels of character weights in UCA, including the tertiary level responsible for uppercase and lowercase differences. You can also decide whether uppercase letters should come first or the other way around by configuring the CaseFirst parameter.
Note: In the pure-Python pyuca library, lowercase letters always come before their uppercase counterparts, and you don’t have control over this behavior:
>>> from pyuca import Collator
>>> sorted(animaux, key=Collator().sort_key)
['éléphant', 'Éléphant', 'hérissonne', 'poisson', 'Tortue']
The weight values embedded in the Default Unicode Collation Element Table (DUCET), which the library uses under the hood, determine such ordering. Notice that this breaks the stability of the sorting algorithm, as the two elephants swapped positions in the list.
Comparing strings in a case-insensitive way is one of the most common requirements when sorting or searching for strings. But, there are many more special cases that you may need to consider, like the handling of punctuation, whitespace characters, or numbers. Libraries like PyICU let you customize the collation rules accordingly.
Next up, you’ll learn about the natural sort order, which your users might expect in some scenarios.
Sort Strings With Numbers in Natural Order
Arranging strings in the natural sort order is similar to alphabetical sorting, but it takes digits that may be part of the string into account. A typical example of that would involve listing a directory full of log files whose names contain a version number:
$ ls -v
log.1 log.2 ... log.10 log.11 log.12 ... log.100 log.101 log.102 ...
While such ordering looks natural to most humans, the lexicographic sorting in Python and other programming languages produces a less-than-intuitive result for the same input sequence of strings:
>>> sorted(f"log.{i}" for i in range(1, 111))
['log.1',
'log.10',
'log.100',
'log.101',
⋮
'log.11',
'log.110',
'log.12',
⋮
'log.2',
'log.20',
'log.21',
⋮
'log.99']
Because Python compares your strings by value, all digits end up treated as ordinary character code points instead of numbers. So, a string that contains "10" comes before "2", disrupting the natural ordering of numbers. To fix this, you can try using regular expressions by isolating the individual alphanumeric chunks of the string into separate elements to compare:
>>> import re
>>> def natural_order(text: str) -> tuple[str | int, ...]:
... return tuple(
... int(chunk) if chunk.isdigit() else chunk
... for chunk in re.split(r"(\d+)", text)
... )
...
>>> natural_order("log.42")
('log.', 42, '')
>>> sorted([f"log.{i}" for i in range(1, 111)], key=natural_order)
['log.1',
'log.2',
'log.3',
'log.4',
⋮
'log.10',
'log.11',
'log.12',
⋮
'log.100',
'log.101',
'log.102',
⋮
'log.110']
Your sort key function, natural_order(), returns a tuple whose elements are either strings or integers. This compound key allows Python to compare the corresponding tuple elements one by one from left to right using the appropriate comparison for the data type.
Note that this is a fairly straightforward implementation that can’t handle signed numbers, floating-point numbers, or any of the edge cases that you’ve learned so far. To deal with special cases like locale-aware and case-insensitive sorting, you should reach for a hassle-free library like natsort, which plays nicely with PyICU:
>>> filenames = [
... "raport_maj-2023.xlsx",
... "błędy.log.3",
... "błędy.log.1",
... "Raport_kwiecień_2023.xlsx",
... "Błędy.log.101",
... ]
>>> import locale
>>> locale.setlocale(locale.LC_ALL, "pl_PL.UTF-8")
'pl_PL.UTF-8'
>>> from natsort import natsorted, ns
>>> natsorted(filenames, alg=ns.LOCALE | ns.IGNORECASE)
['błędy.log.1',
'błędy.log.3',
'Błędy.log.101',
'Raport_kwiecień_2023.xlsx',
'raport_maj-2023.xlsx']
Use the locale module to set the desired language and country code. When natsort detects PyICU in your virtual environment, it’ll use it and only fall back to locale if it can’t find this third-party library. Just make sure to set the locale before importing natsort. Otherwise, it’ll fall back to your operating system’s default locale.
So far, you’ve been sorting plain strings in Python, which is rarely the case in real-world programming projects. You’re more likely to sort complex data structures or objects by their specific attributes. In the next section, you’ll learn how to do just that.
Sort Complex Objects by More Than One Key
Ordering people by name is a classic example of sorting complex objects, which often comes up in practice. Suppose that you need to compile a list of employees in a company according to their first and last names for an annual report. You can leverage Python’s named tuple to represent each person:
>>> from typing import NamedTuple
>>> class Person(NamedTuple):
... first_name: str
... last_name: str
...
... def __repr__(self):
... return f"{self.first_name} {self.last_name}"
...
>>> people = [
... Person("Zbigniew", "Nowak"),
... Person("Anna", "Wójcik"),
... Person("Łukasz", "Kowalski"),
... Person("Żaneta", "Jabłońska"),
... Person("Anna", "Nowak"),
... Person("Ludmiła", "Wiśniewska"),
... ]
>>> sorted(people)
[Anna Nowak,
Anna Wójcik,
Ludmiła Wiśniewska,
Zbigniew Nowak,
Łukasz Kowalski,
Żaneta Jabłońska]
Because each person is a tuple consisting of the first and last names, Python knows how to compare these objects without requiring you to implement any special methods in your class. When you pass a list of Person instances to the sorted() function, each object becomes a compound key. Unfortunately, sorting still relies on the lexicographic order of Unicode strings, so you don’t get the expected result.
You can fix the situation by defining your own compound key using the pyuca collator:
>>> import pyuca
>>> collator = pyuca.Collator()
>>> def compound_key(person: Person) -> tuple:
... return (
... collator.sort_key(person.first_name),
... collator.sort_key(person.last_name),
... )
...
>>> sorted(people, key=compound_key)
[Anna Nowak,
Anna Wójcik,
Ludmiła Wiśniewska,
Łukasz Kowalski,
Żaneta Jabłońska,
Zbigniew Nowak]
This time, the result comes out a bit better but still not quite correct, as Zbigniew is placed after Żaneta. Do you remember why?
It’s the same problem that you ran into earlier while using pyuca, which relies on the default collation table without letting you customize it for the specific locale. Fortunately, you can define a compound key using PyICU equally well:
>>> from icu import Collator, Locale
>>> collator = Collator.createInstance(Locale("pl_PL"))
>>> def compound_key(person: Person) -> tuple:
... return (
... collator.getSortKey(person.first_name),
... collator.getSortKey(person.last_name),
... )
...
>>> sorted(people, key=compound_key)
[Anna Nowak,
Anna Wójcik,
Ludmiła Wiśniewska,
Łukasz Kowalski,
Zbigniew Nowak,
Żaneta Jabłońska]
Overall, this code looks very much the same but uses a slightly different API that exposes the locale customization. When you configure suitable language rules, you get the desired result.
If you’re curious, then you can experiment by swapping the attributes in your compound key to observe how that affects the sorting order:
>>> def by_last_name_first(person: Person) -> tuple:
... return (
... collator.getSortKey(person.last_name),
... collator.getSortKey(person.first_name),
... )
...
>>> sorted(people, key=by_last_name_first)
[Żaneta Jabłońska,
Łukasz Kowalski,
Anna Nowak,
Zbigniew Nowak,
Ludmiła Wiśniewska,
Anna Wójcik]
In this case, you’ve sorted your employees primarily by last name. You then sort individuals who share the same last name by first name.
Now you know how to sort complex objects using a custom compound key, which takes locale-aware Unicode collation rules into account. With that skill under your belt, you conclude this comprehensive tutorial.
Conclusion
Congratulations on successfully navigating the intricate task of sorting Unicode strings in Python! You’re now aware of the potential hurdles that you might face in real-world projects, as well as strategies to overcome them. You’ve gained insight into the Unicode Collation Algorithm (UCA) and several Python libraries that expose it to you.
You know the difference between alphabetical and lexicographic sorting, understand what collation rules are, and can explain how the canonical decomposition in Unicode works. You’re able to customize your sorting order to make it locale-aware, reflecting specific cultural conventions. Furthermore, you can romanize non-Latin texts through transliteration and transcription for compatibility with systems that only support ASCII.
Your newfound expertise lets you safely perform case-insensitive sorting and natural sorting within the Unicode domain. Finally, you can construct compound sort keys for ordering complex objects based on a subset of attributes. Armed with this thorough knowledge, you’re well prepared to develop reliable multilingual applications catered to a global user base.
Get Your Code: Click here to download the free sample code that shows you how to sort Unicode strings alphabetically with Python.







