If you’re like most Python users, then you probably started your Python journey by learning about print(). It helped you write your very own “Hello, World!” one-liner and brought your code to life on the screen. Beyond that, you can use it to format messages and even find some bugs. But if you think that’s all there is to know about Python’s print() function, then you’re missing out on a lot!
Keep reading to take full advantage of this seemingly boring and unappreciated little function. This tutorial will get you up to speed with using Python print() effectively. However, be prepared for a deep dive as you go through the sections. You may be surprised by how much print() has to offer!
By the end of this tutorial, you’ll understand that:
- The
print()function can handle multiple arguments and custom separators to format output effectively. - You can redirect
print()output to files or memory buffers using thefileargument, enhancing flexibility. - Mocking
print()in unit tests helps verify code behavior without altering the original function. - Using the
flushargument ensures immediate output, overcoming buffering delays in certain environments. - Thread-safe printing is achievable by implementing locks to prevent output interleaving.
If you’re just getting started with Python, then you’ll benefit most from reading the first part of this tutorial, which illustrates the essentials of printing in Python. Otherwise, feel free to skip ahead and explore the sections that interest you the most.
Get Your Code: Click here to download the free sample code that shows you how to use the print() function in Python.
Take the Quiz: Test your knowledge with our interactive “The Python print() Function” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
The Python print() FunctionIn this quiz, you'll test your understanding of Python's built-in print() function, covering how to format output, specify custom separators, and more.
Printing in a Nutshell
It’s time to jump in by looking at a few real-life examples of printing in Python. By the end of this section, you’ll know every possible way of calling print().
Producing Blank Lines
The simplest example of using Python print() requires just a few keystrokes:
print()
This produces an invisible newline character, which in turn causes a blank line to appear on your screen. To add vertical space, you can call print() multiple times in a row like this:
print()
print()
print()
It’s just as if you were hitting Enter on your keyboard in a word processor program or a text editor.
While you don’t pass any arguments to print(), you still need to put empty parentheses at the end of the line to tell Python to actually execute that function rather than just refer to it by name. Without parentheses, you’d obtain a reference to the underlying function object:
>>> print()
>>> print
<built-in function print>
The code snippet above runs within an interactive Python REPL, as indicated by the prompt (>>>). Because the REPL executes each line of Python code immediately, you see a blank line right after calling print(). On the other hand, when you skip the trailing parentheses, you get to see a string representation of the print() function itself.
As you just saw, calling print() without arguments results in a blank line, which is a line comprised solely of the newline character. Don’t confuse this with an empty string, which doesn’t contain any characters at all, not even the newline!
You can use Python’s string literals to visualize these two:
- Blank Line:
"\n" - Empty String:
""
The first string literal is exactly one character long, whereas the second one has no content—it’s empty.
Note: To remove the newline character from a string in Python, use its .rstrip() method, like this:
>>> "A line of text.\n".rstrip()
'A line of text.'
This strips any trailing whitespace from the right edge of the string of characters. To learn more about .rstrip(), check out the How to Strip Characters From a Python String tutorial.
Even though Python usually takes care of the newline character for you, it helps to understand how to deal with it yourself.
Dealing With Newlines
A newline character is a special control character used to indicate the end of a line (EOL). It usually doesn’t have a visible representation on the screen, but some text editors can display such non-printable characters with little graphics.
The word “character” is somewhat of a misnomer in this case, because a newline can be more than one character long. For example, the Windows operating system, as well as the HTTP protocol, represent newlines with a pair of characters. Sometimes you need to take those differences into account to design truly portable programs.
To find out what constitutes a newline in your operating system, you can use the os module from Python’s standard library.
If you’re on Windows, then you’ll find out that your operating system represents a newline using a sequence of two control characters. This sequence consists of a carriage return (\r) followed by a line feed (\n):
>>> import os
>>> os.linesep
'\r\n'
On Unix, Linux, and recent versions of macOS, it’s a single \n character:
>>> import os
>>> os.linesep
'\n'
The classic Mac OS (pre-OS X) sticks to its own think different philosophy by choosing yet another representation, which you can still find in the wild sometimes:
>>> import os
>>> os.linesep
'\r'
Notice how these characters appear in string literals. They use special syntax with a preceding backslash (\) to denote the start of an escape character sequence. Such sequences allow for representing control characters, which would be otherwise invisible on screen.
Most programming languages come with a predefined set of escape sequences for special characters such as these:
| Escape Sequence | Character |
|---|---|
\\ |
Backslash |
\b |
Backspace |
\t |
Tab |
\r |
Carriage Return (CR) |
\n |
Line Feed (LF) |
The last two are reminiscent of mechanical typewriters, which required two separate commands to insert a newline. The first command would move the carriage back to the beginning of the current line, while the second one would advance the roll to the next line.
By looking at the corresponding ASCII character codes, you’ll see that putting a backslash in front of a character in a string literal changes that character’s meaning. However, not all characters allow for this—only a few special ones.
To check the ASCII code of a character, you may want to use the built-in ord() function:
>>> ord("r")
114
>>> ord("\r")
13
This function takes a one-character string, so the sequence \r counts as one character. Keep in mind that, in order to form a correct escape sequence, there must be no space between the backslash character and a letter!
Earlier, you saw how to print a blank line using print(). However, in a more common scenario, you’d want to communicate some message to the end user. There are a few ways to achieve this, which you’ll explore now.
Passing Arguments
First, you can pass a string literal directly to print() as an argument:
>>> print("Please wait while the program is loading...")
Please wait while the program is loading...
This will print the message exactly as written onto the screen.
Next, you can extract that message into its own variable with a meaningful name to enhance readability and promote code reuse:
>>> message = "Please wait while the program is loading..."
>>> print(message)
Please wait while the program is loading...
Finally, you can pass an expression, like string concatenation to print(), which will be evaluated dynamically before the result is displayed:
>>> import os
>>> print("Hello, " + os.getlogin() + "! How are you?")
Hello, jdoe! How are you?
While this works as expected, there are a dozen string formatting tools in Python that offer more concise and readable syntax. One such tool is formatted string literals or f-strings, which you can use with print():
>>> import os
>>> print(f"Hello, {os.getlogin()}! How are you?")
Hello, jdoe! How are you?
The result is the same as before, but f-strings will prevent you from making a common mistake, which is forgetting to typecast concatenated operands. Python is a strongly typed language, which means it won’t allow you to do this:
>>> "My age is " + 42
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
"My age is " + 42
~~~~~~~~~~~~~^~~~
TypeError: can only concatenate str (not "int") to str
This is wrong because adding numbers to strings doesn’t make sense. You need to explicitly convert the number to a string first in order to join them together:
>>> "My age is " + str(42)
'My age is 42'
Unless you handle such errors yourself, the Python interpreter will let you know about a problem by showing a traceback.
Note: str is a global built-in function that converts an object into its string representation.
You can call it directly on any object, for example, a number:
>>> str(3.14)
'3.14'
Built-in data types have a predefined string representation out of the box, but later in this tutorial, you’ll find out how to provide one for your custom classes.
As with any function, it doesn’t matter whether you pass a literal, a variable, or an expression. Unlike many other functions, however, print() will accept anything regardless of its type.
So far, you’ve only looked at the string, but what about other data types? Try out literals of different built-in types and see what comes out:
>>> print(42) # <class 'int'>
42
>>> print(3.14) # <class 'float'>
3.14
>>> print(1 + 2j) # <class 'complex'>
(1+2j)
>>> print(True) # <class 'bool'>
True
>>> print([1, 2, 3]) # <class 'list'>
[1, 2, 3]
>>> print((1, 2, 3)) # <class 'tuple'>
(1, 2, 3)
>>> print({"red", "green", "blue"}) # <class 'set'>
{'red', 'green', 'blue'}
>>> print({"name": "Alice", "age": 42}) # <class 'dict'>
{'name': 'Alice', 'age': 42}
>>> print("hello") # <class 'str'>
hello
Watch out for the None constant, though. Despite being used to indicate an absence of a value, it will show up as “None” rather than an empty string:
>>> print(None)
None
How does print() know how to work with all these different types? Well, the short answer is that it doesn’t. It implicitly calls str() behind the scenes to typecast any object into a string. Afterward, it treats strings in a uniform way.
Later in this tutorial, you’ll learn how to use this mechanism for printing custom data types such as your classes.
Okay, you’re now able to call print() without any arguments or with a single argument. You’ve learned how to display both fixed and formatted messages on the screen. In the next subsection, you’ll explore message formatting in a bit more detail.
Separating Multiple Arguments
You’ve seen print() called without any arguments to produce a blank line, and with a single argument to display either a fixed or a formatted message.
It turns out that print() is a variadic function, meaning it can accept any number of positional arguments, including zero, one, or more arguments. That’s very handy in a common case of message formatting, where you’d want to join a few elements together.
Have a look at this example:
>>> import os
>>> print("My name is", os.getlogin(), "and I am", 42)
My name is jdoe and I am 42
print() concatenated all four arguments passed to it, inserting a single space between them so that you didn’t end up with a squashed message like 'My name isjdoeand I am42'.
Notice that it also took care of proper typecasting by implicitly calling str() on each argument before joining them together. If you recall from the previous subsection, a naïve concatenation may easily result in an error due to incompatible types:
>>> print("My age is: " + 42)
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
print("My age is: " + 42)
~~~~~~~~~~~~~~^~~~
TypeError: can only concatenate str (not "int") to str
Apart from accepting a variable number of positional arguments, print() defines four named or keyword arguments, which are optional since they all have default values:
| Keyword Argument | Default Value | Description |
|---|---|---|
sep |
" " |
String inserted between values |
end |
"\n" |
String appended after the last value |
file |
None |
File-like object to write the output to (defaults to stdout) |
flush |
False |
Whether to forcibly flush the stream |
You can view their brief documentation by calling help(print) from the interactive interpreter.
For now, you’ll focus on sep, which stands for separator and is assigned a single space (" ") by default. It determines the value to join elements with. It has to be either a string or None, but the latter has the same effect as the default space:
>>> print("hello", "world", sep=None)
hello world
>>> print("hello", "world", sep=" ")
hello world
>>> print("hello", "world")
hello world
If you wanted to suppress the separator completely, you’d have to pass an empty string ("") instead:
>>> print("hello", "world", sep="")
helloworld
You may want print() to join its arguments as separate lines. In that case, simply pass the escaped newline character described earlier:
>>> print("hello", "world", sep="\n")
hello
world
A more useful example of the sep parameter would be printing something like file paths:
>>> print("home", "user", "documents", sep="/")
home/user/documents
Remember that the separator comes between the elements, not around them, so you need to account for that in one way or another:
>>> print("/home", "user", "documents", sep="/")
/home/user/documents
>>> print("", "home", "user", "documents", sep="/")
/home/user/documents
Specifically, you can insert a forward slash character (/) into the first positional argument, or use an empty string as the first argument to enforce the leading slash.
Note: Be careful about joining elements of a list or tuple. Doing it manually will result in a well-known TypeError if at least one of the elements isn’t a string:
>>> print(" ".join(["jdoe is", 42, "years old"]))
Traceback (most recent call last):
File "<python-input-0>", line 1, in <module>
print(" ".join(["jdoe is", 42, "years old"]))
~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: sequence item 1: expected str instance, int found
It’s safer to just unpack the sequence with the star operator (*) and let print() handle typecasting:
>>> print(*["jdoe is", 42, "years old"])
jdoe is 42 years old
Unpacking is effectively the same as calling print() with individual elements of the list.
Another interesting use case involves exporting data to a comma-separated values (CSV) format:
>>> print(1, "Python Tricks", "Dan Bader", sep=",")
1,Python Tricks,Dan Bader
This wouldn’t handle edge cases such as escaping commas correctly, but for simple use cases, it should do. The line displayed above would show up in your terminal window. In order to save it to a file, you’d have to redirect the output. Later in this section, you’ll see how to use print() to write text to files straight from Python.
Finally, the sep parameter isn’t constrained to a single character only. You can join elements with strings of any length:
>>> print("node", "child", "child", sep=" -> ")
node -> child -> child
Coming up, you’ll explore the remaining keyword arguments of the print() function.
Preventing Line Breaks
Sometimes, you may not want to end your message with a trailing newline, allowing subsequent calls to print() to continue on the same line. Classic examples include updating the progress of a long-running operation or prompting the user for input. In the latter case, you want the user to enter the answer on the same line:
Are you sure you want to do this? [y/n] y
Many programming languages provide functions similar to print() through their standard libraries, but they let you decide whether to add a newline or not. For example, in Java and C#, you have two distinct functions, while other languages require you to explicitly append \n at the end of a string literal.
Here are a few examples of the syntax in such languages:
| Language | Example |
|---|---|
| Perl | print "hello world\n" |
| C | printf("hello world\n"); |
| C++ | std::cout << "hello world" << std::endl; |
In contrast, Python’s print() function always adds \n without asking, because that’s what you typically want. To disable it, you can take advantage of yet another keyword argument, end, which dictates what to end the line with.
In terms of semantics, the end parameter is almost identical to the sep one that you saw earlier:
- It must be a string or
None. - It can be arbitrarily long.
- It has a default value of
"\n". - If equal to
None, it’ll have the same effect as the default value. - If equal to an empty string (
""), it’ll suppress the newline.
Now you understand what’s happening under the hood when you call print() without arguments. Since you don’t provide any positional arguments to the function, there’s nothing to be joined, so the default separator isn’t used at all. However, the default value of end still applies, and a blank line appears.
Note: You may be wondering why the end parameter has a fixed default value rather than whatever makes sense on your operating system.
As long as you print to the standard output stream (stdout) rather than to a file, which is the function’s default behavior, then you don’t have to worry about newline representation across different operating systems. Python will handle the conversion automatically. Just remember to always use the "\n" escape sequence in your string literals.
This is currently the most portable way to print a newline character in Python:
>>> print("line1\nline2\nline3")
line1
line2
line3
If you were to try to forcefully print a Windows-specific newline character on a Linux machine, for example, then you might end up with broken output, depending on your terminal and Python version:
>>> print("line1\r\nline2\r\nline3")
line3
When you open a file for reading, you don’t need to care about newline representation either. Thanks to the universal newline functionality, Python translates any system-specific newline it encounters into the Unix-style "\n". At the same time, you have control over how the newlines should be treated both on input and output if you really need that.
To disable the newline when printing, you must specify an empty string through the end keyword argument:
print("Checking file integrity...", end="")
# ...
print("OK")
Even though these are two separate print() calls, which can execute a long time apart, you’ll eventually see only one line. First, it’ll look like this:
Checking file integrity...
However, after the second call to print(), the same line will appear on the screen as:
Checking file integrity...OK
As with sep, you can use end to join individual pieces into a big blob of text with a custom separator. Instead of joining multiple arguments, however, it’ll append text from each function call to the same line:
print("The first sentence", end=". ")
print("The second sentence", end=". ")
print("The last sentence.")
These three instructions will output a single line of text:
The first sentence. The second sentence. The last sentence.
You can mix the two keyword arguments:
print("Mercury", "Venus", "Earth", sep=", ", end=", ")
print("Mars", "Jupiter", "Saturn", sep=", ", end=", ")
print("Uranus", "Neptune", "Pluto", sep=", ")
Not only do you get a single line of text, but all items are separated with a comma:
Mercury, Venus, Earth, Mars, Jupiter, Saturn, Uranus, Neptune, Pluto
There’s nothing to stop you from using the newline character with some extra padding around it:
print("Printing in a Nutshell", end="\n * ")
print("Producing Blank Lines", end="\n * ")
print("Dealing With Newlines", end="\n * ")
print("Passing Arguments")
It would print out the following piece of text:
Printing in a Nutshell
* Producing Blank Lines
* Dealing With Newlines
* Passing Arguments
As you can see, the end keyword argument will accept arbitrary strings.
Note: When you loop over the lines in a text file, each line retains its newline character. Combined with the default behavior of print(), this results in an extra blank line in the output:
>>> with open("file.txt", encoding="utf-8") as file:
... for line in file:
... print(line)
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
There are two newlines after each line of text. You want to strip one of the them, as you saw earlier in this tutorial, before printing the line:
>>> with open("file.txt", encoding="utf-8") as file:
... for line in file:
... print(line.rstrip())
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
Alternatively, you can keep the newline in the content but suppress the one appended by print() automatically. To do that, you’d use the end keyword argument:
>>> with open("file.txt", encoding="utf-8") as file:
... for line in file:
... print(line, end="")
...
Lorem ipsum dolor sit amet, consectetur adipisicing elit, sed do eiusmod
tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam,
quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo
By ending a line with an empty string, you effectively disable one of the newlines.
You’re getting more acquainted with printing in Python, but there’s still a lot of useful information ahead. Coming up next, you’ll learn how to intercept and redirect the print() function’s output.
Printing to a File
Believe it or not, print() doesn’t know how to turn messages into text on your screen, and frankly, it doesn’t need to. That’s a job for lower-level layers of code, which understand bytes and know how to push them around.
print() is an abstraction over these layers, providing a convenient interface that merely delegates the actual printing to a stream of characters. A stream can be any file on your disk, a network socket, or even an in-memory data buffer.
In addition to custom streams, there are three standard streams provided by the operating system:
Standard output is what you see in the terminal when you run various command-line programs, including your own Python scripts:
$ cat hello.py
print("This will appear on stdout")
$ python hello.py
This will appear on stdout
Unless otherwise instructed, print() will default to writing to standard output. However, you can tell your operating system to temporarily swap out stdout for a file stream, so that any output is sent to that file instead of the screen:
$ python hello.py > file.txt
$ cat file.txt
This will appear on stdout
The right-angle bracket (>) redirects the standard output stream of your Python program into a local file.
The standard error is similar to stdout in that it also shows up on the screen. Nonetheless, it’s a separate stream, whose purpose is to log error messages for diagnostics. By redirecting one or both of them, you can keep things clean.
To redirect stderr, you need to know about file descriptors, also known as file handles.
They’re arbitrary, albeit constant, numbers associated with standard streams. Below, you’ll find a summary of the file descriptors for a family of POSIX-compliant operating systems:
| Stream | File Descriptor |
|---|---|
stdin |
0 |
stdout |
1 |
stderr |
2 |
Knowing those descriptors allows you to redirect one or more streams at a time:
| Command | Description |
|---|---|
./program > out.txt |
Redirect stdout |
./program 2> err.txt |
Redirect stderr |
./program > out.txt 2> err.txt |
Redirect stdout and stderr to separate files |
./program &> out_err.txt |
Redirect stdout and stderr to the same file |
Note that > is the same as 1>.
Some programs use different coloring to distinguish between messages printed to stdout and stderr:
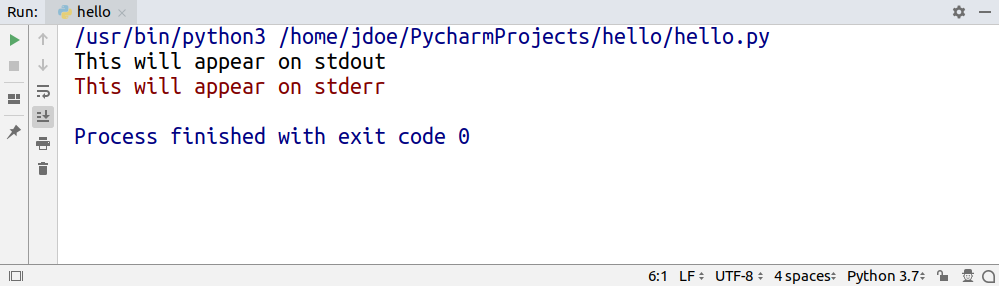
While both stdout and stderr are write-only, stdin—the standard input—is read-only. You can think of standard input as your keyboard. But just like with the other two, you can replace stdin with a file to read data from instead.
In Python, you can access all standard streams through the built-in sys module:
>>> import sys
>>> sys.stdin
<_io.TextIOWrapper name='<stdin>' mode='r' encoding='UTF-8'>
>>> sys.stdin.fileno()
0
>>> sys.stdout
<_io.TextIOWrapper name='<stdout>' mode='w' encoding='UTF-8'>
>>> sys.stdout.fileno()
1
>>> sys.stderr
<_io.TextIOWrapper name='<stderr>' mode='w' encoding='UTF-8'>
>>> sys.stderr.fileno()
2
As you can see, these predefined values resemble file-like objects with mode and encoding attributes, as well as .read() and .write() methods, among many others.
By default, print() sends output to sys.stdout via its file argument, but you can change that. By passing a file object opened in write or append mode to the file parameter, you can direct the output straight to that file instead of the screen:
>>> with open("file.txt", mode="w", encoding="utf-8") as output_file:
... print("hello world", file=output_file)
...
This will make your code immune to stream redirection at the operating system level, which might or might not be desired.
Note: For more information on working with files in Python, check out Reading and Writing Files in Python (Guide).
Note that print() has no control over character encoding. Instead, it’s the responsibility of the underlying stream to encode received Unicode strings into bytes correctly. As a best practice, consider explicitly setting the character encoding to UTF-8, which is a good choice in most cases. It covers a wide range of Unicode characters while remaining backward compatible with ASCII.
For legacy systems, you’ll want to specify a different encoding accordingly:
>>> with open("file.txt", mode="w", encoding="iso-8859-1") as file:
... print("über naïve café", file=file)
...
Instead of a real file existing somewhere in your file system, you can provide a fake one, which would reside in your computer’s memory. You’ll use this technique later for mocking print() in unit tests:
>>> import io
>>> fake_file = io.StringIO()
>>> print("hello world", file=fake_file)
>>> fake_file.getvalue()
'hello world\n'
With this code, you capture printed output into an in-memory string buffer instead of displaying it on the screen. The print() function writes to the buffer, and .getvalue() retrieves the accumulated content as a string.
Don’t try using print() to write binary data, as it’s only well suited for text. Just call the binary file’s .write() directly:
with open("file.dat", mode="wb") as file:
file.write(bytes(4))
file.write(b"\xff")
If you attempt to write raw bytes to the standard output, then this will also fail because sys.stdout is a character stream:
>>> import sys
>>> sys.stdout.write(bytes(4))
Traceback (most recent call last):
File "<python-input-1>", line 1, in <module>
sys.stdout.write(bytes(4))
~~~~~~~~~~~~~~~~^^^^^^^^^^
TypeError: write() argument must be str, not bytes
Instead, you need to dig deeper to get a handle of the underlying byte stream:
>>> import sys
>>> num_bytes_written = sys.stdout.buffer.write(b"\x41\x0a")
A
This prints an uppercase letter A and a newline character, which correspond to the decimal values of 65 and 10 in ASCII. However, they’re encoded using hexadecimal notation in the bytes literal.
If you’ve reached this point, then you’re left with only one keyword argument in print(), which you’ll take a look at next. Even though it’s probably the least used of them all, there are times when it’s absolutely necessary.
Buffering print() Calls
In the previous section, you learned that print() delegates printing to a file-like object such as sys.stdout. Some streams, however, buffer certain I/O operations to enhance performance, which can get in the way. Take a look at an example.
Imagine you’re writing a countdown timer, which should append the remaining time to the same line every second:
3...2...1...Go!
Your first attempt may look something like this:
countdown.py
import time
num_seconds = 3
for countdown in reversed(range(num_seconds + 1)):
if countdown > 0:
print(countdown, end="...")
time.sleep(1)
else:
print("Go!")
As long as the countdown variable is greater than zero, the code keeps appending text without a trailing newline and then goes to sleep for one second. Finally, when the countdown is finished, it prints Go! and terminates the line.
Unexpectedly, instead of counting down every second, the program idles wastefully for three seconds, and then suddenly prints the entire line at once:
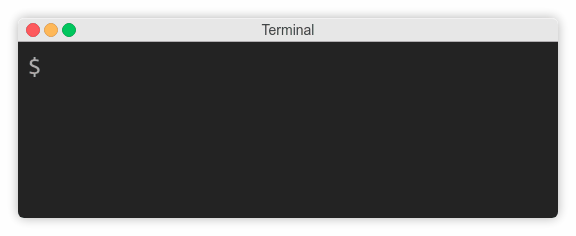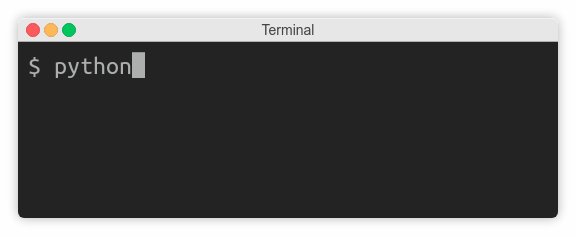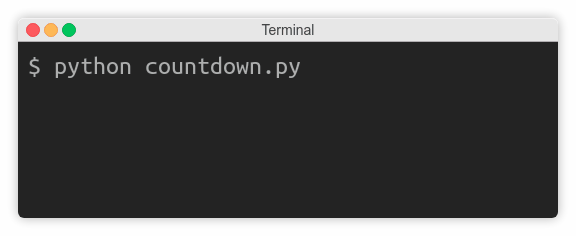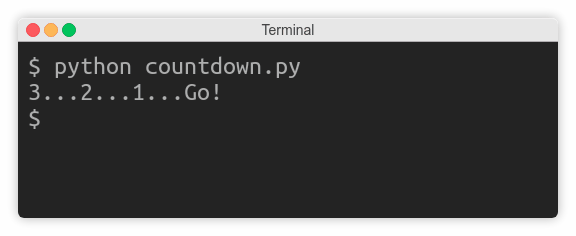
That’s because, in this case, the operating system buffers subsequent writes to the standard output. You need to know that there are three kinds of streams with respect to buffering:
- Unbuffered
- Line-buffered
- Block-buffered
Unbuffered is self-explanatory—no buffering is taking place, and all writes take immediate effect. A line-buffered stream waits before firing any I/O calls until a line break appears somewhere in the buffer, whereas a block-buffered one simply allows the buffer to fill up to a certain size regardless of its content.
Standard output is both line-buffered and block-buffered, depending on which event comes first. Buffering helps to reduce the number of expensive I/O calls. Think about sending messages over a high-latency network, for example.
When you connect to a remote server to execute commands over the SSH protocol, each of your keystrokes may actually produce an individual data packet, which is orders of magnitude bigger than its payload. What an overhead! It would make sense to wait until at least a few characters are typed and then send them together. That’s where buffering steps in.
On the other hand, buffering can sometimes have undesired effects as you just saw with the countdown example. To fix this, you can simply tell print() to forcefully flush the stream without waiting for a newline character in the buffer using its flush flag:
countdown.py
import time
num_seconds = 3
for countdown in reversed(range(num_seconds + 1)):
if countdown > 0:
print(countdown, end="...", flush=True)
time.sleep(1)
else:
print("Go!")
That’s it—your countdown should now work as expected. Give it a try and see the difference for yourself!
Congratulations. By now, you’ve seen examples of calling print() that cover all of its parameters. You know their purpose and when to use them. However, understanding the function’s signature is just the beginning. In the upcoming sections, you’ll see why.
Printing Custom Data Types
Up until now, you’ve only dealt with built-in data types such as strings and numbers, but you’ll often want to print objects of your own data types. Typically, you define custom data types in Python using one of the following tools:
Named tuples are great for simple objects without any logic whose purpose is to carry a sequence of values. When printed, they automatically display a clean, readable text representation:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age")
>>> jdoe = Person("John Doe", 42)
>>> print(jdoe)
Person(name='John Doe', age=42)
That’s great as long as holding data is all you need. But, in order to add behaviors to your Person type, you’ll prefer implementing it as a subclass of typing.NamedTuple, which is a typed flavor of namedtuple:
>>> from typing import NamedTuple
>>> class Person(NamedTuple):
... name: str
... age: int
...
... def greet(self):
... print(f"My name's {self.name}, and I'm {self.age} years old.")
...
>>> jdoe = Person("John Doe", 42)
>>> jdoe.greet()
My name's John Doe, and I'm 42 years old.
>>> print(jdoe)
Person(name='John Doe', age=42)
Here, you use type hints to specify the class fields, .name and .age. Using the class keyword means you now have a class body where you can define custom methods to perform actions like printing a greeting message. At the same time, you get the same string representation as before for free.
That’s better than a plain namedtuple because not only do you get printing for free, but you can also add custom methods and properties to the class. However, it solves one problem while introducing another. Remember that tuples, including named tuples, are immutable in Python, so they can’t change their values once created:
>>> jdoe.age += 1
Traceback (most recent call last):
File "<python-input-5>", line 1, in <module>
jdoe.age += 1
^^^^^^^^
AttributeError: can't set attribute
It’s true that designing immutable data types is generally desirable, but in many cases, you’ll want them to allow for change. Fortunately, Python has data classes, which you can think of as mutable tuples. This way, you get the best of both worlds.
Here’s how you can implement your Person type as a mutable data class:
>>> from dataclasses import dataclass
>>> @dataclass
... class Person:
... name: str
... age: int
...
... def celebrate_birthday(self):
... self.age += 1
...
>>> jdoe = Person("John Doe", 42)
>>> jdoe.celebrate_birthday()
>>> print(jdoe)
Person(name='John Doe', age=43)
Although this code looks nearly identical to the NamedTuple example you saw earlier, it allows you to modify the state of a person. This wouldn’t have been possible with a named tuple, which doesn’t allow for in-place mutation of its elements.
Note: Mutability aside, the primary reason to choose a data class over a named tuple is when you’re modeling a type that is not inherently a sequence. After all, tuples are conceptually sequences of values, and there are ways to make data classes immutable.
Both named tuples and data classes are relatively new additions to Python. The traditional and most common way of specifying custom data types has always been to use plain classes, which give you fine-grained control. Even today, you’ll frequently encounter them in many codebases.
Here’s the same Person type implemented as a standard Python class:
>>> class Person:
... def __init__(self, name, age):
... self.name = name
... self.age = age
...
Unfortunately, plain classes like this don’t have an appealing string representation by default. If you now create an instance of the Person class and try to print it, then you’ll get this bizarre output:
>>> jdoe = Person("John Doe", 42)
>>> print(jdoe)
<__main__.Person object at 0x78ec55f50ec0>
This is Python’s default object representation. It includes the object’s memory address, the class name, and the module in which it was defined.
As you learned earlier, print() implicitly calls the built-in str() function to convert its positional arguments into strings. Indeed, calling str() manually against an instance of the regular Person class yields the same result as printing it:
>>> str(jdoe)
'<__main__.Person object at 0x78ec55f50ec0>'
The str() function, in turn, looks for one of two special methods—also known as magic methods—within the class body, which you typically implement yourself. If it doesn’t find one, then it falls back to that ugly default representation you just saw. Those special methods are, in order of search:
The first one is expected to return a short, human-readable text, which includes information stored in the most relevant attributes. You don’t always want to include all attributes when printing objects to avoid exposing sensitive data, such as user passwords.
The other special method should provide complete information about an object, ideally to allow for restoring its state from a string. In that case, it should return valid Python code, so that you can pass it directly to eval(), like so:
>>> repr(jdoe)
"Person(name='John Doe', age=42)"
>>> type(eval(repr(jdoe)))
<class '__main__.Person'>
Notice the use of another built-in function, repr(), which always tries to call .__repr__() in an object, but falls back to the default representation if it doesn’t find that method.
Note: To better understand the distinction between these two methods, you can check out When Should You Use .__repr__() vs .__str__() in Python?
Here’s how you might implement one of these special methods in your Person class to provide a meaningful string representation of the object:
>>> class Person:
... def __init__(self, name, age):
... self.name = name
... self.age = age
...
... def __str__(self):
... class_name = type(self).__name__
... return f"{class_name}(name={self.name!r}, age={self.age!r})"
...
>>> jdoe = Person("John Doe", 42)
>>> print(jdoe)
Person(name='John Doe', age=42)
After obtaining the class name dynamically, you use an f-string to format the output string, ensuring that the .name and .age attributes are clearly displayed.
Note: Even though print() itself uses str() for typecasting, some compound data types delegate that call to repr() on their members. For example, this happens to lists and tuples.
Consider this class with both special methods, which return alternative string representations of the same object:
class User:
def __init__(self, login, password):
self.login = login
self.password = password
def __str__(self):
return self.login
def __repr__(self):
return f"User({self.login!r}, {self.password!r})"
If you print a single object of the User class, then you won’t see the password because print(user) will call str(user), which eventually invokes user.__str__():
>>> user = User("jdoe", "s3cret")
>>> print(user)
jdoe
However, if you put the same user variable inside a list by wrapping it in square brackets, then the password will become clearly visible:
>>> print([user])
[User('jdoe', 's3cret')]
That’s because sequences, such as lists and tuples, implement their .__str__() method so that all of their elements are first converted with repr().
Python gives you a lot of freedom when it comes to defining your own data types if none of the built-in ones meet your needs. Some of them, such as named tuples and data classes, offer string representations that look good without requiring any work on your part. Still, for the most flexibility, you’ll need to define a class and override the special methods described above.
Understanding Python print()
You know how to use print() quite well at this point, but getting a deeper understanding of what it is will allow you to use it even more effectively and consciously. After reading this section, you’ll understand how printing in Python has improved over the years.
From Statement to Function
In legacy Python versions, print was a statement rather than a function. Although print() is now a function, some people still refer to it as the “print statement” out of habit, which is technically an outdated term. This syntactical change aligns with Python’s philosophy of treating most operations as functions thanks to their many benefits, which you’ll learn about in the next section.
Okay, so print() is a function in Python. More specifically, it’s a built-in function, which means that you don’t need to import it from anywhere:
>>> print
<built-in function print>
It’s always available in the global namespace so that you can call it directly, but you can also access it through the builtins module from the standard library:
>>> import builtins
>>> builtins.print
<built-in function print>
>>> builtins.print("Hello, World!")
Hello, World!
This way, you can avoid name collisions with custom functions. Say you wanted to redefine print() so that it doesn’t append a trailing newline, while also preserving the original function under a new name like println():
>>> import builtins
>>> println = builtins.print
>>> def print(*args, **kwargs):
... builtins.print(*args, **kwargs, end="")
...
>>> println("Hello, World!")
Hello, World!
>>> print("Hello, World!\n")
Hello, World!
Now you have two separate printing functions just like in the Java programming language. You’ll define custom print() functions in the mocking section later as well. Also, keep in mind that you wouldn’t be able to overwrite print() in the first place if it weren’t a function.
On the other hand, print() isn’t a function in the mathematical sense, because it doesn’t return any meaningful value other than the implicit None:
>>> value = print("Hello, World!")
Hello, World!
>>> print(value)
None
Such functions are, in fact, procedures or subroutines that you call to achieve some kind of side effect, which ultimately is a change of global state. In the case of print(), that side effect is showing a message on the standard output or writing to a file.
Benefits of Functions
Because print() is a function, it has a well-defined signature with known attributes. You can quickly find its documentation using the editor of your choice, without having to remember some weird syntax for performing a certain task.
Besides, functions are easier to extend. Adding a new feature to a function is as easy as adding another keyword argument, whereas changing the language to support that new feature is much more cumbersome. Think of stream redirection or buffer flushing, for example.
Another benefit of print() being a function is composability. Functions are so-called first-class objects or first-class citizens in Python, which is a fancy way of saying they’re values just like strings or numbers. This way, you can assign a function to a variable, pass it to another function, or even return one from another. print() isn’t different in this regard. For instance, you can take advantage of it for dependency injection:
def download(url, log=print):
log(f"Downloading {url}")
# ...
def suppress_print(*args):
pass # Do not print anything
download("/js/app.js", log=suppress_print)
Here, the log parameter lets you inject a callback function, which defaults to print() but can be any callable. In this example, printing is completely disabled by substituting print() with a dummy function that does nothing.
Note: A dependency is any piece of code required by another bit of code.
Composition allows you to combine a few functions into a new one of the same kind. You’ll see this in action by specifying a custom error() function below that prints to the standard error stream and prefixes all messages with a given log level:
>>> import sys
>>> from functools import partial
>>> redirect = lambda function, stream: partial(function, file=stream)
>>> prefix = lambda function, prefix: partial(function, prefix)
>>> error = prefix(redirect(print, sys.stderr), "[ERROR]")
>>> error("Something went wrong")
[ERROR] Something went wrong
The custom error() function is built with partial functions to achieve the desired effect. It’s an advanced concept borrowed from the functional programming paradigm, so you don’t need to go too deep into that for now. However, if you’re interested in this topic, then take a look at the functools module.
Unlike statements, functions are values. That means you can mix them with expressions, in particular, lambda expressions. So instead of defining a full-blown function to replace print(), you can use an anonymous lambda expression that calls it directly:
>>> download("/js/app.js", lambda message: print("[INFO]", message))
[INFO] Downloading /js/app.js
However, because a lambda expression is defined in place, there’s no way of referring to it elsewhere in the code. This only makes sense when you don’t intend to reuse your anonymous function.
Note: In Python, you can’t put statements, such as assignments, conditional statements, loops, and so on, in an anonymous lambda function. Lambda functions must contain a single expression.
As you can see, functions allow for an elegant and extensible solution, which is consistent with the rest of the language. Because print() is a function, it offers a lot of flexibility in how you can adapt it to your printing needs.
Printing With Style
If you think that printing is only about lighting up pixels on the screen, then technically, you’d be right. However, there are ways to make it look cool. In this section, you’ll find out how to format complex data structures, add colors and other decorations, build text-based user interfaces (TUIs), use animation, and even play sounds with text!
Pretty-Printing Nested Data Structures
Computer languages allow you to present data as well as executable code in a structured way. Unlike Python, most languages give you a lot of freedom in using whitespace and formatting. This can be useful, for example, in data compression, but it can sometimes lead to less readable code.
Pretty-printing is about making a piece of data or code look more appealing to the human eye so that it can be understood more easily. This is done by indenting certain lines, inserting newlines, reordering elements, and so forth.
Python comes with the pprint module in its standard library, which will help you prettify large data structures that don’t fit on a single line. Because it prints in a more human-friendly way, many popular REPL tools, including JupyterLab and IPython, use it by default instead of the regular print() function.
Note: To toggle pretty printing in IPython, issue the following command:
In [1]: %pprint
Pretty printing has been turned OFF
In [2]: %pprint
Pretty printing has been turned ON
This is an example of magic commands in IPython. There are a lot of built-in commands that start with a percent sign (%), but you can find more on PyPI or even create your own.
If you don’t mind losing access to the original print() function globally, then you can replace it with pprint() in your code using import renaming:
>>> from pprint import pprint as print
>>> print
<function pprint at 0x7f7a775a3510>
Now, calling print() will effectively delegate to pprint(). To use the prettified version only occasionally, you can reassign print() to pprint() within a scope of a custom function:
>>> from pprint import pprint
>>> def function():
... print = pprint
... print(print)
...
>>> function()
<function pprint at 0x730ff4de4040>
>>> print(print)
<built-in function print>
Depending on where in your code you call print(), you’ll either call the original print() function that shipped with Python or the one from the pprint module.
To always have both functions at your fingertips, you might want to explicitly import pprint() or its short alias, pp():
>>> from pprint import pp
At first glance, there’s hardly any difference between print() and pprint()—or its pp() alias—and in some cases, there’s virtually none:
>>> print(42)
42
>>> pp(42)
42
>>> print("hello")
hello
>>> pp("hello")
'hello'
Printing a number with print() and pp() looks identical, but the string looks different. That’s because pp() calls repr() instead of the usual str() for typecasting. This ensures a consistent representation of deeply nested data structures.
The differences become more apparent as you start feeding pp() more complex data structures:
>>> data = {"powers": [x**10 for x in range(10)]}
>>> pp(data)
{'powers': [0,
1,
1024,
59049,
1048576,
9765625,
60466176,
282475249,
1073741824,
3486784401]}
The function applies reasonable formatting to improve readability, but you can customize it even further with a couple of parameters. For example, you may limit a deeply nested hierarchy by displaying an ellipsis below a given level:
>>> cities = {"USA": {"Texas": {"Dallas": ["Irving"]}}}
>>> pp(cities, depth=3)
{"USA": {"Texas": {"Dallas": [...]}}}
The ordinary print() function also uses ellipses but for displaying recursive data structures, which form a cycle, to avoid a stack overflow error:
>>> items = [1, 2, 3]
>>> items.append(items)
>>> print(items)
[1, 2, 3, [...]]
However, pp() is more explicit about it by including the unique identity of a self-referencing object:
>>> pp(items)
[1, 2, 3, <Recursion on list with id=140635757287688>]
>>> id(items)
140635757287688
The last element in the list is the same object as the entire list.
Note: Recursive or very large datasets can be dealt with using the reprlib module as well:
>>> import reprlib
>>> reprlib.repr([x**10 for x in range(10)])
'[0, 1, 1024, 59049, 1048576, 9765625, ...]'
This module supports most of the built-in types and is used by the Python debugger.
pp() automatically sorts dictionary keys for you before printing, which allows for consistent comparison. When you’re comparing strings, you often don’t care about a particular order of serialized attributes. Still, it’s always best to compare actual dictionaries before serializing them.
Dictionaries often represent JSON data, which is widely used on the internet. To correctly serialize a dictionary into a valid JSON-formatted string, you can take advantage of the json module. It too has pretty-printing capabilities:
>>> import json
>>> data = {"username": "jdoe", "password": "s3cret"}
>>> ugly = json.dumps(data)
>>> pretty = json.dumps(data, indent=4, sort_keys=True)
>>> print(ugly)
{"username": "jdoe", "password": "s3cret"}
>>> print(pretty)
{
"password": "s3cret",
"username": "jdoe"
}
Notice, however, that you need to handle printing yourself because json.dumps() merely returns a Python string. Similarly, the pprint module has an additional pformat() function that also returns a string, in case you need to do something other than print it.
Surprisingly, the signature of pp() is quite different from that of the print() function:
pp(
object,
stream=None,
indent=1,
width=80,
depth=None,
*,
compact=False,
sort_dicts=False,
underscore_numbers=False
)
Apart from the first positional argument, object, you can’t pass more than one value to pp() for printing. This shows how much the function focuses on printing data structures.
To unlock even more powerful ways to print with style in Python, you might want to look into other techniques.
Adding Colors With ANSI Escape Sequences
As personal computers became more sophisticated, they had better graphics and could display more colors. However, different vendors had their own ideas about the API design for controlling it. That changed a few decades ago when the American National Standards Institute introduced ANSI escape codes to standardize text formatting and color across terminals.
Most of today’s terminal emulators support this standard to some degree. Until recently, the Windows operating system was a notable exception. Therefore, if you want the best portability, use a third-party Python library like colorama. It translates ANSI codes to their appropriate counterparts in Windows while keeping them intact in other operating systems.
To check if your terminal understands a subset of the ANSI escape sequences, such as those related to colors, you can try using the following command:
$ tput colors
256
The default terminal on some Linux distributions (GNOME Terminal) says it can display 256 distinct colors, while xterm supports only eight. The command above would return a negative number if colors were unsupported.
ANSI escape sequences are like a markup language for the terminal. In HTML, you work with tags, such as <b> or <i>, to change how elements look in the document. These tags are mixed with your content, but they’re not visible themselves. Similarly, escape codes won’t show up in the terminal as long as it recognizes them. Otherwise, they’ll appear in the literal form as if you were viewing the source of a website.
As its name implies, a sequence must begin with the non-printable Esc character, whose ASCII value is 27, sometimes denoted as 0x1b in hexadecimal or 033 in octal. You may use Python number literals to quickly verify that it’s indeed the same number:
>>> 27 == 0x1b == 0o33
True
Additionally, you can obtain it using the \e escape sequence in the shell:
$ echo -e "\e"
The most common ANSI escape sequences take the following form:
| Element | Description | Example |
|---|---|---|
| Esc | Non-printable escape character | \033 |
[ |
Opening square bracket | [ |
| Numeric code | One or more numbers separated with ; |
0 |
| Character code | Uppercase or lowercase letter | m |
The numeric code can be one or more numbers separated with a semicolon, while the character code is just one letter. Their specific meaning is defined by the ANSI standard. For example, to reset all formatting, you would type one of the equivalent commands below, which use the code zero and the letter m:
$ echo -e "\e[0m"
$ echo -e "\x1b[0m"
$ echo -e "\033[0m"
At the other end of the spectrum, you have compound code values. To set foreground and background with RGB channels, given that your terminal supports 24-bit depth, you could provide multiple numbers:
$ echo -e "\e[38;2;0;0;0m\e[48;2;255;255;255mBlack on white\e[0m"
It’s not just text color that you can set with the ANSI escape codes. You can, for example, clear and scroll the terminal window, change its background, move the cursor around, make the text blink, or decorate it with an underline.
In Python, you’d probably write a helper function to allow for wrapping arbitrary codes into a sequence:
>>> def esc(*codes):
... return f"\033[{';'.join(str(code) for code in codes)}m"
...
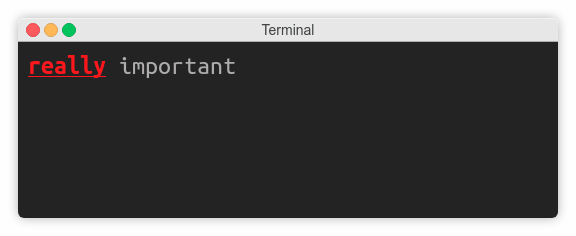
>>> print(esc(31, 1, 4) + "really" + esc(0) + " important")
This would make the word really appear in red (31), bold (1), and underlined (4) font:
However, there are higher-level abstractions over ANSI escape codes, such as the mentioned colorama library, as well as tools for building full-fledged user interfaces in the console.
Building Console User Interfaces
While playing with ANSI escape codes can be a ton of fun, in the real world, you’ll eventually want more abstract building blocks to create a user interface. If you’re building a business application, then check out Rich and Textual, which offer typical graphical widgets. However, for the ultimate control over the terminal, curses seems to be the most popular choice.
Note: To use the curses library in Windows, you need to install a third-party package:
PS> python -m pip install windows-curses
That’s because curses isn’t available in the standard library of the Python distribution for Windows.
Primarily, it allows you to think in terms of independent graphical widgets instead of a blob of text. Besides, you get a lot of freedom in expressing your inner artist, because it’s really like painting a blank canvas. The library hides the complexities of having to deal with different terminals. Other than that, it has great support for keyboard events, which might be useful for writing video games.
How about making a retro snake game? You’re about to create a Python snake simulator:
First, you need to import the curses module. Since it modifies the state of a running terminal, it’s important to handle errors and restore the previous state gracefully. You can do this manually, but the library comes with a convenient wrapper for your main function:
snake.py
import curses
def main(screen):
pass
if __name__ == "__main__":
curses.wrapper(main)
Note that your main() function accepts a reference to the main window object, also known as stdscr, which you’ll use later for additional setup.
If you run this program now, you won’t see any effects because it terminates immediately. However, you can add a small delay to have a sneak peek:
snake.py
import curses
import time
def main(screen):
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
This time, the screen went completely blank for a second, but the cursor was still blinking. To hide it, just call one of the configuration functions defined in the module:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
Define the snake as a list of points in screen coordinates, which are row-column (y, x) and originate in the top-left corner:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
snake = [(0, i) for i in reversed(range(20))]
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
The head of the snake is always the first element in the list, whereas the tail is the last one. The initial shape of the snake is horizontal, starting from the top-left corner of the screen and facing right. While its y-coordinate stays at zero, its x-coordinate decreases from head to tail:
[(0, 19), (0, 18), (0, 17), ..., (0, 0)]
To draw the snake, you’ll start with the head (@) and then follow with the remaining segments (*). Each segment carries (y, x) coordinates, so you can unpack them:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
snake = [(0, i) for i in reversed(range(20))]
# Draw the snake
screen.addstr(*snake[0], "@")
for segment in snake[1:]:
screen.addstr(*segment, "*")
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
Again, if you run this code now, it won’t display anything, because you need to explicitly refresh the screen afterward:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
snake = [(0, i) for i in reversed(range(20))]
# Draw the snake
screen.addstr(*snake[0], "@")
for segment in snake[1:]:
screen.addstr(*segment, "*")
screen.refresh()
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
You want to move the snake in one of four directions, which can be defined as vectors. Eventually, the direction will change in response to an arrow keystroke, so you can hook it up to the library’s key codes:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
directions = {
curses.KEY_UP: (-1, 0),
curses.KEY_DOWN: (1, 0),
curses.KEY_LEFT: (0, -1),
curses.KEY_RIGHT: (0, 1),
}
direction = directions[curses.KEY_RIGHT]
snake = [(0, i) for i in reversed(range(20))]
# Draw the snake
screen.addstr(*snake[0], "@")
for segment in snake[1:]:
screen.addstr(*segment, "*")
screen.refresh()
time.sleep(1)
if __name__ == "__main__":
curses.wrapper(main)
How does a snake move? It turns out that only its head really moves to a new location, while all other segments shift toward it. In each step, almost all segments remain the same, except for the head and the tail. Assuming the snake isn’t growing, you can remove the tail and insert a new head at the beginning of the list:
# Move the snake
snake.pop()
snake.insert(0, tuple(map(sum, zip(snake[0], direction))))
To get the new coordinates of the head, you need to add the direction vector to it. However, adding tuples in Python results in a bigger tuple instead of the algebraic sum of the corresponding vector components. One way to fix this is by using the built-in zip(), sum(), and map() functions.
The direction will change on a keystroke, so you need to call .getch() to obtain the pressed key code. However, if the pressed key doesn’t correspond to the arrow keys defined earlier as dictionary keys, the direction won’t change:
# Change direction on arrow keystroke
direction = directions.get(screen.getch(), direction)
By default, however, .getch() is a blocking call that would prevent the snake from moving unless there was a keystroke. Therefore, you need to make the call non-blocking by adding yet another configuration:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
screen.nodelay(True) # Don't block I/O calls
# ...
# ...
You’re almost done, but there’s just one last thing left. If you loop this code now, the snake will appear to be growing instead of moving. That’s because you have to erase the screen explicitly before each iteration.
Finally, this is all you need to play the snake game in Python:
snake.py
import curses
import time
def main(screen):
curses.curs_set(0) # Hide the cursor
screen.nodelay(True) # Don't block I/O calls
directions = {
curses.KEY_UP: (-1, 0),
curses.KEY_DOWN: (1, 0),
curses.KEY_LEFT: (0, -1),
curses.KEY_RIGHT: (0, 1),
}
direction = directions[curses.KEY_RIGHT]
snake = [(0, i) for i in reversed(range(20))]
while True:
screen.erase()
# Draw the snake
screen.addstr(*snake[0], "@")
for segment in snake[1:]:
screen.addstr(*segment, "*")
# Move the snake
snake.pop()
snake.insert(0, tuple(map(sum, zip(snake[0], direction))))
# Change direction on arrow keystroke
direction = directions.get(screen.getch(), direction)
screen.refresh()
time.sleep(0.1)
if __name__ == "__main__":
curses.wrapper(main)
This is merely scratching the surface of the possibilities that the curses module opens up. You may use it for game development like this or more business-oriented applications.
Living It Up With Cool Animations
Not only can animations make the user interface more appealing to the eye, but they also improve the overall user experience. When you provide early feedback to the user, for example, they’ll know if your program’s still working or if it’s time to kill it.
To animate text in the terminal, you have to be able to freely move the cursor around. You can do this with one of the tools mentioned previously, such as ANSI escape codes or the curses library. However, there’s an even simpler way.
If the animation can be constrained to a single line of text, then you might be interested in two special escape character sequences:
- Carriage Return (
\r): Moves the cursor to the beginning of the line - Backspace (
\b): Moves the cursor one character to the left and deletes the character in that spot
The carriage return (CR) works in a non-destructive way, without overwriting text that’s already been written until you call print() again. In contrast, the backspace deletes the character to the left of the cursor, effectively removing it from the text.
You’ll now take a look at a few examples. For instance, you might want to display a spinning wheel to show that something’s in progress, even if you don’t know exactly how much time is left to finish:
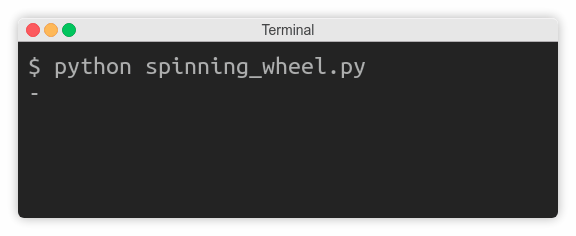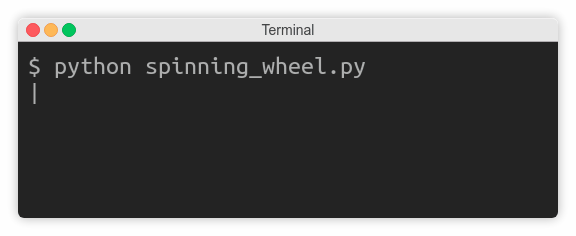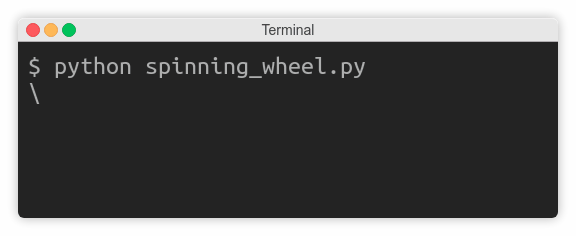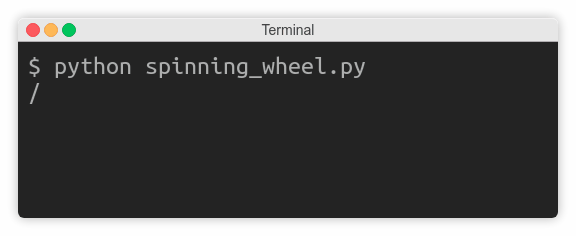
Many command-line tools use this trick while downloading data over the network. You can make a really simple stop-motion animation from a sequence of characters that will cycle in a round-robin fashion:
spinning_wheel.py
from itertools import cycle
from time import sleep
for frame in cycle(r"-\|/-\|/"):
print("\r", frame, sep="", end="", flush=True)
sleep(0.2)
The loop gets the next character to print, then moves the cursor to the beginning of the line and overwrites whatever there was before without adding a newline. You don’t want extra space between positional arguments, so the separator argument must be blank. Also, notice the use of Python’s raw strings due to backslash characters present in the literal.
When you know the remaining time or task completion percentage, then you’re able to show an animated progress bar:
First, you need to calculate how many hashtags to display and how many blank spaces to insert. Next, you erase the line and build the bar from scratch:
progress.py
from time import sleep
def progress(percent=0, width=30):
left = width * percent // 100
right = width - left
print("\r[", "#" * left, " " * right, "]",
f" {percent:.0f}%",
sep="", end="", flush=True)
for i in range(101):
progress(i)
sleep(0.1)
As before, each request for update repaints the entire line to reflect the current progress.
Note that there are powerful third-party libraries that allow you to display such progress bars in the terminal. A popular choice for simple progress tracking is the tqdm library. If you need more advanced text-based widgets, libraries like Rich and Textual are great options.
Making Sounds With print()
If you’re old enough to remember computers with a PC speaker, then you must also remember their distinctive beep sound, often used to indicate hardware problems. They could barely make any more noises beyond that, yet video games seemed so much better with it.
Today, you can still take advantage of this small loudspeaker, but chances are your laptop didn’t come with one. In such a case, you can enable terminal bell emulation in your shell so that a system warning sound is played instead.
Go ahead and type this command to see if your terminal can play a sound:
$ echo -e "\a"
This would normally print text, but the -e flag enables the interpretation of backslash escapes. As you can see, there’s a dedicated escape sequence \a, which stands for “alert”, that outputs a special bell character. Some terminals make a sound whenever they see it.
Similarly, you can print this character in Python. Perhaps in a loop to form some kind of melody. While it’s only a single note, you can still vary the length of pauses between consecutive instances. That seems like a perfect toy for Morse code playback!
The rules are the following:
- Letters are encoded with a sequence of dot (·) and dash (–) symbols.
- A dot is one unit of time.
- A dash is three units of time.
- Individual symbols in a letter are spaced one unit of time apart.
- Symbols of two adjacent letters are spaced three units of time apart.
- Symbols of two adjacent words are spaced seven units of time apart.
According to those rules, you could be “printing” an SOS signal indefinitely in the following way:
morse_code.py
# ...
while True:
dot(); symbol_space()
dot(); symbol_space()
dot(); letter_space()
dash(); symbol_space()
dash(); symbol_space()
dash(); letter_space()
dot(); symbol_space()
dot(); symbol_space()
dot(); word_space()
By using a semicolon (;), you can place multiple Python statements on a single line. Although this enhances readability in this particular example, it’s usually better to follow standard formatting practices for clarity.
You can implement the individual functions that appear in the example above in merely ten lines of code:
morse_code.py
from time import sleep
speed = 0.1
def signal(duration, symbol):
sleep(duration)
print(symbol, end="", flush=True)
dot = lambda: signal(speed, "·\a")
dash = lambda: signal(3*speed, "−\a")
symbol_space = lambda: signal(speed, "")
letter_space = lambda: signal(3*speed, "")
word_space = lambda: signal(7*speed, " ")
# ...
Maybe you could even take it one step further and make a command-line tool for translating text into Morse code? Hopefully, it sounds like a fun and rewarding challenge!
Mocking Python print() in Unit Tests
Nowadays, it’s expected that you ship code that meets high-quality standards. If you aspire to become a professional, you must learn how to test your code.
Software testing is especially important in dynamically typed languages, such as Python, which don’t have a compiler to warn you about obvious mistakes. Defects can make their way to the production environment and remain dormant for a long time, until that one day when a branch of code finally gets executed.
Sure, you have linters, type checkers, and other tools for static code analysis to assist you. But they won’t tell you whether your program does what it’s supposed to do on the business level.
So, should you be testing print()? No. After all, it’s a built-in function that must have already gone through a comprehensive suite of tests. What you want to test, though, is whether your code is calling print() at the right time with the expected parameters. In other words, you want to test the behavior of your code.
You can test behaviors by mocking real objects or functions. In this case, you want to mock print() to record and verify its invocations.
Note: You might have heard these terms used interchangeably:
- Dummy
- Fake
- Mock
- Spy
- Stub
Some people make a distinction between them, while others don’t. Martin Fowler explains their differences in a short glossary and collectively calls them “test doubles.”
You can approach mocking in Python from two angles: dependency injection or monkey patching. You’ll take a look at the first approach now.
Using Dependency Injection
You can take the traditional path of statically typed languages by employing dependency injection. This may sometimes require you to change the code under test, which isn’t always possible if the code is defined in an external library:
>>> def download(url, log=print):
... log(f"Downloading {url}")
... # ...
...
This function is consciously designed to allow for substituting print() with a custom function of a compatible interface. To check if calling download() results in printing the expected message, you have to intercept the output. You can do that by injecting a mocked logging function:
>>> def mock_print(message):
... mock_print.last_message = message
...
>>> download("favicon.ico", mock_print)
>>> assert "Downloading favicon.ico" == mock_print.last_message
Instead of printing the supplied message, your mock_print() function stores the most recent message in an attribute, .last_message, which you can inspect later. In a unit test, you’re likely to compare the actual message against the expected one using an assert statement.
Note: Dependency injection is a technique used in code design to make it more testable, reusable, and open for extension. You can achieve it by referring to dependencies indirectly through abstract interfaces and by providing them in a push rather than pull fashion.
There’s a funny explanation of dependency injection circulating on the internet:
Dependency injection for five-year-olds
When you go and get things out of the refrigerator for yourself, you can cause problems. You might leave the door open, you might get something Mommy or Daddy doesn’t want you to have. You might even be looking for something we don’t even have or which has expired.
What you should be doing is stating a need, “I need something to drink with lunch,” and then we will make sure you have something when you sit down to eat.
— John Munsch, 28 October 2009. (Source)
In a slightly alternative solution, instead of replacing the entire print() function with a custom wrapper, you could redirect the standard output to an in-memory stream of characters:
>>> def download(url, stream=None):
... print(f"Downloading {url}", file=stream)
... # ...
...
>>> import io
>>> memory_buffer = io.StringIO()
>>> download("app.js", memory_buffer)
>>> download("style.css", memory_buffer)
>>> memory_buffer.getvalue()
'Downloading app.js\nDownloading style.css\n'
This time, the function explicitly calls print(), but it exposes its file parameter to the outside world.
What if you don’t have control of the code under test, and it wasn’t designed with dependency injection in mind? You’ll find out how to handle that scenario next.
Applying Monkey Patching
A more Pythonic way of mocking objects takes advantage of the built-in mock module, which uses a technique called monkey patching. This derogatory name stems from it being a “dirty hack” that you can easily shoot yourself in the foot with. It’s less elegant than dependency injection but definitely quick and convenient.
What monkey patching does is alter implementation dynamically at runtime. Such a change is visible globally, so it may have unwanted consequences. In practice, however, patching only affects the code for the duration of test execution.
To mock print() in a test case, you’ll typically use the @patch decorator and specify a target for patching by referring to it with a fully qualified name, which includes the module name:
test_print.py
from unittest import TestCase
from unittest.mock import patch
class TestPrint(TestCase):
@patch("builtins.print")
def test_print(self, mock_print):
print("Not a real print()")
mock_print.assert_called_with("Not a real print()")
This will automatically create the mock for you and inject it to the test method. However, you need to declare that your test method accepts a mock now. The underlying mock object has lots of useful methods and attributes for verifying behavior.
Did you notice anything peculiar about that code snippet?
Despite injecting a mock to the method, you’re not calling it directly, although you could. That injected mock is only used to make assertions afterward and maybe to prepare the context before running the test.
In real life, mocking helps to isolate the code under test by removing dependencies such as a database connection. You rarely call mocks in a test, because that doesn’t make much sense. Rather, it’s other pieces of code that call your mock indirectly without knowing it.
Here’s what that means:
test_print.py
from unittest import TestCase
from unittest.mock import patch
class TestPrint(TestCase):
@patch("builtins.print")
def test_print(self, mock_print):
print("Not a real print()")
mock_print.assert_called_with("Not a real print()")
@patch("builtins.print")
def test_greet(self, mock_print):
greet("John")
mock_print.assert_called_with("Hello, John!")
def greet(name):
print(f"Hello, {name}!")
The code under test is a function that prints a greeting. Even though it’s a fairly simple function, you can’t test it easily because it doesn’t return a value. It has a side effect.
To eliminate that side effect, you need to mock the dependency out. Patching lets you avoid making changes to the original function, which can remain agnostic about print(). It thinks it’s calling print(), but in reality, it’s calling a mock you’re in total control of.
There are many reasons for testing software. One of them is looking for bugs. When you write tests, you often want to get rid of the print() function, for example, by mocking it away. Paradoxically, however, that same function can help you find bugs during a related process of debugging you’ll read about in the next section.
Debugging Approaches in Python
In this section, you’ll take a look at the available tools for debugging in Python—from the humble print() function, through the logging module, to a full-fledged debugger. After reading it, you’ll be able to decide which of them is the most suitable in a given situation.
Note: Debugging is the process of looking for the root causes of bugs or defects in software after they’ve been discovered, as well as taking steps to fix them. The term bug has an amusing story about the origin of its name.
Tracing
Also known as print debugging or caveman debugging, tracing is the most basic form of software troubleshooting. While a little bit old-fashioned, it’s still powerful and has its uses.
The idea is to follow the path of program execution until it stops abruptly, or gives incorrect results, to identify the exact instruction with a problem. You do that by inserting print calls with special markers to catch your eye in carefully chosen places.
Take a look at this example, which manifests a rounding error:
>>> def average(numbers):
... if len(numbers) > 0:
... return sum(numbers) / len(numbers)
...
>>> average([0.2, 0.1])
0.15000000000000002
For the two input values, 0.2 and 0.1, the function returns a result close to the expected 0.15 but with a slight offset. To investigate the origin of this discrepancy, you can insert print() calls at key locations within the function, tracing intermediate calculations:
>>> def average(numbers):
... print("debug1:", numbers)
... if len(numbers) > 0:
... print("debug2:", sum(numbers))
... return sum(numbers) / len(numbers)
...
>>> average([0.2, 0.1])
debug1: [0.2, 0.1]
debug2: 0.30000000000000004
0.15000000000000002
Now you can clearly see that the function calculates the sum of the input numbers incorrectly. This is due to the inherent imprecision of floating-point arithmetic in computers. Remember that numbers are stored in binary form. The decimal value of 0.1 turns out to have an infinite binary representation, which gets rounded off.
Note: For more information on rounding numbers in Python, you can check out How to Round Numbers in Python.
Tracing the state of variables at different steps of the algorithm can give you a hint where the issue is. This method is simple and intuitive and will work in pretty much every programming language out there. Not to mention, it’s a great exercise in the learning process.
On the other hand, once you master more advanced techniques, it’s hard to go back, because they allow you to find bugs much quicker. Tracing is a laborious manual process, which can allow even more errors to slip through. The build and deploy cycle takes time. Afterward, you need to remember to meticulously remove all the print() calls you made without accidentally touching the genuine ones.
Besides, it requires you to make changes in the code, which isn’t always possible. Maybe you’re debugging an application running on a remote web server or trying to diagnose a problem in a post-mortem fashion. Sometimes you simply don’t have access to the standard output.
That’s precisely where logging shines since it lets you capture detailed information about the application’s execution without needing to modify the code directly. You’ll explore this technique next.
Logging
Pretend for a minute that you’re running an e-commerce website. One day, an angry customer calls to complain about a failed transaction, saying that he lost his money. He claims to have tried purchasing a few items, but in the end, there was some cryptic error that prevented him from finishing the order. Yet, when he checked his bank account, the money was gone.
You apologize sincerely and make a refund, but also don’t want this to happen again in the future. How do you debug that? If only you had some trace of what happened, ideally in the form of a chronological list of events with their context.
Whenever you find yourself doing print debugging, consider turning it into permanent log messages. This may help in situations like this, when you need to analyze a problem after it happened, in an environment that you don’t have access to.
Note: To learn more about logging in Python, check out these resources:
There are sophisticated tools for log aggregation and searching, but at the most basic level, you can think of logs as text files. Each line conveys detailed information about an event in your system. Usually, it won’t contain personally identifying information, though, in some cases, it may be mandated by law.
Here’s a breakdown of a typical log record:
[2019-06-14 15:18:34,517][DEBUG][root][MainThread] Customer(id=123) logged out
As you can see, it has a structured form. Apart from a descriptive message, there are a few customizable fields that provide the context of an event. Here, you have the exact date and time, the log level, the logger name, and the thread name.
Log levels allow you to filter messages quickly to reduce noise. For example, if you’re looking for an error, then you don’t want to see all the warnings or debug messages. It’s trivial to disable or enable messages at certain log levels through the configuration, without even touching the code.
With logging, you can keep your debug messages separate from the standard output. All the log messages go to the standard error stream by default, which can conveniently show up in different colors. However, you can redirect log messages to separate files, even for individual modules!
Quite commonly, misconfigured logging can lead to running out of space on the server’s disk. To prevent this, you may set up log rotation, which will keep the log files for a specified duration, such as one week, or until they hit a certain size. Nevertheless, it’s always a good practice to archive older logs. Some regulations enforce that customer data be kept for as long as several years!
Compared to other programming languages, logging in Python is straightforward because the logging module is bundled with the standard library. You just import and configure it in as little as two lines of code:
>>> import logging
>>> logging.basicConfig(level=logging.DEBUG)
You can call functions defined at the module level, which are hooked to the root logger, but the common practice is to obtain a dedicated logger for each of your Python source files:
>>> logging.debug("This is a debug message from the root logger")
DEBUG:root:This is a debug message from the root logger
>>> logger = logging.getLogger(__name__)
>>> logger.debug("This is a debug message from the dedicated logger")
DEBUG:__main__:This is a debug message from the dedicated logger
The advantage of using custom loggers is that they give you more fine-grained control. They’re usually named after the module they were defined in through the __name__ variable.
Note: There’s a somewhat related warnings module in Python, which can also log messages to the standard error stream. However, it has a narrower spectrum of applications, mostly in library code, whereas client applications should use the logging module.
That said, you can make them work together by calling logging.captureWarnings(True).
One last reason to switch from the print() function to logging is thread safety. In an upcoming section, you’ll see that the former doesn’t play well with multiple threads of execution.
Debugging
The truth is that neither tracing nor logging can be considered real debugging. To do actual debugging, you need a debugger, which is a tool that allows you to do the following:
- Step through the code interactively.
- Set breakpoints, including conditional breakpoints.
- Introspect variables in memory.
- Evaluate custom expressions at runtime.
A crude debugger that runs in the terminal, unsurprisingly named pdb for “The Python Debugger,” is distributed as part of the standard library. This makes it always available, so it may be your only choice for performing remote debugging. Perhaps that’s a good reason to get familiar with it.
However, it doesn’t come with a graphical interface, so using pdb may be a bit tricky. If you can’t edit the code, then you have to run pdb as a Python module using the -m option and pass your script’s location as a command-line argument:
$ python -m pdb my_script.py
Otherwise, you can set up a breakpoint directly in the code, which will pause the execution of your script and drop you into the debugger. The old way of doing this required two steps:
>>> import pdb
>>> pdb.set_trace()
> <python-input-1>(1)<module>()
(Pdb)
This shows up an interactive prompt, which might look intimidating at first. However, you can still type native Python at this point to examine or modify the state of local variables. Apart from that, there’s really only a handful of debugger-specific commands that you want to use for stepping through the code.
Note: It’s customary to put the two instructions for spinning up a debugger on a single line. This requires the use of a semicolon, which is rarely found in Python programs:
import pdb; pdb.set_trace()
While certainly not Pythonic, it stands out as a reminder to remove it after you’re done with debugging.
You can also call the built-in breakpoint() function, which does the same thing, but in a more compact way and with some additional bells and whistles:
>>> def average(numbers):
... if len(numbers) > 0:
... breakpoint()
... return sum(numbers) / len(numbers)
...
>>> average([0.2, 0.1])
> <python-input-0>(3)average()
(Pdb)
You’re probably going to use a visual debugger integrated with a code editor for the most part. PyCharm has an excellent debugger that boasts high performance, but you’ll find plenty of alternative IDEs with debuggers, both paid and free of charge.
Debugging isn’t the proverbial silver bullet. Sometimes, logging or tracing will be a better solution. For example, defects that are hard to reproduce, such as race conditions, often result from temporal coupling. When you stop at a breakpoint, that little pause in program execution may mask the problem. It’s kind of like the Heisenberg principle: you can’t measure and observe a bug at the same time.
The bottom line is that these methods aren’t mutually exclusive—they complement each other.
Printing in a Thread-Safe Manner
You briefly touched upon the thread safety issue before, when it was recommended to use logging over the print() function. This helps you avoid garbled output when working with more than one thread of execution that needs to display text. To follow along with this section, you should be comfortable with the concept of threads.
Understanding Thread Safety
Thread safety means that a piece of code can be safely shared between multiple threads of execution. The simplest strategy for ensuring thread safety is by sharing immutable objects only. If threads can’t modify an object’s state, then there’s no risk of breaking its consistency.
Another method takes advantage of local memory, which makes each thread receive its own copy of the same object. That way, other threads can’t see the changes made to it in the current thread.
But that doesn’t solve the problem, does it? You often want your threads to cooperate by being able to mutate a shared resource. The most common way of synchronizing concurrent access to such a resource is by using locks. They give exclusive write access to one or sometimes a few threads at a time.
However, locking is expensive and reduces concurrent throughput, so other means for controlling access have been invented, such as atomic variables or the compare-and-swap algorithm. In this section, you’ll leverage locking to make calls to print() thread-safe due to its simplicity.
Demonstrating Unsafe Printing
Printing isn’t thread-safe in Python. The print() function holds a reference to the standard output, which is a shared global variable. In theory, because there’s no locking, a context switch could happen during a call to sys.stdout.write(), intertwining bits of text from multiple print() calls.
Note: A context switch means that one thread halts its execution, either voluntarily or not, so that another one can take over. This might happen at any moment, even in the middle of a function call.
In practice, however, that doesn’t happen. No matter how hard you try, writing to the standard output with print() seems to be atomic. The only problem that you may sometimes observe is with messed up line breaks:
[Thread-3 A][Thread-2 A][Thread-1 A]
[Thread-3 B][Thread-1 B]
[Thread-1 C][Thread-3 C]
[Thread-2 B]
[Thread-2 C]
To simulate this, you can increase the likelihood of a context switch by making the underlying .write() method go to sleep for a random amount of time. How? By mocking it, which you already know about from an earlier section:
threads_simulation.py
import sys
from random import random
from threading import Thread, current_thread
from time import sleep
from unittest.mock import patch
write = sys.stdout.write
def slow_write(text):
sleep(random())
write(text)
def task():
thread_name = current_thread().name
for letter in "ABC":
print(f"[{thread_name} {letter}]")
with patch("sys.stdout") as mock_stdout:
mock_stdout.write = slow_write
for i in range(1, 4):
Thread(target=task, name=f"Thread-{i}").start()
First, you store the original .write() method in a global variable, which you delegate to later in your slow_write() function. Then, you provide your fake implementation to the mock object, which takes up to one second to execute. Each thread makes a few print() calls with its name and a letter: A, B, and C.
If you read the mocking section before, then you may already have an idea of why printing misbehaves like that. Nonetheless, to make it crystal clear, you can capture values fed into your slow_write() function. When you do, you’ll notice that you get a slightly different sequence with each run:
[
'[Thread-3 A]',
'[Thread-2 A]',
'[Thread-1 A]',
'\n',
'\n',
'[Thread-3 B]',
# ...
]
Even though sys.stdout.write() itself is an atomic operation, a single call to the print() function can yield more than one write. For example, line breaks are written separately from the rest of the text, and context switching takes place between those writes.
Note: The atomic nature of the standard output in Python is a byproduct of the Global Interpreter Lock, which applies locking around bytecode instructions. Be aware, however, that many interpreter flavors don’t have the GIL, where multi-threaded printing requires explicit locking.
Now that you know what causes the erratic behavior of the print() function in a multi-threaded environment, you can tackle the underlying issue directly. In the next section, you’ll enforce print() to invoke sys.stdout.write() only once per call, preventing output interleaving.
Fixing the Problem
To address the problem of concurrent printing, you can make the newline character become an integral part of the message by handling it manually:
threads_simulation.py
# ...
def task():
thread_name = current_thread().name
for letter in "ABC":
print(f"[{thread_name} {letter}]\n", end="")
# ...
You’ve appended the newline character (\n) to the message. Simultaneously, you’ve set the end parameter to an empty string (""), disabling the newline that print() would add automatically. This fixes the output:
[Thread-2 A]
[Thread-1 A]
[Thread-3 A]
[Thread-1 B]
[Thread-3 B]
[Thread-2 B]
[Thread-1 C]
[Thread-2 C]
[Thread-3 C]
Notice, however, that the print() function still keeps making a separate call for the empty suffix, which translates to useless sys.stdout.write("") instructions:
[
'[Thread-2 A]\n',
'[Thread-1 A]\n',
'[Thread-3 A]\n',
'',
'',
'',
'[Thread-1 B]\n',
# ...
]
Next, you’ll work around this issue by ensuring that only one thread can call print() at any given time.
Making print() Thread-Safe
A truly thread-safe version of the print() function would leverage explicit locking, like this:
thread_safe_print.py
import threading
lock = threading.Lock()
def thread_safe_print(*args, **kwargs):
with lock:
print(*args, **kwargs)
You’ve defined a wrapper function, which calls print() under the surface with the supplied positional and keyword arguments. At the same time, it fences the call to print() within a critical section, ensuring that only one thread can print at a time. The with statement leverages Python’s context manager to acquire and release the lock automatically at the right time.
You can import your custom function and use it in place of the standard print():
>>> from threading import Thread, current_thread
>>> from thread_safe_print import thread_safe_print
>>> def task():
... thread_name = current_thread().name
... for letter in "ABC":
... thread_safe_print(f"[{thread_name} {letter}]")
...
>>> for i in range(1, 4):
... Thread(target=task, name=f"Thread-{i}").start()
...
[Thread-3 A]
[Thread-1 B]
[Thread-1 C]
[Thread-2 A]
[Thread-2 B]
[Thread-2 C]
[Thread-1 A]
[Thread-3 B]
[Thread-3 C]
Now, despite making two writes per each print() request, only one thread is allowed to interact with the stream, while the rest must wait:
[
# Lock acquired by Thread-3
'[Thread-3 A]',
'\n',
# Lock released by Thread-3
# Lock acquired by Thread-1
'[Thread-1 B]',
'\n',
# Lock released by Thread-1
# ...
]
The added comments indicate how the lock is limiting access to the shared resource.
Note that you might get caught up in a somewhat similar situation even in single-threaded code! Specifically, when you’re printing to the buffered standard output and the unbuffered standard error streams at the same time. Unless you redirect one or both of them to separate files, they’ll both share a single terminal window.
Relying on Logging
Conversely, the logging module is thread-safe by design, which is reflected by its ability to display thread names in the formatted message:
>>> import logging
>>> logging.basicConfig(format="%(threadName)s %(message)s")
>>> logging.error("hello")
MainThread hello
It’s one reason why you might not want to use the print() function all the time.
Exploring Printing Counterparts
By now, you know a lot of what there’s to know about the print() function. But the subject wouldn’t be complete without talking about its counterparts a little bit. While print() is about the output, there are functions and libraries for the input.
Collecting User Input
Python comes with a built-in function for accepting input from the user, predictably called input(). It accepts data from the standard input stream, which is usually the keyboard:
>>> name = input("Enter your name: ")
Enter your name: John Doe
>>> print(name)
John Doe
This function always returns a string, so you might need to parse it accordingly:
>>> try:
... age = int(input("How old are you? "))
... except ValueError:
... print(f"That's not a correct number!")
...
How old are you? eighteen
That's not a correct number!
The prompt parameter is completely optional, so nothing will show if you skip it, but the function will still work:
>>> user_input = input()
Typing some text...
>>> print(user_input)
Typing some text...
Nevertheless, throwing in a descriptive call to action makes the user experience so much better.
Handling Input Securely
Asking the user for a password with input() is a bad idea because it’ll show up in plaintext as they’re typing it. In this case, you should be using the getpass() function instead, which masks typed characters. This function is defined in a module under the same name, which is also available in the standard library:
>>> from getpass import getpass
>>> password = getpass()
Password:
>>> print(password)
s3cret
The getpass module has another function for getting the user’s name from an environment variable. You might find it useful for prefilling a questionnaire:
>>> from getpass import getuser
>>> default_user = getuser()
>>> input(f"Enter your name ({default_user!r}): ") or default_user
Enter your name ('jdoe'):
'jdoe'
When the user doesn’t supply any input, you perform short-circuit evaluation of the Boolean expression, falling back on the default value.
Adding Readline Capabilities
Now, assume you wrote a command-line interface that understands three instructions, including one for adding numbers:
calculator.py
print('Type "help", "exit", "add a [b [c ...]]"')
while True:
command, *arguments = input("~ ").split(" ")
if len(command) > 0:
if command.lower() == "exit":
break
elif command.lower() == "help":
print("This is help.")
elif command.lower() == "add":
print(sum(map(int, arguments)))
else:
print("Unknown command")
At first glance, it seems like a typical prompt when you run it:
$ python calculator.py
Type "help", "exit", "add a [b [c ...]]"
~ add 1 2 3 4
10
~ aad 2 3
Unknown command
~ exit
$
But as soon as you make a mistake and want to fix it, you’ll see that none of the function keys work as expected. For instance, hitting the Left arrow key, causes ^[[D to appear on the screen instead of moving the cursor back:
$ python calculator.py
Type "help", "exit", "add a [b [c ...]]"
~ aad^[[D
To fix this, you can leverage the readline module from Python’s standard library. It’s sufficient to only import that module at the top of your script:
calculator.py
import readline
# ...
That’s it! As a result, not only will you get the arrow keys working, but you’ll also be able to search through the persistent history of your custom commands, use autocompletion, and edit the line with shortcuts:
$ python calculator.py
Type "help", "exit", "add a [b [c ...]]"
(reverse-i-search)`a': add 1 2 3 4
Isn’t that great?
Note: It’s worth mentioning that you can achieve the same effect by running your Python script through the rlwrap (readline wrapper) command:
$ rlwrap python calculator.py
Type "help", "exit", "add a [b [c ...]]"
(reverse-i-search)`a': add 1 2 3 4
You don’t have to do anything for it to work!
That said, handling the standard input with functions native to Python can sometimes be limited. Fortunately, there are plenty of third-party packages, which offer much more sophisticated tools.
Evaluating Third-Party Libraries
There are many external Python packages out there that allow for building complex graphical interfaces specifically to collect data from the user. Some of their features include:
- Advanced formatting and styling
- Automated parsing, validation, and sanitization of user data
- A declarative style of defining layouts
- Interactive autocompletion
- Mouse support
- Predefined widgets such as checklists or menus
- Searchable history of typed commands
- Syntax highlighting
Demonstrating such tools is outside of the scope of this tutorial, but you may want to try them out on your own. Apart from the mentioned Rich and Textual, you might look into these:
Several of these tools have been featured on podcasts—notably, prompt_toolkit has been mentioned on the Real Python Podcast in Episode 199, when discussing building an LLM chatbot.
Conclusion
You’re now armed with a body of knowledge about Python’s print() function and many related topics. You’ve seen how it works under the hood and explored all of its key elements through practical examples.
In this tutorial, you learned how to:
- Avoid common mistakes with
print()in Python - Deal with newlines, character encodings, and buffering
- Write text to files and memory buffers
- Mock the
print()function in unit tests - Build advanced user interfaces in the terminal
Now that you know all this, you can make interactive programs that communicate with users or produce data in popular file formats. You’ll be able to quickly diagnose problems in your code and protect yourself from them. And last but not least, you know how to implement the classic snake game.
If you’re still thirsty for more information, have questions, or just want to share your thoughts, then feel free to reach out in the comments section below.
Get Your Code: Click here to download the free sample code that shows you how to use the print() function in Python.
Frequently Asked Questions
Now that you have some experience with the Python print() function, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
You print a blank line in Python by calling print() without any arguments. This outputs a newline character, which appears as a blank line on the screen.
The sep parameter in print() specifies the separator inserted between multiple arguments. By default, it’s a space, but you can change it to any string, including an empty string or special characters like newlines.
To prevent a newline from being added at the end of a print() call, set the end parameter to an empty string (""). This allows subsequent print() calls to continue on the same line.
You can redirect the output of the print() function to a file by using the file parameter. Open the file in write or append mode and pass it to the print() function through the file keyword argument.
Mocking the print() function in unit tests is important to verify that your code calls print() with the expected arguments at the correct times. This helps you test the behavior of your code without relying on actual output.
Take the Quiz: Test your knowledge with our interactive “The Python print() Function” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
The Python print() FunctionIn this quiz, you'll test your understanding of Python's built-in print() function, covering how to format output, specify custom separators, and more.






