Although the final release of Python 3.13 is scheduled for October 2024, you can download and install a preview version today to explore the new features. Notably, the introduction of free threading and a just-in-time (JIT) compiler are among the most exciting enhancements, both designed to give your code a significant performance boost.
In this tutorial, you’ll:
- Compile a custom Python build from source using Docker
- Disable the Global Interpreter Lock (GIL) in Python
- Enable the Just-In-Time (JIT) compiler for Python code
- Determine the availability of new features at runtime
- Assess the performance improvements in Python 3.13
- Make a C extension module targeting Python’s new ABI
Check out what’s new in the Python changelog for a complete list of the upcoming features and improvements. This document contains a quick summary of the release highlights as well as a detailed breakdown of the planned changes.
To download the sample code and other resources accompanying this tutorial, click the link below:
Get Your Code: Click here to download the free sample code that shows you how to work with the experimental free threading and JIT compiler in Python 3.13.
Take the Quiz: Test your knowledge with our interactive “Python 3.13: Free Threading and a JIT Compiler” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Python 3.13: Free Threading and a JIT CompilerIn this quiz, you'll test your understanding of the new features in Python 3.13. You'll revisit how to compile a custom Python build, disable the Global Interpreter Lock (GIL), enable the Just-In-Time (JIT) compiler, and more.
Free Threading and JIT in Python 3.13: What’s the Fuss?
Before going any further, it’s important to note that the majority of improvements in Python 3.13 will remain invisible to the average Joe. This includes free threading (PEP 703) and the JIT compiler (PEP 744), which have already sparked a lot of excitement in the Python community.
Keep in mind that they’re both experimental features aimed at power users, who must take extra steps to enable them at Python’s build time. None of the official channels will distribute Python 3.13 with these additional features enabled by default. This is to maintain backward compatibility and to prevent potential glitches, which should be expected.
Note: Don’t try to use Python 3.13 with the experimental features in a production environment! It may cause unexpected problems, and the Python Steering Council reserves the right to remove these features entirely from future Python releases if they prove to be unstable. Treat them as an experiment to gather real-world data.
In this section, you’ll get a birds-eye view of these experimental features so you can set the right expectations. You’ll find detailed explanations on how to enable them and evaluate their impact on Python’s performance in the remainder of this tutorial.
Free Threading Makes the GIL Optional
Free threading is an attempt to remove the Global Interpreter Lock (GIL) from CPython, which has traditionally been the biggest obstacle to achieving thread-based parallelism when performing CPU-bound tasks. In short, the GIL allows only one thread of execution to run at any given time, regardless of how many cores your CPU is equipped with. This prevents Python from leveraging the available computing power effectively.
There have been many attempts in the past to bypass the GIL in Python, each with varying levels of success. You can read about these attempts in the tutorial on bypassing the GIL. While previous attempts were made by third parties, this is the first time that the core Python development team has taken similar steps with the permission of the steering council, even if some reservations remain.
Note: Python 3.12 approached the GIL obstacle from a different angle by allowing the individual subinterpreters to have their independent GILs. This can improve Python’s concurrency by letting you run different tasks in parallel, but without the ability to share data cheaply between them due to isolated memory spaces. In Python 3.13, you’ll be able to combine subinterpreters with free threading.
The removal of the GIL would have significant implications for the Python interpreter itself and especially for the large body of third-party code that relies on it. Because free threading essentially breaks backward compatibility, the long-term plan for its implementation is as follows:
- Experimental: Free threading is introduced as an experimental feature and isn’t a part of the official Python distribution. You must make a custom Python build to disable the GIL.
- Enabled: The GIL becomes optional in the official Python distribution but remains enabled by default to allow for a transition period.
- Disabled: The GIL is disabled by default, but you can still enable it if needed for compatibility reasons.
There are no plans to completely remove the GIL from the official Python distribution at the moment, as that would cause significant disruption to legacy codebases and libraries. Note that the steps outlined above are just a proposal subject to change. Also, free threading may not pan out at all if it makes single-threaded Python run slower than without it.
Until the GIL becomes optional in the official Python distribution, which may take a few more years, the Python development team will maintain two incompatible interpreter versions. The vanilla Python build won’t support free threading, while the special free-threaded flavor will have a slightly different Application Binary Interface (ABI) tagged with the letter “t” for threading.
This means that C extension modules built for stock Python won’t be compatible with the free-threaded version and the other way around. Maintainers of those external modules will be expected to distribute two packages with each release. If you’re one of them, and you use the Python/C API, then you’ll learn how to target CPython’s new ABI in the final section of this tutorial.
JIT Compiles Python to Machine Code
As an interpreted language, Python takes your high-level code and executes it on the fly without the need for prior compilation. This has both pros and cons. Some of the biggest advantages of interpreted languages include better portability across different hardware architectures and a quick development time due to the lack of a compilation step. At the same time, interpretation is much slower than directly executing code native to your machine.
Note: To be more precise, Python interprets bytecode instructions, an intermediate binary representation between pure Python and machine code. The Python interpreter compiles your code to bytecode when you import a module and stores the resulting bytecode in the __pycache__ folder. This doesn’t inherently make your Python scripts run faster, but loading a pre-processed bytecode can indeed speed up their startup time.
Languages like C and C++ leverage Ahead-of-Time (AOT) compilation to translate your high-level code into machine code before you ship your software. The benefit of this is faster execution since the code is already in the computer’s mother tongue. While you no longer need a separate program to interpret the code, you must compile it separately for all target platforms that you want supported. You should also handle platform-specific differences yourself.
There’s a middle ground between code compilation and interpretation. For example, Java takes the best of both worlds by compiling its code into portable bytecode, which is well-suited for both efficient and cross-platform execution. Additionally, Java uses the Just-In-Time (JIT) compilation approach, which basically means converting high-level instructions into native code right before it runs on the target machine.
This approach has some drawbacks, including a delayed startup time and non-deterministic performance, making it unfit for real-time computing, such as financial trading systems. On the other hand, JIT has advantages over the classic AOT compilation. Because a JIT compiler can collect invaluable information at runtime that isn’t available statically, it can further optimize the resulting machine code, tailoring it to the specific data patterns.
Up to now, you could take advantage of various JIT compilers for Python through external tools and libraries only. Some of them, like PyPy and Pyjion, offered more or less general-purpose JIT compilers, while others, such as Numba, focused on specific use cases like numerical computation.
The new experimental JIT compiler in Python 3.13 uses a fairly recent algorithm named copy-and-patch, which you can learn about in the official paper published in the proceedings of the ACM on Programming Languages in 2021. The basic idea behind this compilation technique boils down to finding a suitable template with pre-compiled machine code for the target CPU and filling it with the missing information, such as memory addresses of variables.
While copy-and-patch follows a relatively crude approach, ensuring fast just-in-time compilation, it yields surprisingly good results. Note that there’s currently no expectation for Python’s JIT to provide any meaningful performance improvements. At best, it should be on par with plain Python without the JIT, which is an achievement in itself considering the extra steps involved.
The long-term plan is to enhance Python’s JIT to the point where it actually makes a noticeable difference in code execution performance without taking much additional memory.
In the early stages of development of Python 3.13, it wasn’t possible to build the interpreter with both free threading and the JIT compiler enabled. You had to choose one or the other. Now, with the first release candidate available for download, both features have been fully integrated and can work together.
Next, you’ll learn where to get Python 3.13 with these experimental features supported.
Get Your Hands on the New Features
Because free threading and the JIT compiler are both experimental features, which can lead to defective behavior or suboptimal performance, you won’t find them in the standard Python 3.13 distribution. Enabling them takes some effort, so in this section, you’ll explore a few alternative ways to get a taste of these features.
The Official Distribution Channels
There are many ways to install Python on your computer. For example, you can run Python in Docker using one of the official images, which conveniently include pre-release versions. As mentioned earlier, none of the official distribution channels ship with free threading and JIT by default.
Having said that, if you’re on macOS or Windows, then you can use the official installers to customize Python’s installation process:
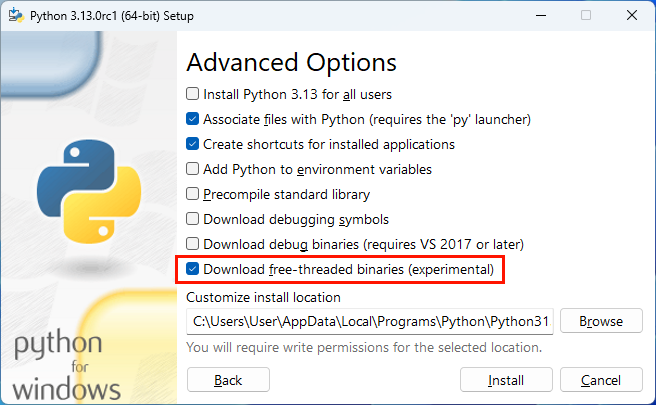
When you run the installer, choose Customize installation and click Next to skip the optional features. On the Advanced Options page, select the Download free-threaded binaries (experimental) checkbox at the bottom.
This will install separate Python binaries for the stock and free-threaded versions. On Windows, when you list the available interpreters using the Python launcher, you’ll see two variants of Python 3.13:
PS> py --list
-V:3.13t * Python 3.13 (64-bit, freethreaded)
-V:3.13 Python 3.13 (64-bit)
One is the standard build of Python 3.13, while the other, denoted with the letter “t,” is the free-threaded version. The asterisk (*) indicates the default binary to launch when you request Python 3.13 with the py -3.13 command.
Notice that while you can enable free threading using the official installer, there’s no analogous option for the experimental JIT compiler. That’s where alternative Python installation methods come into play, and you’ll take a closer look at them next.
Python Version Manager: pyenv
A popular tool for managing multiple Python versions on your computer is pyenv. It allows you to install many interpreters and switch between them quickly. It even comes with alternative Python interpreters like MicroPython and full-fledged distributions like Anaconda. Although pyenv works predominantly on Unix-like operating systems, if you’re on Windows, you can try the pyenv-win fork or use WSL.
Once you’ve successfully installed pyenv, you can list the Python interpreters available for download and optionally narrow down the results by using the Unix grep command or findstr on Windows:
This will filter the list, showing only names that include the string 3.13. When using pyenv-win on Windows, you’ll see just CPython versions. In contrast, on Linux and macOS, you might encounter other Python implementations as well. For instance, the highlighted lines correspond to CPython, while the remaining ones represent PyPy versions that match your search criteria.
Note: If you’ve installed pyenv before but haven’t used it in a while, then you might need to issue the pyenv update command first to fetch information about the latest Python releases.
As you can see from the Linux and macOS output above, there were four CPython versions and a few PyPy interpreters whose names contained the string 3.13 at the time of writing. You can disregard the latter because PyPy follows a slightly different versioning scheme, which involves the underlying Python version followed by a specific PyPy release number.
But why are there four CPython 3.13 versions? First of all, the ones ending with a -dev suffix represent the development version of Python, which contains unstable code that’s under active development. Generally speaking, you shouldn’t use these versions unless you’re testing or experimenting with the bleeding edge.
The rc1 suffix denotes the first release candidate of Python 3.13, while the trailing letter “t” indicates its free-threaded variant as opposed to the default version. Therefore, you can use pyenv to install a stock version of Python 3.13, as well as one with free-threading support. Type the following command to install both in one go:
$ pyenv install 3.13.0rc1 3.13.0rc1t
Just like the official installers, pyenv doesn’t bundle Python 3.13 with the experimental JIT support. After all, this little command-line tool merely reflects the available Git tags in the python/cpython repository on GitHub. However, unlike the official Python installers, which download pre-compiled binaries for your operating system, pyenv automates the compilation of the CPython source code, letting you customize the process.
To install Python 3.13 with the experimental JIT enabled using pyenv, you can specify custom build flags by setting the PYTHON_CONFIGURE_OPTS environment variable accordingly:
$ PYTHON_CONFIGURE_OPTS='--enable-experimental-jit' \
pyenv install 3.13.0rc1
In this case, you enable the JIT on top of the stock Python, 3.13.0rc1, which doesn’t come with free threading. If you’d like to have both features enabled simultaneously, then you can either pick 3.13.0rc1t as the basis or append the --disable-gil configuration option to the environment variable.
Sometimes, it’s useful to specify custom names for the same version of Python built with different options. To do so, you can use the pyenv-suffix plugin and the associated environment variable:
$ PYENV_VERSION_SUFFIX="-stock" \
pyenv install 3.13.0rc1
$ PYENV_VERSION_SUFFIX="-nogil" \
PYTHON_CONFIGURE_OPTS='--disable-gil' \
pyenv install 3.13.0rc1
$ PYENV_VERSION_SUFFIX="-jit" \
PYTHON_CONFIGURE_OPTS='--enable-experimental-jit' \
pyenv install 3.13.0rc1
$ PYENV_VERSION_SUFFIX="-nogil-jit" \
PYTHON_CONFIGURE_OPTS='--disable-gil --enable-experimental-jit' \
pyenv install 3.13.0rc1
$ pyenv versions
* system (set by PYENV_VERSION environment variable)
3.13.0rc1-jit
3.13.0rc1-nogil
3.13.0rc1-nogil-jit
3.13.0rc1-stock
This way, you’ll have multiple copies of the same baseline Python built with different feature sets. Note that you’ll need to install the pyenv-suffix plugin before proceeding with these commands. Otherwise, pyenv will ignore PYENV_VERSION_SUFFIX entirely, and you’ll end up overwriting existing installations under the same name!
Alternatively, you can install the python-build plugin, which comes with pyenv, as a standalone tool to gain more control. By doing this, you’ll be able to give the installed Python interpreters arbitrary names instead of just adding suffixes to their predefined versions:
$ PYTHON_CONFIGURE_OPTS='--disable-gil --enable-experimental-jit' \
python-build -v 3.13.0rc1 $(pyenv root)/versions/py3.13
This command will compile Python 3.13 with both free threading and the experimental JIT, placing it under the py3.13 alias in pyenv.
While pyenv hides many tedious details about making custom Python builds, there may be times when you’ll want the ultimate control. In the next section, you’ll get an idea of what it takes to compile Python 3.13 with the experimental features from the source code by hand.
Custom Build From Source Code
You can get a copy of the Python 3.13 source code from GitHub by cloning the associated tag. For example, you can use this command:
$ git clone --branch v3.13.0rc1 --depth=1 https://github.com/python/cpython.git
Specifying the --branch parameter allows you to clone only the specific line of development rather than the complete repository with its entire history, which saves quite a bit of time. The name v3.13.0rc1 points to the final commit in the release candidate. The other parameter, --depth=1, limits the number of commits to fetch to the most recent one.
Alternatively, if you don’t have a Git client installed, then you can download a zipped archive with similar content using the GitHub web interface:
Locate the green button labeled Code, click on it, and choose Download ZIP from the modal window that pops up.
You can also download a pre-release version of Python from the official python.org website. The gzip tarball with the source code is comparable in size to the ZIP archive provided by GitHub.
Assuming you have all the necessary build tools and libraries installed, which you’ll learn about in the next section, you can change your current working directory into the cloned or downloaded CPython folder and go from there. For platform-specific instructions, refer to the Python Developer’s Guide.
The first step is to configure the build by running the configure script:
$ cd cpython/
$ ./configure --disable-gil --enable-experimental-jit --enable-optimizations
This script collects various information about your operating system, library versions, build options, preferred installation location, and so on. It then uses that information to adapt Python to your specific environment. Optionally, you can use it to perform cross-compilation, targeting another system or platform.
Here’s a quick recap of how to enable Python 3.13’s experimental features:
- Free Threading: To compile Python with free-threading support, you need to configure the build with the
--disable-giloption. - JIT Compiler: To compile Python with the experimental JIT compiler, you need to configure the build using the
--enable-experimental-jitoption.
While --disable-gil is a Boolean flag that can be either turned on or off, the --enable-experimental-jit switch takes optional values:
| Optional Value | Just-In-Time Compilation |
|---|---|
no |
Unsupported |
yes (default) |
Enabled by default but can be disabled at runtime |
yes-off |
Disabled by default but can be enabled at runtime |
interpreter |
Unsupported, used for debugging |
interpreter-off |
Unsupported, used for debugging (undocumented secret value) |
Only the yes and yes-off values enable support for the JIT compiler. When you don’t specify any value for this option, then it has the same effect as typing yes, which is the default value.
Note: You can control the GIL and JIT with the PYTHON_GIL and PYTHON_JIT environment variables, respectively. You’ll learn more about them, as well as the special -X gil switch, later in this tutorial.
Unless you’re in the middle of implementing a new feature in CPython and need to recompile its source code often, it’s usually a good idea to --enable-optimizations when building a production-grade Python interpreter. This flag will improve the performance and memory management of the resulting code, which would otherwise be less than optimal. On the other hand, it’ll make the build take longer.
Because building Python from scratch requires many dependencies and can look different on various operating systems, there’s no one-size-fits-all solution. To streamline the process, you’ll find detailed step-by-step instructions based on Docker in the following section.
Compile and Run Python 3.13 Using Docker
To ensure a cross-platform experience, you’ll be using a lightweight Docker container based on Ubuntu to compile and then run Python 3.13 with the experimental features. Therefore, to proceed with the instructions below, you’ll need to install Docker.
This setup provides a consistent development environment. But if you’re already running Ubuntu and don’t mind installing the necessary dependencies, you can also follow along directly in your host operating system without using Docker. If you’re using another Linux distribution or macOS, then you may need to adapt some of the commands.
Install the Necessary Build Tools and Libraries
First, run a fresh Docker container using an official Ubuntu image maintained by Canonical:
$ docker run --name ubuntu --hostname ubuntu -it ubuntu
This will pull the latest ubuntu image from Docker Hub and run a new container based on it. If you’re reading this in the future, then you may want to explicitly request a specific snapshot of that image to ensure reproducibility:
$ docker pull ubuntu@sha256:8a37d68f4f73ebf3d4efafbcf66379bf3728902a8038616808f04e34a9ab63ee
The SHA-256 digest above represents the exact version of the image used at the time of making this tutorial. Future versions of the image may come with slightly different system packages, potentially causing problems.
The -it option in the docker run command instructs Docker to run your new container in an interactive mode. This lets you type commands as if you logged in to a remote server. The --name and --hostname parameters are optional but will allow you to find your container more easily using Docker’s command-line interface.
Note: Don’t worry if you accidentally close your container, for example, by pressing Ctrl+D or typing the exit command. You can resume the container at any time using the following commands:
$ docker start ubuntu
$ docker attach ubuntu
The first command starts a paused container, while the second command attaches your terminal to that container so you can interact with it again. Any data you might have created will still be there thanks to Docker’s overlay file system, even if you haven’t explicitly mounted a persistent volume.
The very first thing you should typically do after starting a new Docker container is upgrade your system packages. Here’s how you can do this in the Ubuntu container:
root@ubuntu:/# apt update
root@ubuntu:/# apt upgrade -y
This ensures that your container has the latest security patches and software updates. Additionally, when you’re starting from scratch, the apt update command retrieves a list of packages available for your Debian-based distribution. Depending on your base Docker image, that list might be initially empty, preventing you from installing any new packages.
Next, you can install the required dependencies to compile Python 3.13 from source code:
root@ubuntu:/# DEBIAN_FRONTEND=noninteractive apt install -y \
wget unzip build-essential pkg-config zlib1g-dev \
python3 clang
Note that you instruct the apt package manager to use a non-interactive mode by setting the DEBIAN_FRONTEND environment variable accordingly. This will skip the interactive prompt that the tzdata package would display to ask about your preferred time zone during installation. When set to noninteractive, this variable makes the tool use Etc/UTC as the default timezone without bothering you.
You may be wondering how the python3 package found its way into the list of dependencies needed to compile Python. Oddly enough, it may sound like you must already have Python to compile Python itself. Indeed, you need an earlier version of the Python interpreter, but only if you want to build Python 3.13 with the JIT support. That’s because the JIT build tool, which generates binary stencils for the copy-and-patch compiler, is a pure-Python script.
Notice the you also listed the clang package, which is another requirement for the JIT compiler in Python 3.13. Apart from the build-essential package, which brings the venerable GNU C compiler, you must also include the competing Clang compiler from the LLVM toolchain. Here’s why:
Clang is specifically needed because it’s the only C compiler with support for guaranteed tail calls (
musttail), which are required by CPython’s continuation-passing-style approach to JIT compilation. (Source)
Fortunately, it’s a build-time-only dependency for the JIT to work. So, you won’t need LLVM to run the compiled Python interpreter afterward.
Note: This was the bare minimum set of dependencies to compile Python. As a result, some of the standard-library modules, such as tkinter and sqlite3, won’t work without additional libraries. If you’d like to support everything, then consider installing these extra packages as well:
root@ubuntu:/# apt install -y gdb lcov libbz2-dev libffi-dev \
libgdbm-compat-dev libgdbm-dev liblzma-dev libncurses-dev \
libreadline-dev libsqlite3-dev libssl-dev lzma lzma-dev tk-dev uuid-dev
Although this will make your custom Python build fully functional, you don’t need these to evaluate free threading and the experimental JIT compiler.
Now that your Docker container has all the essential build tools and libraries, you’re ready to proceed to downloading the Python source code.
Download Python Source Code Into the Container
While still in your Docker container, download an archive of CPython’s source code tagged as 3.13, either from GitHub or python.org, and extract it into a temporary location. You may replace a release candidate in the ZIP_FILE variable below with the final release if it’s available when you read this tutorial:
root@ubuntu:/# BASE_URL=https://github.com/python/cpython/archive/refs/tags
root@ubuntu:/# ZIP_FILE=v3.13.0rc1.zip
root@ubuntu:/# wget -P /tmp $BASE_URL/$ZIP_FILE
root@ubuntu:/# unzip -d /tmp /tmp/$ZIP_FILE
Here, you use Wget to download the ZIP file from the specified URL into the /tmp folder. In the next step, you’ll configure the build by enabling the experimental features introduced in Python 3.13.
Build Python With Free Threading and JIT Support
Navigate into the parent folder containing the Python source code, which you extracted from the downloaded archive in the previous step:
root@ubuntu:/# cd /tmp/cpython-3.13.0rc1/
Make sure to adjust the path as necessary if you opted for a more recent Python 3.13 release.
Now, you can run the configure script with custom build flags to enable free threading and the JIT compiler:
root@ubuntu:/tmp/cpython-3.13.0rc1# ./configure --disable-gil \
--enable-experimental-jit \
--enable-optimizations
This will configure your build environment and generate a new Makefile in the current working directory, which you can invoke with the make command:
root@ubuntu:/tmp/cpython-3.13.0rc1# make -j $(nproc)
Calling make without providing a specific target will trigger the default one, which is conventionally named all.
By using the -j option, you specify the number of jobs to run simultaneously. The nproc command returns the number of processing units on your computer for parallel execution. Despite running this within a Docker container, you still have access to all the CPU cores available on the host system. That’s the default behavior unless you specify otherwise when creating your Docker container.
Running multiple jobs in parallel will significantly speed up the compilation process, but you may need to wait a few minutes anyway. The good news is that you won’t be compiling Python often.
To verify if the compilation succeeded, try executing the resulting python binary file from the local folder:
root@ubuntu:/tmp/cpython-3.13.0rc1# ./python
Python 3.13.0rc1 experimental free-threading build
⮑ (main, Aug 26 2024, 15:10:57) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
Great! The version information in the header confirms that you’ve made a custom build of Python 3.13. Additionally, your build includes free threading, as indicated by the printed message.
To check whether your build also comes with the experimental JIT compiler, you can define the following function in your shell, which takes the path to a python executable:
root@ubuntu:/tmp/cpython-3.13.0rc1# \
> function has_jit() {
local py=$1
$py -m sysconfig | grep -q _Py_JIT && echo "yes" || echo "no"
}
root@ubuntu:/tmp/cpython-3.13.0rc1# has_jit ./python
yes
root@ubuntu:/tmp/cpython-3.13.0rc1# has_jit /usr/bin/python3
no
The has_jit() function looks for the _Py_JIT macro in the build configuration using the sysconfig module from the standard library. When you call this function against your custom Python build, it reports the presence of the JIT compiler by printing yes. Conversely, running it with the system Python executable, which doesn’t include the JIT, results in printing no.
Note: Keep in mind that these checks can confirm if your Python build supports both experimental features. To find out whether they’re actually enabled at runtime, you need to use other techniques, which you’ll explore later.
You can now install Python 3.13 inside your Docker container so that you don’t have to specify the complete path to the compiled python executable every time. Running the make install command would overwrite the global interpreter provided by Ubuntu. To keep it while installing your custom build alongside, specify the altinstall target instead:
root@ubuntu:/tmp/cpython-3.13.0rc1# make altinstall
It’ll place the python3.13 executable in /usr/local/bin, which is already present in the PATH variable, making it accessible from anywhere in the file system:
root@ubuntu:/# echo $PATH | tr ':' '\n'
/usr/local/sbin
/usr/local/bin
/usr/sbin
/usr/bin
/sbin
/bin
Additionally, if you compiled Python with free threading support, then this folder will also contain the python3.13t binary, which is an exact copy of the former. This will come in handy soon.
At the same time, because you haven’t installed Python 3.13 globally, you can choose to run the system interpreter by calling the corresponding executable, such as python3.12, or its alias, python3:
root@ubuntu:/# which python3.13
/usr/local/bin/python3.13
root@ubuntu:/# ll $(which python3)
lrwxrwxrwx 1 root root 10 Aug 7 17:44 /usr/bin/python3 -> python3.12*
The which command locates the given binary file by searching for it in the directories listed in the PATH variable. The ll command is a bash alias to the ls -alF command, which can reveal if the specified path is a symbolic link. In this case, python3 points to python3.12 in /usr/bin.
That way, both Python versions coexist on the same system without conflict. You can use them to run various benchmarks, comparing the performance differences between Python 3.12 and Python 3.13 compiled with the experimental features. However, it’d also be fair to determine how the standard Python 3.13 stacks up against them. So, you’re going to build the vanilla flavor of Python 3.13 without free threading or JIT support.
Build Stock Python Without Experimental Features
Ensure that your current working directory is where you compiled Python 3.13 before, and remove any generated build files with make clean. Then, configure the build without the experimental features and compile Python again. Finally, install stock Python 3.13, making it the default global interpreter:
root@ubuntu:/# cd /tmp/cpython-3.13.0rc1/
root@ubuntu:/tmp/cpython-3.13.0rc1# make clean
root@ubuntu:/tmp/cpython-3.13.0rc1# ./configure --enable-optimizations
root@ubuntu:/tmp/cpython-3.13.0rc1# make -j $(nproc)
root@ubuntu:/tmp/cpython-3.13.0rc1# make install
Note that you won’t completely lose access to the system interpreter, as it’ll remain available to you by its full name, such as python3.12. Only the python3 alias will now point to the compiled Python 3.13. As a result, you’ll be able to run three variants of Python:
| Command | Full Path | Python Version |
|---|---|---|
python3.12 |
/usr/bin/python3.12 |
Python 3.12 |
python3.13 |
/usr/local/bin/python3.13 |
Python 3.13 (stock) |
python3.13t |
/usr/local/bin/python3.13t |
Python 3.13 (free threading and JIT) |
This is where the executable’s copy with the “t” suffix becomes useful. When you compile stock Python, it doesn’t affect the python3.13t binary you built previously. Note that python3 will alias python3.13 and become synonymous with stock Python 3.13.
Okay. You have a few versions of Python in your Docker container, but how do you run them on your host machine? This is what you’ll find out in the next couple of sections.
Take a Snapshot of Your Docker Container
It’s time to do some cleanup. You can now remove the Python source code from the temporary folder, as you won’t need it anymore:
root@ubuntu:/tmp/cpython-3.13.0rc1# cd /
root@ubuntu:/# rm -rf /tmp/cpython-3.13.0rc1/ /tmp/v3.13.0rc1.zip
First, you change directory (cd) into the root folder (/) to ensure that you’re not in the directory you’re about to delete. You then remove the extracted folder as well as the downloaded ZIP archive.
Next, exit your Docker container and take a snapshot of its current state, including all the file system changes, using the docker commit command:
$ docker commit ubuntu pythons
sha256:1fb11ad8cc1614a7135f5cda77b1501d3e7a573e1985688140a95217c7001ee6
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
pythons latest 1fb11ad8cc16 2 minutes ago 2.21GB
ubuntu latest edbfe74c41f8 3 weeks ago 78.1MB
This produces a brand new Docker image that you call pythons, from which you can run new containers. Notice the difference in size between the parent and child images. The image with your custom Python builds is two orders of magnitude larger than the original ubuntu image it was based on! That’s mostly due to the tools and libraries required to build Python.
Note: This is okay for the purposes of this tutorial. However, if you’d like to significantly reduce the size of your Docker image, then consider defining a Dockerfile with a multi-stage build. You’ll find one in the supporting materials available for download.
Having a Docker image like this in place makes it straightforward to run various versions of Python on your host machine, and you’re about to see how.
Run Python 3.13 From Your Host Machine
To access the corresponding Python REPL, you can now start new Docker containers from your image on demand:
$ docker run --rm -it pythons python3.12
Python 3.12.3 (main, Jul 31 2024, 17:43:48) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
$ docker run --rm -it pythons python3.13
Python 3.13.0rc1 (main, Aug 26 2024, 18:06:12) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
$ docker run --rm -it pythons python3.13t
Python 3.13.0rc1 experimental free-threading build
⮑ (main, Aug 26 2024, 15:10:57) [GCC 13.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>>
The --rm flag tells Docker to automatically remove your container once it stops running, while the -it option enables the interactive mode to let you type commands. Otherwise, the container would immediately cease to exist.
If you just want to run a short code snippet that fits on a single line, then you don’t need to use the interactive mode. Instead, you can call Python with a one-liner program using the -c option and a command to execute:
$ docker run --rm pythons python3.13 -c 'print("Hello, World!")'
Hello, World!
This is fine, but what about running a locally developed Python script or a larger project consisting of multiple modules? To do so, you can map your working directory on the host machine to an arbitrary directory inside the container:
$ echo 'print("Hello, World!")' > script.py
$ docker run --rm -v "$(pwd)":/app pythons python3.13 /app/script.py
Hello, World!
$ docker run --rm -v "$(pwd)":/app -w /app pythons python3.13 script.py
Hello, World!
The -v option specifies a bind mount by associating a folder on your host machine with the /app folder in the container. In this case, you run the Unix pwd command to reveal the current working directory where your script is. If you don’t want to provide the full path to your Python script within the container, then you might set an implicit working directory for Docker using the -w option.
In turn, this lets you automate the steps to configure and run a Docker container with a mounted volume by using another shell function as an abstraction layer:
$ function py() {
docker run --rm -v "$(pwd)":/app -w /app pythons "$@"
}
This function wraps your docker run command with its associated parameters so you can spawn Docker containers more concisely:
$ py python3.13t script.py
Hello, World!
$ git clone git@github.com:VaasuDevanS/cowsay-python.git
$ cd cowsay-python/
$ py python3.13t -m cowsay -t "Hello, World!"
_____________
| Hello, World! |
=============
\
\
^__^
(oo)\_______
(__)\ )\/\
||----w |
|| ||
Evidently, your little py() function can invoke standalone scripts as well as more complicated projects. As long as you define it in your shell startup script, such as ~/.bashrc, it won’t take much effort to hook this function up to your favorite IDE or code editor and define a relevant run configuration.
Note: Starting a new container and removing it after your Python code finishes is inefficient. Instead of running a new container each time, you can let one sit in the background in detached (-d) mode:
$ docker run -d -v "$(pwd)":/app -w /app --name py pythons tail -f /dev/null
Later, you’ll be able to execute Python scripts without the initial overhead of creating new Docker containers. You can just execute the specified command on an already running container, which you named py:
$ docker exec py python3.13t script.py
Hello, World!
This runs much faster. As a downside, though, you’re bound to the mount point specified earlier when you first started your background container.
Now that you know how to run different interpreters, it’s time to start experimenting with the new features introduced in Python 3.13.
Check the Availability of Experimental Features at Runtime
In this section, you’ll write a short script to display information about your operating system, hardware architecture, and the current Python interpreter. It’ll be useful in comparing different configurations and ensuring that certain features are enabled. This is what a sample output might look like:
$ python pyinfo.py
====================================================================
💻 Linux 64bit with 4x CPU cores (x86_64 Little Endian)
🐍 CPython 3.12.5 /home/realpython/.pyenv/versions/3.12.5/bin/python
Free Threading: unsupported
JIT Compiler: unsupported
====================================================================
The status of free threading and the JIT compiler at the bottom are particularly interesting. In this case, the Python interpreter that you ran your script with supports neither of them.
Go ahead and open the code editor of your choice. Then, create a Python module named pyinfo and write the following bit of code:
pyinfo.py
import os
import platform
import sys
from pyfeatures import FreeThreading, JitCompiler
def print_details():
lines = [
system_details(),
python_details(),
str(FreeThreading()),
str(JitCompiler()),
]
print(header := "=" * max(map(len, lines)))
print("\n".join(lines))
print(header)
def system_details():
name = platform.system()
arch, _ = platform.architecture()
cpu = platform.processor()
cores = os.cpu_count()
endian = f"{sys.byteorder} Endian".title()
return (
f"\N{PERSONAL COMPUTER} {name} {arch} with "
f"{cores}x CPU cores ({cpu} {endian})"
)
def python_details():
implementation = platform.python_implementation()
version = platform.python_version()
path = sys.executable
return f"\N{SNAKE} {implementation} {version} {path}"
if __name__ == "__main__":
print_details()
You use a few standard-library modules to query your system and Python details, which you then display neatly. Additionally, you import two classes, FreeThreading and JitCompiler, from another custom module named pyfeatures.
Create that module now and start filling in the missing pieces. You’ll begin by defining a common interface to both features by using an abstract base class called Feature:
pyfeatures.py
import abc
class Feature(abc.ABC):
def __init__(self, name: str) -> None:
self.name = name
def __str__(self) -> str:
if self.supported:
if self.enabled:
return f"{self.name}: enabled \N{SPARKLES}"
else:
return f"{self.name}: disabled"
else:
return f"{self.name}: unsupported"
@property
@abc.abstractmethod
def supported(self) -> bool:
pass
@property
@abc.abstractmethod
def enabled(self) -> bool:
pass
Every feature has a .name and two properties, indicating whether it’s .enabled or .supported at all. A feature object can also provide its string representation to reveal the corresponding status in text format.
Next up, you’ll implement concrete feature classes that inherit from your abstract base class.
Take Control of the Global Interpreter Lock
Earlier, you checked if Python supports free threading by looking at the header displayed in the Python REPL. Depending on how you built Python, the welcome message would take one of the following forms:
- Python 3.13.0rc1
- Python 3.13.0rc1 experimental free-threading build
A free-threaded Python build clearly emphasizes its experimental status. To determine the support of free threading programmatically, you need to check the Py_GIL_DISABLED configuration variable through the sysconfig module:
>>> import sysconfig
>>> sysconfig.get_config_var("Py_GIL_DISABLED")
1
The name of that variable can be slightly misleading because it doesn’t tell you if the GIL is, in fact, disabled. Instead, it corresponds to the --disable-gil configuration option that you set at build time.
More specifically, if the variable has a value of one, then the global interpreter lock is optional and can be disabled. If it has a value of zero, then Python was built without free-threading support, so the GIL remains mandatory. Finally, if the variable doesn’t exist, and you get None as a result, then it likely indicates an older version of Python with the GIL permanently baked-in.
As mentioned, it’s a build-time configuration variable, which has no effect on the actual status of the GIL at runtime. To check whether the GIL is running or not, call sys._is_gil_enabled():
>>> import sys
>>> if sys.version_info >= (3, 13):
... print("GIL is enabled:", sys._is_gil_enabled())
... else:
... print("GIL is enabled")
...
GIL is enabled: True
Because this is a new internal function introduced in Python 3.13, you need to account for the current Python version. You do this by comparing sys.version_info to a tuple containing the major and minor version numbers. If it’s an older Python release, then you can assume the GIL is present at all times.
Remember that when free threading is supported, the GIL can be either enabled or disabled. To toggle its status—provided that your Python build allows for that—you can set one of the following:
- Environment Variable:
PYTHON_GIL=0orPYTHON_GIL=1 - Interpreter Option:
python -X gil=0orpython -X gil=1
In both cases, zero switches the GIL off, while a value of one switches it back on again. Note that this can be a little confusing since disabling the GIL is essentially the opposite of enabling free threading and the other way around. This is in contrast to how you control the JIT compiler, as you’re about to find out in the next section.
Note: Using the environment variable has a slight advantage over the -X gil switch, which earlier Python versions won’t recognize and will report an error. In contrast, unknown environment variables get ignored.
Putting it all together, you can define a concrete FreeThreading class in your pyfeatures module, which encapsulates the logic to check the free threading and GIL status:
pyfeatures.py
import abc
import sys
import sysconfig
# ...
class FreeThreading(Feature):
def __init__(self) -> None:
super().__init__("Free Threading")
@property
def supported(self) -> bool:
return sysconfig.get_config_var("Py_GIL_DISABLED") == 1
@property
def enabled(self) -> bool:
return not self.gil_enabled()
def gil_enabled(self) -> bool:
if sys.version_info >= (3, 13):
return sys._is_gil_enabled()
else:
return True
The .__init__() method calls the class constructor from its parent with a human-readable name of the feature as an argument. The two properties check whether free threading is supported and enabled. Notice how you delegate one of the properties to a helper method, which checks the GIL status, to reduce the risk of confusion mentioned before.
If you’re curious about the influence of the PYTHON_GIL environment variable or the equivalent -X gil switch on the free-threaded Python 3.13, then check out the following code snippet:
$ CODE='import pyfeatures; print(pyfeatures.FreeThreading())'
$ python3.13 -c "$CODE"
Free Threading: unsupported
$ python3.13t -c "$CODE"
Free Threading: enabled ✨
$ python3.13t -X gil=1 -c "$CODE"
Free Threading: disabled
This confirms that you can toggle the GIL status at will. To see if it has any meaningful impact on Python’s performance, you’ll prepare a small benchmark later on.
In the next section, you’ll implement the missing JitCompiler class and learn how to determine if the related feature is supported.
Toggle the Just-in-Time Compiler at Runtime
If you’ve been following along, then you may recall that the _Py_JIT macro in Python’s build configuration implies the JIT support. You define this macro implicitly by specifying the --enable-experimental-jit option when configuring your custom Python build. In turn, this causes the C compiler to consider a special file, jit.c, with the underlying source code for the experimental JIT compiler.
You can check if this macro was present when you built Python by inspecting the PY_CORE_CFLAGS configuration variable using the sysconfig module:
>>> import sysconfig
>>> "_Py_JIT" in sysconfig.get_config_var("PY_CORE_CFLAGS")
True
>>> for flag in sysconfig.get_config_var("PY_CORE_CFLAGS").split():
... print(flag)
...
-fno-strict-overflow
-Wsign-compare
-DNDEBUG
-g
-O3
-Wall
-D_Py_TIER2=1
-D_Py_JIT
-std=c11
-Wextra
(...)
Just like with free threading, the support for JIT is independent of its runtime status. The above test only tells you if Python comes with the JIT, but you don’t know if it’s currently enabled. For example, using the yes-off value for the relevant build option makes the JIT disabled by default, but you can still enable it at runtime.
Note: While the _Py_JIT macro is unequivocal evidence for the JIT support, the _Py_TIER2 macro determines its mode of operation:
| Optional Value | Preprocessor Flags |
|---|---|
no |
|
yes |
-D_Py_TIER2=1, -D_Py_JIT |
yes-off |
-D_Py_TIER2=3, -D_Py_JIT |
interpreter |
-D_Py_TIER2=4 |
interpreter-off |
-D_Py_TIER2=6 |
This table shows which flags are set when you choose one of the optional values for the --enable-experimental-jit build switch. The _Py_TIER2 alone isn’t enough to confirm if the JIT is supported.
Determining whether the JIT is actually running is tricky because it remains hidden deep within Python’s internal C API. Unlike the public Python API, which you can access by writing a custom C extension module, the internal API is meant for the interpreter only. As a result, you’d need to modify the CPython source code itself and recompile it to expose some of the JIT’s inner workings to Python. That’s hardly portable.
You could alternatively take a stab at profiling your Python process—for example, with the help of the Linux perf profiler—and try to make sense of the captured function call graph.
Fortunately, there’s a more straightforward way. You can leverage the undocumented _testinternalcapi module in Python’s standard library, which is meant for testing the internal API during development. Here’s how you can abuse it to check the JIT compiler’s status at runtime:
>>> import sys
>>> import _testinternalcapi
>>> if sys.version_info >= (3, 13):
... print("JIT is enabled:", _testinternalcapi.get_optimizer() is not None)
... else:
... print("JIT is disabled")
...
JIT is enabled: True
In Python 3.13 or above, this module defines a function named get_optimizer(), which returns an object that can produce optimized micro-ops when the JIT is enabled. At the moment, there can be only one optimizer associated with the JIT or none at all.
You can now connect the dots by defining a companion JitCompiler class in your pyfeatures module:
pyfeatures.py
import abc
import sys
import sysconfig
import _testinternalcapi
# ...
class JitCompiler(Feature):
def __init__(self):
super().__init__("JIT Compiler")
@property
def supported(self) -> bool:
return "_Py_JIT" in sysconfig.get_config_var("PY_CORE_CFLAGS")
@property
def enabled(self) -> bool:
if sys.version_info >= (3, 13):
return _testinternalcapi.get_optimizer() is not None
else:
return False
It follows the same structure as the FreeThreading class that you implemented previously. The two properties adhere to the interface imposed by the abstract base class, but you tailored their implementation to the JIT compiler’s specifics.
While you can toggle the JIT by setting the PYTHON_JIT environment variable, there’s no equivalent -X option as with the GIL:
$ CODE='import pyfeatures; print(pyfeatures.JitCompiler())'
$ python3.13 -c "$CODE"
JIT Compiler: unsupported
$ python3.13t -c "$CODE"
JIT Compiler: enabled ✨
$ PYTHON_JIT=0 python3.13t -c "$CODE"
JIT Compiler: disabled
Okay. The output seems to indicate that something is changing in Python 3.13 when you set the appropriate environment variable. But you’re going to need more evidence to be sure by demonstrating the JIT in action.
Break Down Python Bytecode Into Micro-Ops
When you run a piece of Python code, the interpreter first reads your high-level code and translates it into a binary form, which is more suitable for interpretation. The resulting stream of bytes, or bytecode, represents a sequence of instructions, each consisting of an opcode and a corresponding argument. For example, consider the following Python function, which adds two values:
>>> def add(a, b):
... return a + b
...
To preview this function’s bytecode in raw format, you can access its .__code__ attribute. Alternatively, you can disassemble the bytecode into human-readable instructions by using the dis module:
>>> add.__code__.co_code
b'\x97\x00|\x00|\x01z\x00\x00\x00S\x00'
>>> import dis
>>> for instruction in dis.Bytecode(add):
... print(instruction.opname, instruction.argrepr)
...
RESUME
LOAD_FAST a
LOAD_FAST b
BINARY_OP +
RETURN_VALUE
The interpreter has transformed your Python function body, which consists of a single return statement followed by an arithmetic expression, into five bytecode instructions. Here’s what their individual opcode names mean:
RESUME: Do nothing. This is used for internal tracing or as an optimization.LOAD_FAST: Load a local variable onto the stack.BINARY_OP: Pop two elements from the stack, perform the specified binary operation on them, and push the result back onto the stack.RETURN_VALUE: Pop a value from the stack and return it to the function’s caller.
This is called the Tier 1 bytecode, which the interpreter produces even before running your code. However, since Python 3.11, the underlying runtime environment ships with a specializing adaptive interpreter (PEP 659), which can change the bytecode dynamically. Once Python determines that certain optimizations can be applied during execution, it’ll go ahead and replace the relevant opcodes with their specialized versions.
This mechanism mostly relies on the type information available at runtime. For instance, when the interpreter finds that you only call your function with numeric arguments as opposed to strings, then it can decide to use an integer-specific addition instead of the generic one. As a result, Python avoids the type-checking overhead.
To drill down to specialized opcodes, you can optionally pass the adaptive=True flag to the disassembler. Note that you must call your function a few times before adaptive optimization kicks in, giving Python a chance to analyze how you actually use your code:
>>> add(1, 2)
3
>>> add(3, 4)
7
>>> for instruction in dis.Bytecode(add, adaptive=True):
... print(instruction.opname, instruction.argrepr)
...
RESUME
LOAD_FAST__LOAD_FAST a
LOAD_FAST b
BINARY_OP_ADD_INT +
RETURN_VALUE
After you called your function twice with integer literals as arguments, Python replaced the BINARY_OP instruction with a more specialized BINARY_OP_ADD_INT one.
This ability to change bytecode dynamically brings Python one step closer to the just-in-time compilation. However, even these optimized bytecode instructions are still fairly abstract and far away from machine code. That’s where Python 3.13 comes in.
When you build Python 3.13 with the experimental JIT support, you’ll enable a lower-level execution layer called the Tier 2 interpreter, which breaks down Python bytecode into even more granular instructions. These micro-ops can be mapped to native machine instructions very quickly using the copy-and-patch algorithm.
Note: If you’ve built Python with JIT support using either the interpreter or interpreter-off mode, then Python will keep the generated micro-ops instead of compiling them down into native code. This can be helpful in troubleshooting and debugging.
While you’ll never see the machine code that Python may potentially produce, it’s possible to access its precursor—the micro-ops confirming the JIT at work. To do so, create the following helper script and place it next to your existing pyinfo and pyfeatures modules:
uops.py
import dis
import _opcode
from pyinfo import print_details
def reveal_code(function):
if uops := "\n".join(_get_micro_ops(function)):
print(uops)
else:
print("Micro-ops unavailable")
def _get_micro_ops(function):
for executor in _get_executors(function):
for uop, *_ in executor:
yield uop
def _get_executors(function):
bytecode = function.__code__._co_code_adaptive
for offset in range(0, len(bytecode), 2):
if dis.opname[bytecode[offset]] == "ENTER_EXECUTOR":
try:
yield _opcode.get_executor(function.__code__, offset)
except ValueError:
pass
print_details()
This code defines a public reveal_code() function, which takes a function reference as an argument and prints out the corresponding micro-ops, if there are any. One of the private methods takes advantage of a new undocumented method in the standard library, _opcode.get_executor(), which returns an optional executor object. By iterating over this object, you can obtain the generated micro-ops.
To see the just-in-time compilation in action, run the script above using a custom Python build with the JIT enabled. Requesting the interactive mode (-i) will drop you into a new REPL session after loading the function definitions and printing the header with useful information:
$ python3.13-jit -i uops.py
=================================================================
💻 Linux 64bit with 4x CPU cores (x86_64 Little Endian)
🐍 CPython 3.13.0rc1 /tmp/cpython-3.13.0rc1/python
Free Threading: unsupported
JIT Compiler: enabled ✨
=================================================================
>>>
The highlighted line confirms this is the correct Python build, so you can proceed. Unfortunately, the add() function you defined at the beginning of this section won’t cut it this time because it’s too short for the JIT to consider. Compiling such a minimal function would probably yield little performance gains while incurring a relatively high cost.
Instead, define a new test function, for example, one that calculates the n-th element of the Fibonacci sequence iteratively:
>>> def fib(n):
... a, b = 0, 1
... for _ in range(n):
... a, b = b, a + b
... return a
...
Then, make sure to execute its body sufficiently many times before checking the corresponding micro-ops. You don’t need to import the reveal_code() function as long as you executed your uops module interactively:
>>> fib(10)
55
>>> reveal_code(fib)
Micro-ops unavailable
>>> fib(10)
55
>>> reveal_code(fib)
_START_EXECUTOR
_TIER2_RESUME_CHECK
_ITER_CHECK_RANGE
_GUARD_NOT_EXHAUSTED_RANGE
_ITER_NEXT_RANGE
_STORE_FAST_3
_LOAD_FAST_2
_LOAD_FAST_1
_LOAD_FAST_2
_GUARD_BOTH_INT
_BINARY_OP_ADD_INT
_STORE_FAST_2
_STORE_FAST_1
_JUMP_TO_TOP
_DEOPT
_EXIT_TRACE
_EXIT_TRACE
_ERROR_POP_N
_EXIT_TRACE
_ERROR_POP_N
When you call fib() with a relatively small value as an argument, it doesn’t trigger the Tier 2 interpreter. However, calling the function with the same argument again—or choosing a greater input value in the first place—reveals the micro-ops instructions. Notice that they all start with an underscore character (_) to differentiate them from regular opcodes.
You can assume that these micro-ops will eventually end up as machine code! That is, unless you built Python with the Tier 2 interpreter mode, which is generally meant for testing.
Now, repeat this experiment but disable the JIT by setting the PYTHON_JIT=0 environment variable when starting Python. It should prevent the interpreter from generating any micro-ops, keeping your code in the Tier 1 realm.
This all sounds great, but if you’re still not convinced about the JIT doing its job, then you might want to run some benchmarks to see the difference in performance. Next up, you’ll put the experimental features in Python 3.13 to the test.
Measure the Performance Improvements of Python 3.13
It’s worth noting that the benchmarks you’ll find in this section are somewhat artificial and don’t necessarily reflect real-world scenarios. Therefore, you should take them with a grain of salt or, better yet, perform your own assessment of free threading and the JIT compiler to see if they fit your particular needs. Above all, remember they’re still experimental features!
Note: Expect to run into occasional quirks and performance bottlenecks. For example, it seems that importing certain code under test for the first time prevents Python 3.13 from leveraging its new capabilities. But, the same code runs noticeably faster when you run it directly or trigger the compilation of the underlying bytecode.
You can do so by rerunning the main script that imports your code, or by using the compileall module beforehand:
$ python -m compileall /path/to/your/benchmarks/
This will create a local __pycache__ folder with all the necessary .pyc files that Python can use to speed up subsequent runs.
Numerous factors can affect a program’s performance. They include the nature of the problem at hand, your hardware setup, the system’s current workload, Python’s build configuration, and even the ambient room temperature! The execution times alone won’t tell you much unless you consider such variables and account for them in your analysis.
Below is a brief summary of the methodology used in this tutorial to draw conclusions about the performance of Python’s free threading and JIT. If you’d like to replicate this experiment, then you can follow these principles:
- Data Collection: Gather performance metrics from different Python builds with various feature sets enabled at runtime.
- Data Volume: Run the benchmark under small and heavy loads to measure how the performance scales, uncovering any fixed overhead.
- Baseline Comparison: Pick a baseline or compare how the different Python builds and their configurations stack up against each other.
- Process Automation: Automate data collection as much as possible to speed up the process and minimize human error.
- Controlled Environment: Use a Docker container to reproduce a consistent environment across different systems and platforms.
- Repetition: Repeat each run at least a few times to mitigate random system noise.
- Outliers Removal: Identify anomalies and remove the associated outliers from the collected data, which may be skewing your results.
- Best Time: Remove variable factors by considering only the best timing within each set of runs, which is the most accurate measurement.
By clicking on the link below, you can download the supporting materials, which include CSV files with empirical data points used for plotting the charts in this section:
Get Your Code: Click here to download the free sample code that shows you how to work with the experimental free threading and JIT compiler in Python 3.13.
You may generate similar CSV files using two benchmark scripts that you’ll find in the materials or the collapsible block below. But first, add the following function to your pyinfo module so that you can more conveniently retrieve the version and ABI flags of the current Python interpreter:
pyinfo.py
# ...
def python_short():
version = ".".join(map(str, sys.version_info[:2]))
abi = sys.abiflags
ft = FreeThreading()
if ft.supported:
return f"{version}{abi} (GIL {'off' if ft.enabled else 'on'})"
return f"{version}{abi}"
You’ll use this function to populate the python column in the resulting CSV files.
Now, grab the benchmark scripts from the supporting materials or reveal their source code by expanding this collapsible block:
Place boths script next to your pyinfo and pyfeatures modules. The first one is called gil.py:
gil.py
from argparse import ArgumentParser
from concurrent.futures import ThreadPoolExecutor
from csv import DictWriter
from functools import wraps
from os import cpu_count
from pathlib import Path
from time import perf_counter
from typing import NamedTuple
from pyinfo import print_details, python_short
CSV_PATH = Path(__file__).with_suffix(".csv")
DEFAULT_N = 35
class Record(NamedTuple):
python: str
threads: int
seconds: float
def save(self):
empty = not CSV_PATH.exists()
with CSV_PATH.open(mode="a", encoding="utf-8", newline="") as file:
writer = DictWriter(file, Record._fields)
if empty:
writer.writeheader()
writer.writerow(self._asdict())
def parse_args():
parser = ArgumentParser()
parser.add_argument("-t", "--threads", type=int, default=cpu_count())
parser.add_argument("-n", type=int, default=DEFAULT_N)
return parser.parse_args()
def main(args):
print_details()
benchmark(args.threads, args.n)
def timed(function):
@wraps(function)
def wrapper(num_threads, n):
t1 = perf_counter()
result = function(num_threads, n)
t2 = perf_counter()
duration = t2 - t1
print(f"\b\b\b: {duration:.2f}s")
Record(python_short(), num_threads, duration).save()
return result
return wrapper
@timed
def benchmark(num_threads, n):
with ThreadPoolExecutor(max_workers=num_threads) as executor:
for _ in range(num_threads):
executor.submit(fib, n)
if num_threads > 1:
print(f"Running {num_threads} threads...", end="", flush=True)
else:
print(f"Running 1 thread...", end="", flush=True)
def fib(n):
return n if n < 2 else fib(n - 2) + fib(n - 1)
if __name__ == "__main__":
main(parse_args())
This is how you can run the gil.py script and vary the number of threads executed concurrently:
$ python gil.py --threads=4
====================================================================
💻 Linux 64bit with 4x CPU cores (x86_64 Little Endian)
🐍 CPython 3.12.5 /home/realpython/.pyenv/versions/3.12.5/bin/python
Free Threading: unsupported
JIT Compiler: unsupported
====================================================================
Running 4 threads: 7.75s
By default, it’ll compute fib(35), which should be plenty enough. But you can increase the input parameter by specifying an optional -n argument in the command line should your computer be too powerful.
The other script has a similar structure and allows you to measure the execution time of the iterative version of the Fibonacci function:
jit.py
from argparse import ArgumentParser
from csv import DictWriter
from functools import wraps
from pathlib import Path
from time import perf_counter
from typing import NamedTuple
from pyfeatures import JitCompiler
from pyinfo import print_details, python_short
CSV_PATH = Path(__file__).with_suffix(".csv")
class Record(NamedTuple):
python: str
jit: str
n: int
seconds: float
def save(self):
empty = not CSV_PATH.exists()
with CSV_PATH.open(mode="a", encoding="utf-8", newline="") as file:
writer = DictWriter(file, Record._fields)
if empty:
writer.writeheader()
writer.writerow(self._asdict())
def parse_args():
parser = ArgumentParser()
parser.add_argument("-n", type=int, required=True)
return parser.parse_args()
def main(args):
print_details()
benchmark(args.n)
def timed(function):
jit = JitCompiler()
@wraps(function)
def wrapper(n):
t1 = perf_counter()
result = function(n)
t2 = perf_counter()
duration = t2 - t1
print(f"\b\b\b: {duration:.2f}s")
if jit.supported:
Record(python_short(), "on" if jit.enabled else "off", n, duration).save()
else:
Record(python_short(), "unsupported", n, duration).save()
return result
return wrapper
@timed
def benchmark(n):
print(f"Running fib() {n:,} times...", end="", flush=True)
for i in range(n):
fib(i)
def fib(n):
a, b = 0, 1
for _ in range(n):
a, b = b, a + b
return a
if __name__ == "__main__":
main(parse_args())
You must always specify the -n parameter for the fib() function when you run the jit.py script:
$ python jit.py -n 10000
====================================================================
💻 Linux 64bit with 4x CPU cores (x86_64 Little Endian)
🐍 CPython 3.12.5 /home/realpython/.pyenv/versions/3.12.5/bin/python
Free Threading: unsupported
JIT Compiler: unsupported
====================================================================
Running fib() 10,000 times: 6.40s
Running both scripts will create and populate the corresponding CSV file. The subsequent runs will append new rows to the file rather than overwrite it.
Alright. It’s time to dive into your first benchmark and determine if free threading in Python 3.13 can indeed deliver on its promises. You’ll be running a recursive version of the Fibonacci function, which is a classic example often used to test the efficiency of parallel execution.
Free Threading: Recursive Fibonacci
To evaluate the performance of multi-threaded code, choose a computationally intensive or CPU-bound problem to solve. The recursive Fibonacci formula is a perfect fit here because it’s relatively straightforward, yet it quickly becomes expensive to compute even for small input values. In contrast, most I/O-bound tasks handled by web servers will benefit little from free threading in Python 3.13 because they don’t inherently depend on the CPU.
You’ll run multiple instances of the same task simultaneously and observe how Python copes with each additional thread of execution. In an ideal world, the total execution time should remain more or less constant despite the increased workload until there are no more CPU cores to allocate. In practice, there’s always going to be a slight overhead associated with scheduling and coordinating the threads or synchronizing access to shared data.
After saturating all CPU cores, the performance should begin to drop linearly as if there was only one processing unit available. This is how Python has traditionally behaved on multi-core systems due to the GIL, which permitted only one thread to run at a time. Additionally, the excessive context switching that resulted from that has prevented Python from reaching the maximum CPU utilization.
Go ahead and run the gil.py benchmark against all Python versions that you built inside Docker. Make sure to take the JIT out of the picture by disabling it and toggle the GIL when applicable to see if free threading has any visible impact on the performance:
$ docker run --rm -it -v "$(pwd)":/app -w /app pythons
root@9509867f5da3:/app# PYTHON_JIT=0 python3.13t -X gil=1 gil.py --threads=4
The sample command above runs four threads on top of the free-threaded Python with the GIL enabled and JIT disabled. Suppressing the JIT with an environment variable has the same effect as running a Python build without JIT support.
After collecting enough data points by altering the number of threads, the GIL status, and Python builds, you can generate a chart similar to the one below to visualize the overall performance trends:
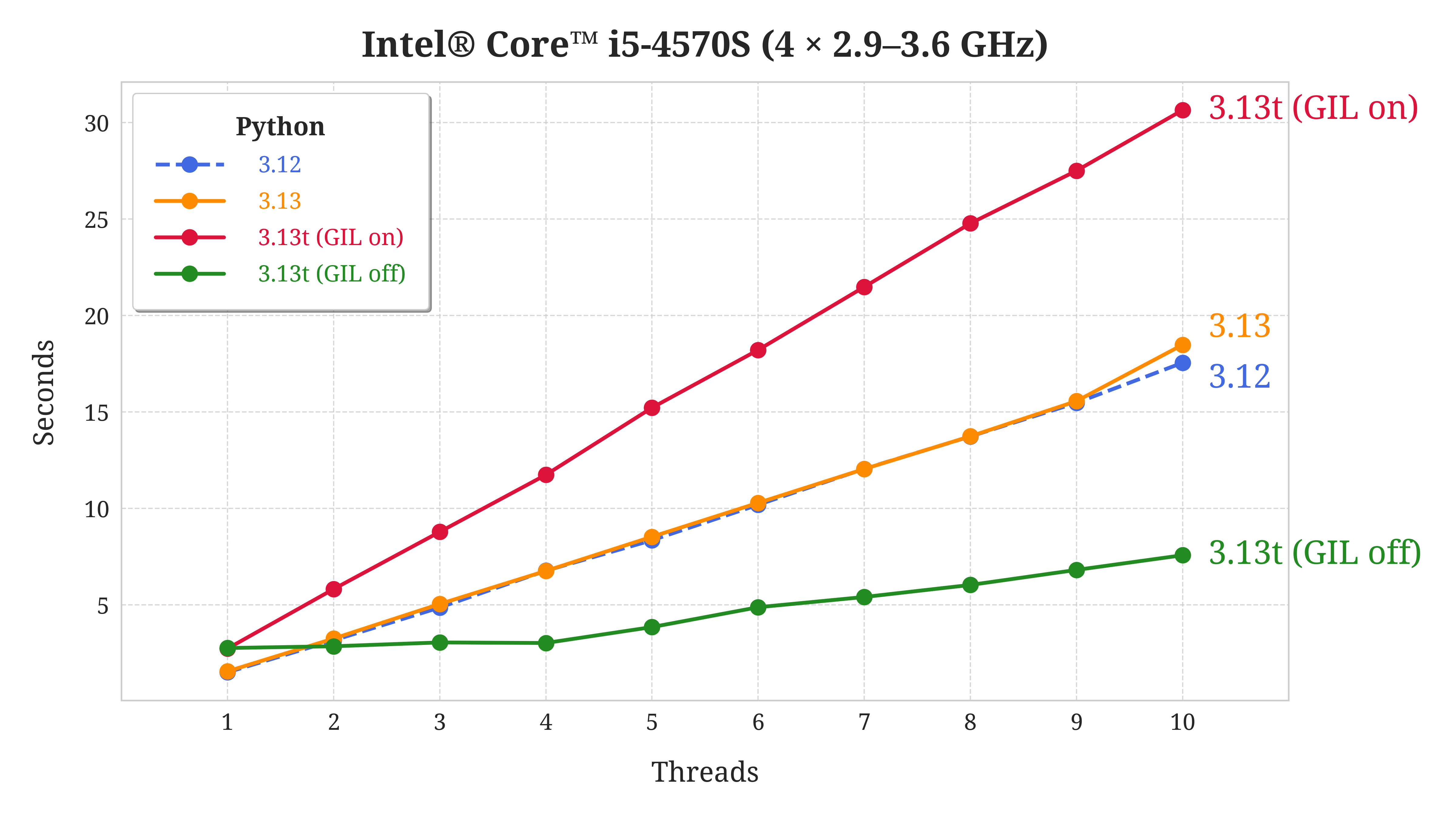
This particular system is an all-in-one computer featuring the Intel® Core™ i5-4570S processor, which comes with four physical cores that can independently execute one thread each. Here are the key takeaways from the chart illustrated above:
- Single-Threaded Case: When the number of threads is equal to one, which is still pretty common, then stock Python 3.13 (orange line) performs about the same as the previous Python version (blue-dashed line). However, the free-threaded build of Python 3.13, whether the GIL is on or off, takes almost twice as much time as Python 3.12 or stock Python 3.13 to execute single-threaded code.
- Multi-Threaded Case: Despite being slower in the single-threaded case, the free-threaded build of Python 3.13 with the GIL disabled (green line) is the only one that can run many threads in parallel. This is shown by the flat horizontal line spanning the first four threads. As predicted, that line begins to slope when the number of threads exceeds the available CPU cores. From there, it continues to climb at a constant rate like the others.
Here’s how the individual flavors of Python 3.13 compare to each other:
- Python 3.13: There’s no significant difference between the standard build of Python 3.13 and Python 3.12 in terms of performance. At least your code won’t run any slower if you stick to the official release.
- Python 3.13t (GIL disabled): Apart from the ability to run threads in parallel, the free-threaded build of Python 3.13 with the GIL disabled (green line) is the fastest overall. In fact, it performs better even when more threads are running than your CPU can simultaneously handle.
- Python 3.13t (GIL enabled): Surprisingly, enabling the GIL in a free-threaded Python 3.13 build (red line) results in the worst performance by far. This configuration of Python is much slower than both Python 3.12 and other variants of Python 3.13.
But don’t take these observations as absolute truth, as your mileage may vary depending on your specific task and hardware. Below are two more graphs representing an identical test in precisely the same Docker environment performed on portable computers. And yet, the graphs look quite different!
The first computer is a ThinkPad laptop with the Intel® Core™ i7-6600U processor. It has two physical cores that can run four threads in total thanks to the Hyper-Threading technology:
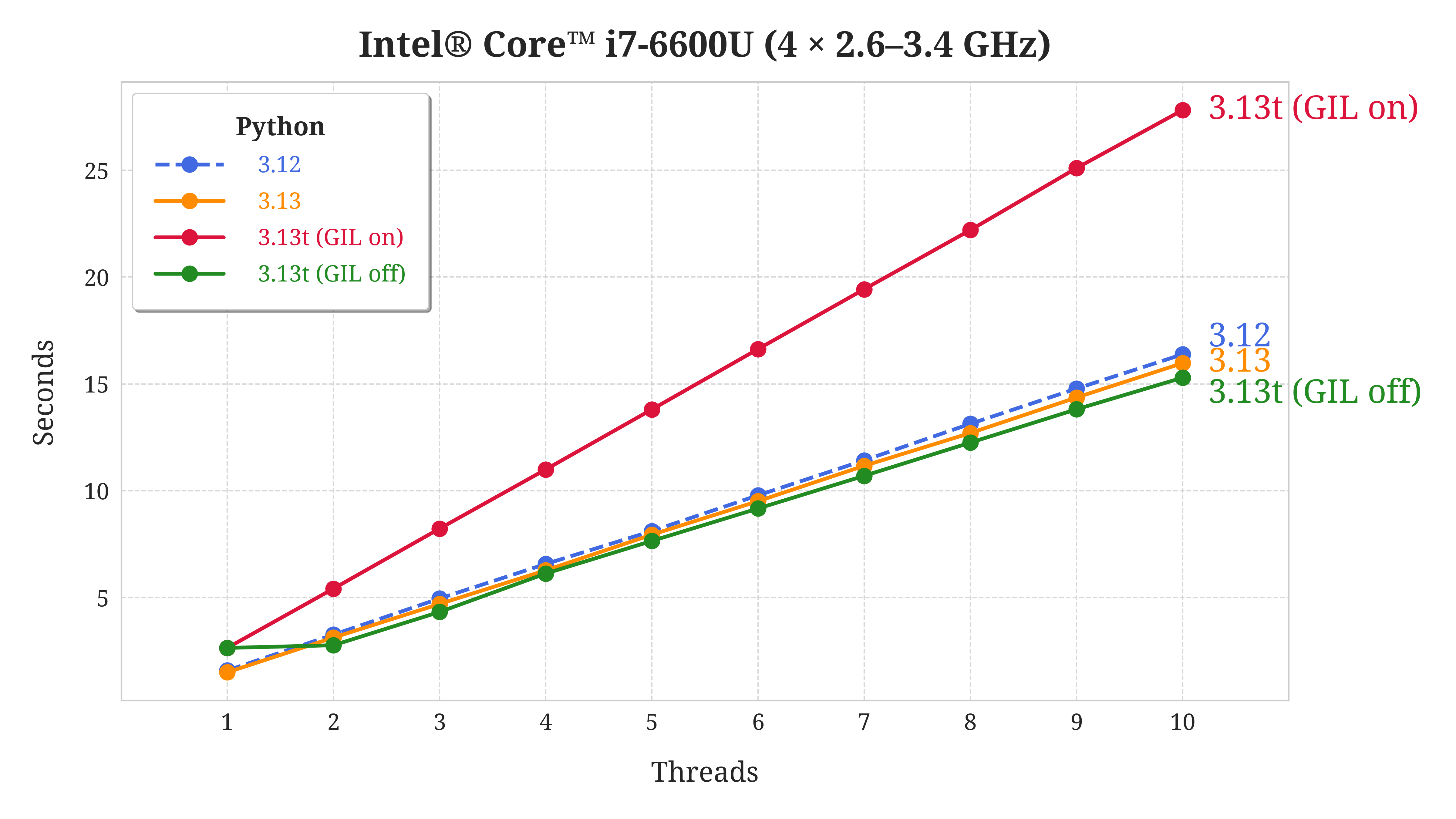
For some reason, the free-threaded build of Python 3.13 with the GIL disabled (green line) is able to leverage only two out of four logical cores for parallel execution. Again, when you enable the GIL in this build, it leads to the worst performance among all the versions. Other than that, Python 3.13 doesn’t offer a huge advantage over Python 3.12 on this machine.
The second device is a Microsoft Surface Laptop equipped with the Intel® Core™ i5-1035G7 processor, which has four physical cores on board that can run up to eight threads. This laptop is prone to CPU throttling under heavy workloads, which can result in slower processing times. To mitigate this, it’s important to ensure sufficient cooling by taking breaks so the fans can settle down.
If you take these precautions, then this is what you’ll get:
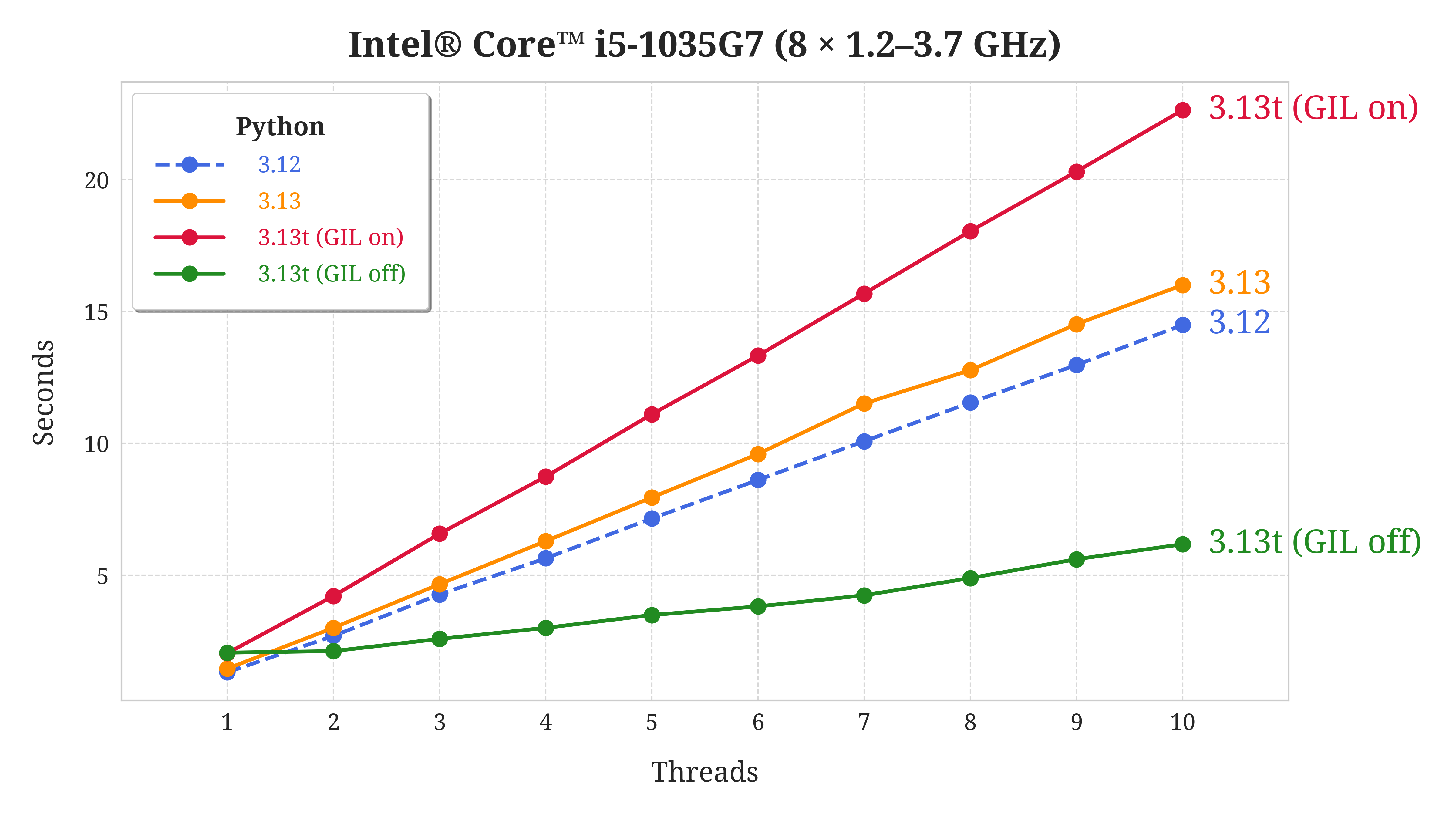
History repeats itself here because the free-threaded build of Python 3.13 with the GIL disabled (green line) can’t take advantage of more than two cores, even though there are eight of them! As before, enabling the GIL (red line) quickly degrades performance of this build.
What’s different this time is that the free-threaded Python 3.13 with the GIL disabled is the fastest by a large margin. Despite this advantage, stock Python 3.13 runs slower than the previous generation Python 3.12 on this laptop, unlike on the other two computers.
All in all, the number of CPU cores alone doesn’t always guarantee better performance. The potential benefits of disabling the GIL in Python 3.13 aren’t as clear-cut as one might expect, mainly due to the experimental nature of this feature. What’s been your experience with free threading?
JIT Compiler: Iterative Fibonacci
In the previous section, you measured the impact of free threading on performance by using a recursive formula for the Fibonacci sequence. It allowed you to quickly saturate the CPU by giving it mundane work to do. However, it was mainly self-referential function calls that kept your computer busy, which didn’t involve many bytecode instructions. To benchmark the JIT compiler in Python, you’ll need to devise something a bit more complex than that.
This is where the iterative implementation of the Fibonacci formula that you used before comes in handy again. When you run your jit.py script through a Python 3.13 build with JIT enabled, you probably won’t see a dramatic improvement in execution speed.
Note: To eliminate bias, you should run this benchmark against a Python build with JIT but no free-threading support.
In theory, you could reuse your existing free-threaded Python build while enabling the GIL at runtime to achieve a similar effect. However, you know from the previous section that this approach leads to abysmal performance. On the other hand, keeping the GIL disabled could skew the performance in the opposite direction, rendering both results unreliable.
If you decide to use the Docker file from the supporting materials, then it’ll make the necessary build for you, exposing Python 3.13 with only JIT under the python3.13j executable.
Keep in mind that the experimental JIT compiler has to analyze and translate Python bytecode into machine code while still running your program. That’s extra work, which you don’t get for free. That said, even though the JIT isn’t expected to overtake stock Python at the moment, it still offers a tiny performance boost in the single-threaded execution mode:
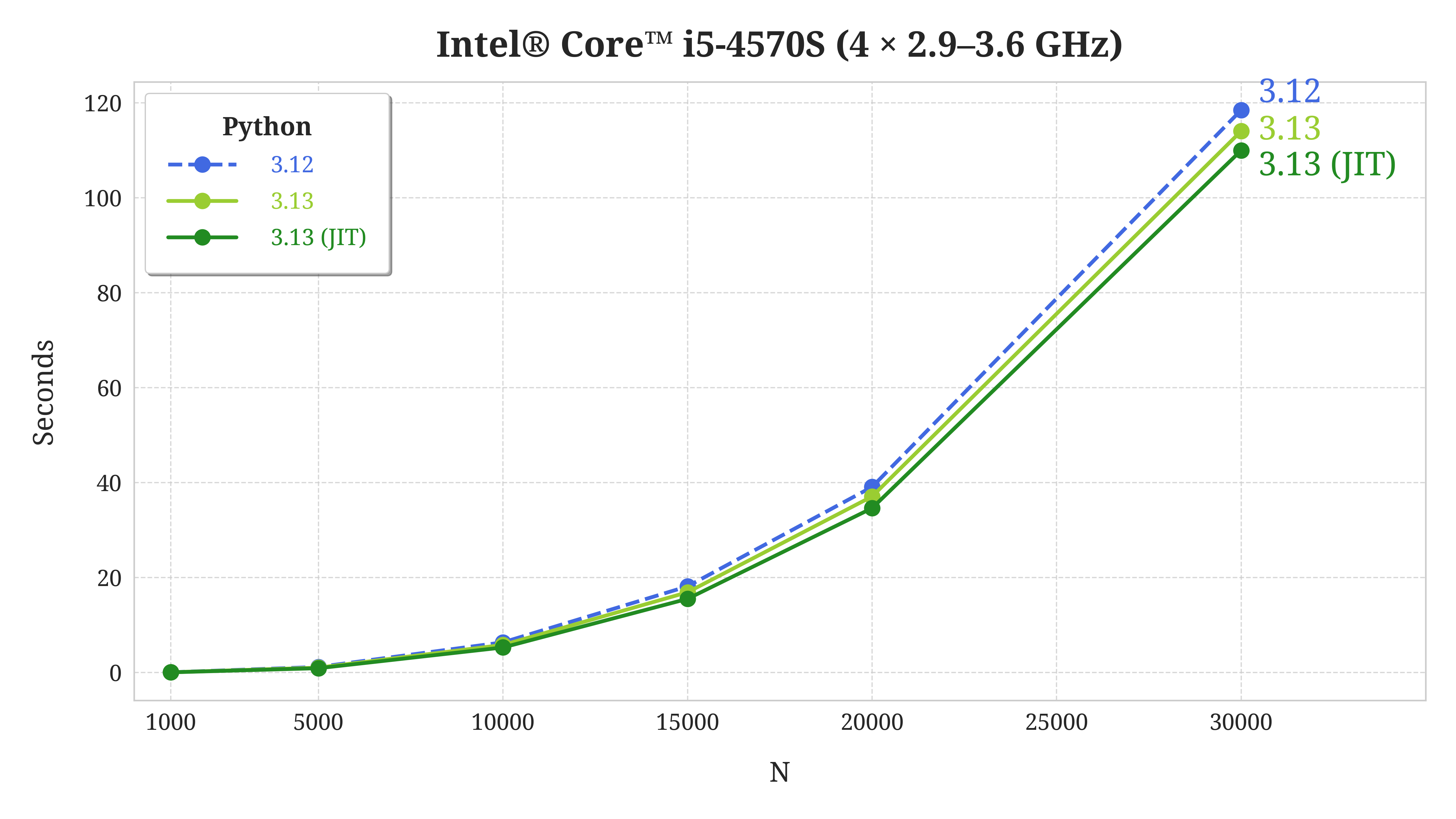
The horizontal axis represents the size of the input data, which coincides with the amount of computation required. As the workload increases, so does the performance gain from using the JIT. These results are consistent across different devices, unlike the free-threading benchmark.
In this case, the improvement is in the order of a few percent, which isn’t a lot. However, other types of problems may benefit more from just-in-time compilation, and the long-term plan is to continue optimizing and expanding its capabilities.
Make a C Extension Module for Python 3.13 and Later
As mentioned at the beginning of this tutorial, Python 3.13 will come in two flavors due to the incompatible application binary interface (ABI) of the stock and free-threaded builds. This dual nature of Python will last until free threading matures enough to become the default in the mainstream or is ultimately abandoned as a failed experiment.
The consequence of this is that you won’t be able to import C extension modules compiled for the stock version of Python in its free-threaded counterpart. The reverse is also true, so maintainers will be forced to target both runtime environments by uploading separate wheels to the Python Package Index (PyPI).
Note: This problem only affects C extension modules as opposed to pure-Python packages like the Requests library.
But Python’s ABI is only part of the picture. In reality, you need a separate wheel for each combination of the Python version, its particular implementation, ABI flags, operating system, and hardware architecture. When you combine them, you end up with a Cartesian product of all these variables, which can be challenging to maintain.
Consider the popular NumPy library, whose maintainers have proactively provided wheels for Python 3.13 before its full release. They did this ahead of time to ensure sufficient time for testing compatibility with the upcoming Python version. If you look at their GitHub release page or the corresponding downloads page on PyPI, you’ll find that a single release of NumPy 2.1.0 resulted in as many as eighteen wheels targeting just Python 3.13:
| NumPy | Python | ABI | Platform | Architecture |
|---|---|---|---|---|
| 2.1.0 | CPython 3.13 | - | Linux (musl 1.1) | 64-bit x86 |
| 2.1.0 | CPython 3.13 | - | Linux (musl 1.2) | 64-bit ARM |
| 2.1.0 | CPython 3.13 | - | ManyLinux 2.17 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | - | ManyLinux 2.17 | 64-bit x86 |
| 2.1.0 | CPython 3.13 | - | Windows 32-bit | - |
| 2.1.0 | CPython 3.13 | - | Windows 64-bit (AMD64) | - |
| 2.1.0 | CPython 3.13 | - | macOS 10.13 | 64-bit x86 |
| 2.1.0 | CPython 3.13 | - | macOS 11.0 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | - | macOS 14.0 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | - | macOS 14.0 | 64-bit x86 |
| 2.1.0 | CPython 3.13 | t | Linux (musl 1.1) | 64-bit x86 |
| 2.1.0 | CPython 3.13 | t | Linux (musl 1.2) | 64-bit ARM |
| 2.1.0 | CPython 3.13 | t | ManyLinux 2.17 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | t | ManyLinux 2.17 | 64-bit x86 |
| 2.1.0 | CPython 3.13 | t | macOS 10.13 | 64-bit x86 |
| 2.1.0 | CPython 3.13 | t | macOS 11.0 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | t | macOS 14.0 | 64-bit ARM |
| 2.1.0 | CPython 3.13 | t | macOS 14.0 | 64-bit x86 |
Notice that almost half of these distribution packages target the free-threaded Python, as indicated by the letter “t” in the ABI column. There might be even more wheel files per release in the future—for example, once PyPy catches up with CPython since NumPy targets it as well.
Note: If you’re unsure about your current Python build, then you can check its ABI flags using the python-config tool or the sys.abiflags property:
$ python-config --abiflags
t
$ python -q
>>> import sys
>>> sys.abiflags
't'
The letter “t” indicates a free-threaded flavor. On the other hand, there will usually be no special flags in the vanilla Python build.
Now it’s time to learn the basics of creating C extension modules for both ABI variants of Python 3.13. Along the way, you’ll discover the importance of ensuring thread safety in your code.
Implement a Bare-Bones Extension Module
By the time you’re reading this tutorial, you may get away with not having to write a C extension module by hand. As soon as the mypy project publishes a release for Python 3.13, you’ll be able to use mypyc to transpile your Python code straight into a C extension, which the tool will automatically build for you.
Until then, you’ll need to brush up on your C programming skills and use the Python API to create an extension module. For the purposes of this example, you’ll implement a minimal greeter module with a single greet() function that takes an optional argument and returns a string:
>>> from greeter import greet
>>> greet()
'Hello, anonymous!'
>>> greet("John")
'Hello, John!'
When you call your function with no arguments, it returns a generic message. Otherwise, it makes the message more personalized by including the provided name.
Here’s the complete source code of the greeter module, which you should place in a file named greeter.c:
greeter.c
#include <Python.h>
static PyObject* greeter_greet(PyObject* self, PyObject* args) {
const char *name = "anonymous";
if (!PyArg_ParseTuple(args, "|s", &name)) {
return NULL;
}
return PyUnicode_FromFormat("Hello, %s!", name);
}
static PyMethodDef greeter_methods[] = {
{"greet", greeter_greet, METH_VARARGS, "Greet someone"},
{NULL, NULL, 0, NULL}
};
static struct PyModuleDef greeter = {
PyModuleDef_HEAD_INIT,
"greeter",
"Greeting module",
-1,
greeter_methods
};
PyMODINIT_FUNC PyInit_greeter(void) {
return PyModule_Create(&greeter);
}
The code starts with an include directive followed by the Python.h header file, which brings in the necessary Python API definitions, such as the PyObject type and various other functions. Next, it defines the most important function, greeter_greet(), that will be exposed to Python. The remaining part of the file wraps your function in boilerplate code that Python demands.
The next step is to compile this high-level C code into machine code embedded in a shared object, which you can load dynamically into Python using the import statement.
Compile the Module Into a Shared Object
First, you need to locate Python.h that you’ve included in your C code, along with other header files that might be its indirect dependencies. To do so, you can leverage the python-config tool you saw earlier. Just make sure to run the correct executable associated with the Python interpreter you want your C extension module to target. Either specify an absolute path to the tool or append the desired Python version suffix like so:
$ which python3.13-config
/usr/local/bin/python3.13-config
$ python3.13-config --includes
-I/usr/local/include/python3.13 -I/usr/local/include/python3.13
Because the python3.13-config executable can be found on the PATH, you don’t have to type its full path. The command returns flags for the C compiler, which you’ll run in a moment.
If you still have your Docker image with the different Python versions hanging around, then you can use it to compile the greeter module. This Docker image already has the necessary build tools and Python header files, so it’s only a matter of mounting a local volume to access the source code on your host machine.
Navigate to a directory where you have the code to compile and type the following command:
$ docker run --rm -it -v "$(pwd)":/app -w /app pythons
This starts a new Docker container with your current working directory mounted as /app inside the container. Once you’re in there, you can find the necessary header files and compile your C extension module, targeting both Python 3.13 variants:
root@e0dcf4aaa30d:/app# CFLAGS='-shared -fPIC -O3'
root@e0dcf4aaa30d:/app# gcc greeter.c $CFLAGS \
$(python3.13-config --includes) \
-o greeter_stock.so
root@e0dcf4aaa30d:/app# gcc greeter.c $CFLAGS \
$(python3.13t-config --includes) \
-o greeter_threaded.so
You define the CFLAGS environment variable with some common compiler flags, which are required to build a shared object library. Then you compile greeter.c into two binary files using the stock and free-threaded header files, which you locate with the corresponding configuration tools. Go ahead and close your Docker container now.
As long as everything worked correctly, you should see two new files on your host machine:
$ ls -l
total 36
-rw-rw-r-- 1 realpython realpython 600 Aug 28 14:03 greeter.c
-rwxr-xr-x 1 root root 16024 Aug 28 14:25 greeter_stock.so
-rwxr-xr-x 1 root root 16024 Aug 28 14:25 greeter_threaded.so
$ diff greeter_stock.so greeter_threaded.so
Binary files greeter_stock.so and greeter_threaded.so differ
Even though the resulting .so files may be the same size, they most certainly differ in content. You’ll notice that difference when you try to import them in Python.
Import the Compiled Module Into Python 3.13
At the moment, you can’t import your compiled extension modules directly into Python because they don’t conform to the naming conventions expected by the interpreter. A shared object file should generally be named after your extension module declared in the original C source code. In this case, the correct filename is greeter.so:
Note: You may optionally communicate the specific Python implementation and platform that your extension module is intended for. Here’s a short Python code snippet that can figure out these details for you:
>>> import sysconfig
>>> def encode(module):
... suffix = sysconfig.get_config_var("EXT_SUFFIX")
... return f"{module}{suffix}"
...
>>> encode("greeter")
'greeter.cpython-312-x86_64-linux-gnu.so'
If you named your shared object file like this, then you’d only be able to attempt importing the corresponding extension module in an environment that matches the given signature.
Under these circumstances, you’d be able to find the local greeter module within CPython 3.12 running on a 64-bit Linux distribution. But any other configuration would prevent Python from recognizing this shared object as a legitimate extension module:
$ python3.12 -c 'import greeter'
$ python3.13 -c 'import greeter'
Traceback (most recent call last):
File "<string>", line 1, in <module>
import greeter
ModuleNotFoundError: No module named 'greeter'
In real life, including an extension suffix in shared objects is recommended because it ensures compatibility between the extension module and the Python interpreter. This is why build tools like setuptools append it by default. However, you’ll intentionally omit the filename suffix in this tutorial to demonstrate a problem in Python 3.13 stemming from incompatible binary interfaces of extension modules.
To work around the file naming violation, create a symbolic link, or symlink for short, pointing to one of your shared object files and give it a proper name:
$ ln -s greeter_stock.so greeter.so
$ file greeter.so
greeter.so: symbolic link to greeter_stock.so
Because greeter.so points to the extension module compiled against the stock build of Python 3.13, you can safely import it in the corresponding interpreter, and it’ll work as expected. In contrast, doing so in the free-threaded Python build will result in an unexpected segmentation fault:
$ CODE='import greeter; print(greeter.greet("John"))'
$ python3.13 -c "$CODE"
Hello, John!
$ python3.13t -c "$CODE"
Segmentation fault (core dumped)
It’s a dreadful error with several possible causes, indicating a serious memory management problem. If you’re determined enough, then you may recompile your modules with extra debugging information (-g) and investigate the underlying C function call stack using tools like the GNU Debugger. This will give you an idea of what might be going wrong. However, it really boils down to an incompatible Python ABI between the module and the interpreter.
What about the other way around? To find out, update your symlink so that it references greeter_threaded.so. Make sure to remove your existing link with the unlink command first:
$ unlink greeter.so
$ ln -s greeter_threaded.so greeter.so
$ file greeter.so
greeter.so: symbolic link to greeter_threaded.so
Now that you switched to the free-threaded version of the shared object, repeat your experiment and run the sample test code in both Python 3.13 builds:
$ python3.13 -c "$CODE"
Segmentation fault (core dumped)
$ python3.13t -c "$CODE"
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock
⮑ (GIL) has been enabled to load module 'greeter', which has not declared that
⮑ it can run safely without the GIL. To override this behavior and keep the
⮑ GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
Hello, John!
As you might expect, the free-threaded module crashes stock Python, highlighting the importance of matching the module to the correct interpreter. Although the specific error is slightly different than before, the root cause of the issue remains the same—an incompatible Python ABI.
Notice that importing the free-threaded module in a free-threaded Python build has a twist. On the one hand, the program completes successfully by printing the expected message, but on the other hand, it prominently displays a lengthy warning, which you shouldn’t ignore.
It turns out that C extension modules targeting the free-threaded build of Python 3.13 need special handling to be fully compatible. You’ll explore this topic in the next section.
Mark the Extension Module as Thread-Safe
According to the warning you just saw, Python can’t determine whether your extension module is thread-safe because it doesn’t explicitly state so. As a result, Python temporarily turns off free threading as a precautionary measure. In other words, it enables the GIL to ensure that your code can run safely in a multi-threaded environment. Here’s a code snippet to confirm that:
>>> import sys
>>> sys._is_gil_enabled()
False
>>> import greeter
<frozen importlib._bootstrap>:488: RuntimeWarning: The global interpreter lock
⮑ (GIL) has been enabled to load module 'greeter', which has not declared that
⮑ it can run safely without the GIL. To override this behavior and keep the
⮑ GIL disabled (at your own risk), run with PYTHON_GIL=0 or -Xgil=0.
>>> sys._is_gil_enabled()
True
Even though the GIL was disabled when you started the Python REPL, importing your extension module turned it back on again. Python takes this conservative approach by default, which you can override by setting the PYTHON_GIL=0 environment variable or passing the -X gil=0 option to the interpreter:
$ python3.13t -q -X gil=0
>>> import greeter
>>> import sys
>>> sys._is_gil_enabled()
False
There’s no warning anymore, and the GIL remains disabled, which means that multiple threads can freely run your extension module in parallel. However, this comes with the risk of potential race conditions and other threading issues if your extension module isn’t actually thread-safe! Remember that it’s your responsibility as the author to ensure that your code can run without the GIL.
To declare that the greeter module doesn’t rely on the GIL to function properly, you must explicitly mark it as safe for free threading. Below are the necessary changes to your C code, which you can put in a separate file for clarity:
greeter_threaded.c
#include <Python.h>
static PyObject* greeter_greet(PyObject* self, PyObject* args) {
const char *name = "anonymous";
if (!PyArg_ParseTuple(args, "|s", &name)) {
return NULL;
}
return PyUnicode_FromFormat("Hello, %s!", name);
}
static PyMethodDef greeter_methods[] = {
{"greet", greeter_greet, METH_VARARGS, "Greet someone"},
{NULL, NULL, 0, NULL}
};
static int greeter_exec(PyObject *module) {
return 0;
}
static PyModuleDef_Slot greeter_slots[] = {
{Py_mod_exec, greeter_exec},
{Py_mod_gil, Py_MOD_GIL_NOT_USED},
{0, NULL}
};
static struct PyModuleDef greeter = {
PyModuleDef_HEAD_INIT,
"greeter",
"Greeting module",
0,
greeter_methods,
greeter_slots,
};
PyMODINIT_FUNC PyInit_greeter(void) {
return PyModuleDef_Init(&greeter);
}
Instead of calling PyModule_Create(), you use an alternative method to initialize your extension module as described in the PEP 489 document. This multi-phase initialization allows you to define the Py_mod_gil slot, which can take either the Py_MOD_GIL_USED or Py_MOD_GIL_NOT_USED macro. These macros tell the interpreter if your module depends on the presence of the GIL and if it’s okay to access a shared state without costly synchronization.
Now, recompile your new greeter_threaded.c module using Docker in much the same way as you did before:
$ docker run --rm -it -v "$(pwd)":/app -w /app pythons
root@e0dcf4aaa30d:/app# gcc greeter_threaded.c \
$(python3.13t-config --includes) \
-shared -fPIC -O3 -o greeter_threaded.so
This will overwrite greeter_threaded.so with a slightly larger binary file. As long as you haven’t changed or removed your greeter.so symlink, it should still reference the correct shared object and let you import the greeter module:
$ python3.13t -c 'import greeter'
$ python3.13 -c 'import greeter'
Traceback (most recent call last):
File "<string>", line 1, in <module>
import greeter
ValueError: module functions cannot set METH_CLASS or METH_STATIC
Everything works as expected when you import greeter into the free-threaded Python build. Conversely, importing it into the standard Python build results in a runtime exception because of the unrecognized slot during the module’s initialization.
To sum up what you’ve learned, always use extension modules compatible with your specific Python 3.13 build to avoid problems. If you maintain one yourself, then you’ll need to compile more than one shared object targeting a different Python ABI.
Conclusion
Python 3.13 brings two experimental features that open the gateway to much better performance in future releases. These groundbreaking changes will require thorough testing, which is why they’re not currently enabled by default. However, you can try out free threading and the JIT compiler today by building Python from source code.
In this tutorial, you’ve:
- Compiled a custom Python build from source using Docker
- Disabled the Global Interpreter Lock (GIL) in Python
- Enabled the Just-In-Time (JIT) compiler for Python code
- Determined the availability of new features at runtime
- Assessed the performance improvements in Python 3.13
- Made a C extension module targeting Python’s new ABI
What do you think of the new experimental features in Python? Have you tried them yet? Share your experiences in the comments below.
Get Your Code: Click here to download the free sample code that shows you how to work with the experimental free threading and JIT compiler in Python 3.13.
Take the Quiz: Test your knowledge with our interactive “Python 3.13: Free Threading and a JIT Compiler” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python 3.13: Free Threading and a JIT CompilerIn this quiz, you'll test your understanding of the new features in Python 3.13. You'll revisit how to compile a custom Python build, disable the Global Interpreter Lock (GIL), enable the Just-In-Time (JIT) compiler, and more.






