
At some point in your Python journey, you may need to find the first item that matches a certain criterion in a Python iterable, such as a list or dictionary.
The simplest case is that you need to confirm that a particular item exists in the iterable. For example, you want to find a name in a list of names or a substring inside a string. In these cases, you’re best off using the in operator. However, there are many use cases when you may want to look for items with specific properties. For instance, you may need to:
- Find a non-zero value in a list of numbers
- Find a name of a particular length in a list of strings
- Find and modify a dictionary in a list of dictionaries based on a certain attribute
This tutorial will cover how best to approach all three scenarios. One option is to transform your whole iterable to a new list and then use .index() to find the first item matching your criterion:
>>> names = ["Linda", "Tiffany", "Florina", "Jovann"]
>>> length_of_names = [len(name) for name in names]
>>> idx = length_of_names.index(7)
>>> names[idx]
'Tiffany'
Here, you’ve used .index() to find that "Tiffany" is the first name in your list with seven characters. This solution isn’t great, partly because you calculate the criterion for all elements, even if the first item is a match.
In the above situations, you’re searching for a calculated property of the items you’re iterating over. In this tutorial, you’ll learn how to match such a derived attribute without needing to do unnecessary calculations.
Sample Code: Click here to download the free source code that you’ll use to find the first match in a Python list or iterable.
How to Get the First Matching Item in a Python List
You may already know about the in Python operator, which can tell you if an item is in an iterable. While this is the most efficient method that you can use for this purpose, sometimes you may need to match based on a calculated property of the items, like their lengths.
For example, you might be working with a list of dictionaries, typical of what you might get when processing JSON data. Check out this data that was obtained from country-json:
>>> countries = [
... {"country": "Austria", "population": 8_840_521},
... {"country": "Canada", "population": 37_057_765},
... {"country": "Cuba", "population": 11_338_138},
... {"country": "Dominican Republic", "population": 10_627_165},
... {"country": "Germany", "population": 82_905_782},
... {"country": "Norway", "population": 5_311_916},
... {"country": "Philippines", "population": 106_651_922},
... {"country": "Poland", "population": 37_974_750},
... {"country": "Scotland", "population": 5_424_800},
... {"country": "United States", "population": 326_687_501},
... ]
You might want to grab the first dictionary that has a population of over one hundred million. The in operator isn’t a great choice for two reasons. One, you’d need to have the full dictionary to match it, and two, it wouldn’t return the actual object but a Boolean value:
>>> target_country = {"country": "Philippines", "population": 106_651_922}
>>> target_country in countries
True
There’s no way to use in if you need to find the dictionary based on an attribute of the dictionary, such as population.
The most readable way to find and manipulate the first element in the list based on a calculated value is to use a humble for loop:
>>> for country in countries:
... if country["population"] > 100_000_000:
... print(country)
... break
...
{"country": "Philippines", "population": 106651922}
Instead of printing the target object, you can do anything you like with it in the for loop body. After you’re done, be sure to break the for loop so that you don’t needlessly search the rest of the list.
Note: Using the break statement applies if you’re looking for the first match from the iterable. If you’re looking to get or process all of the matches, then you can do without break.
The for loop approach is the one taken by the first package, which is a tiny package that you can download from PyPI that exposes a general-purpose function, first(). This function returns the first truthy value from an iterable by default, with an optional key parameter to return the first value truthy value after it’s been passed through the key argument.
Note: On Python 3.10 and later, you can use structural pattern matching to match these kinds of data structures in a way that you may prefer. For example, you can look for the first country with a population of more than one hundred million as follows:
>>> for country in countries:
... match country:
... case {"population": population} if population > 100_000_000:
... print(country)
... break
...
{'country': 'Philippines', 'population': 106651922}
Here, you use a guard to only match certain populations.
Using structural pattern matching instead of regular conditional statements can be more readable and concise if the matching patterns are complex enough.
Later in the tutorial, you’ll implement your own variation of the first() function. But first, you’ll look into another way of returning a first match: using generators.
Using Python Generators to Get the First Match
Python generator iterators are memory-efficient iterables that can be used to find the first element in a list or any iterable. They’re a core feature of Python, being used extensively under the hood. It’s likely you’ve already used generators without even knowing it!
The potential issue with generators is that they’re a bit more abstract and, as such, not quite as readable as for loops. You do get some performance benefits from generators, but these benefits are often negligible when the importance of readability is taken into consideration. That said, using them can be fun and really level up your Python game!
In Python, you can make a generator in various ways, but in this tutorial you’ll be working with generator comprehensions:
>>> gen = (country for country in countries)
>>> next(gen)
{'country': 'Austria', 'population': 8840521}
>>> next(gen)
{'country': 'Canada', 'population': 37057765}
Once you’ve defined a generator iterator, you can then call the next() function with the generator, producing the countries one by one until the countries list is exhausted.
To find the first element matching a certain criteria in a list, you can add a conditional expression to the generator comprehension so the resulting iterator will only yield items that match your criteria. In the following example, you use a conditional expression to generate items based on whether their population attribute is over one hundred million:
>>> gen = (
... country for country in countries
... if country["population"] > 100_000_000
... )
>>> next(gen)
{'country': 'Philippines', 'population': 106651922}
So now the generator will only produce dictionaries with a population attribute of over one hundred million. This means that the first time you call next() with the generator iterator, it’ll yield the first element that you’re looking for in the list, just like the for loop version.
Note: You’ll get an exception if you call next() and there’s no match or the generator is exhausted. To prevent this, you can pass in a default argument to next():
>>> next(gen, None)
{'country': 'United States', 'population': 326687501}
>>> next(gen, None)
Once the generator has finished producing matches, it’ll return the default value passed in. Since you’re returning None, you get no output on the REPL. If you hadn’t passed in the default value, you’d get a StopIteration exception.
In terms of readability, a generator isn’t quite as natural as a for loop. So why might you want to use one for this purpose? In the next section, you’ll be doing a quick performance comparison.
Comparing the Performance Between Loops and Generators
As always when measuring performance, you shouldn’t read too much into any one set of results. Instead, design a test for your own code with your own real-world data before you make any important decisions. You also need to weigh complexity against readability—perhaps shaving off a few milliseconds just isn’t worth it!
For this test, you’ll want to create a function that can create lists of an arbitrary size with a certain value at a certain position:
>>> from pprint import pp
>>> def build_list(size, fill, value, at_position):
... return [value if i == at_position else fill for i in range(size)]
...
>>> pp(
... build_list(
... size=10,
... fill={"country": "Nowhere", "population": 10},
... value={"country": "Atlantis", "population": 100},
... at_position=5,
... )
... )
[{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Atlantis', 'population': 100},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10},
{'country': 'Nowhere', 'population': 10}]
The build_list() function creates a list filled with identical items. All items in the list, except for one, are copies of the fill argument. The single outlier is the value argument, and it’s placed at the index provided by the at_position argument.
You imported pprint and used it to output the built list to make it more readable. Otherwise, the list would appear on one single line by default.
With this function, you’ll be able to create a large set of lists with the target value at various positions in the list. You can use this to compare how long it takes to find an element at the start and at the end of the list.
To compare for loops and generators, you’ll want two more basic functions that are hard-coded to find a dictionary with a population attribute over fifty:
def find_match_loop(iterable):
for value in iterable:
if value["population"] > 50:
return value
return None
def find_match_gen(iterable):
return next(
(value for value in iterable if value["population"] > 50),
None
)
The functions are hard-coded to keep things simple for the test. In the next section, you’ll be creating a reusable function.
With these basic components in place, you can set up a script with timeit to test both matching functions with a series of lists with the target position and different locations in the list:
from timeit import timeit
TIMEIT_TIMES = 100
LIST_SIZE = 500
POSITION_INCREMENT = 10
def build_list(size, fill, value, at_position): ...
def find_match_loop(iterable): ...
def find_match_gen(iterable): ...
looping_times = []
generator_times = []
positions = []
for position in range(0, LIST_SIZE, POSITION_INCREMENT):
print(
f"Progress {position / LIST_SIZE:.0%}",
end=f"{3 * ' '}\r", # Clear previous characters and reset cursor
)
positions.append(position)
list_to_search = build_list(
LIST_SIZE,
{"country": "Nowhere", "population": 10},
{"country": "Atlantis", "population": 100},
position,
)
looping_times.append(
timeit(
"find_match_loop(list_to_search)",
globals=globals(),
number=TIMEIT_TIMES,
)
)
generator_times.append(
timeit(
"find_match_gen(list_to_search)",
globals=globals(),
number=TIMEIT_TIMES,
)
)
print("Progress 100%")
This script will produce two parallel lists, each containing the time it took to find the element with either the loop or the generator. The script will also produce a third list that’ll contain the corresponding position of the target element in the list.
You aren’t doing anything with the results yet, and ideally you want to chart these out. So, check out the following completed script that uses matplotlib to produce a couple of charts from the output:
# chart.py
from timeit import timeit
import matplotlib.pyplot as plt
TIMEIT_TIMES = 1000 # Increase number for smoother lines
LIST_SIZE = 500
POSITION_INCREMENT = 10
def build_list(size, fill, value, at_position):
return [value if i == at_position else fill for i in range(size)]
def find_match_loop(iterable):
for value in iterable:
if value["population"] > 50:
return value
def find_match_gen(iterable):
return next(value for value in iterable if value["population"] > 50)
looping_times = []
generator_times = []
positions = []
for position in range(0, LIST_SIZE, POSITION_INCREMENT):
print(
f"Progress {position / LIST_SIZE:.0%}",
end=f"{3 * ' '}\r", # Clear previous characters and reset cursor
)
positions.append(position)
list_to_search = build_list(
size=LIST_SIZE,
fill={"country": "Nowhere", "population": 10},
value={"country": "Atlantis", "population": 100},
at_position=position,
)
looping_times.append(
timeit(
"find_match_loop(list_to_search)",
globals=globals(),
number=TIMEIT_TIMES,
)
)
generator_times.append(
timeit(
"find_match_gen(list_to_search)",
globals=globals(),
number=TIMEIT_TIMES,
)
)
print("Progress 100%")
fig, ax = plt.subplots()
plot = ax.plot(positions, looping_times, label="loop")
plot = ax.plot(positions, generator_times, label="generator")
plt.xlim([0, LIST_SIZE])
plt.ylim([0, max(max(looping_times), max(generator_times))])
plt.xlabel("Index of element to be found")
plt.ylabel(f"Time in seconds to find element {TIMEIT_TIMES:,} times")
plt.title("Raw Time to Find First Match")
plt.legend()
plt.show()
# Ratio
looping_ratio = [loop / loop for loop in looping_times]
generator_ratio = [
gen / loop for gen, loop in zip(generator_times, looping_times)
]
fig, ax = plt.subplots()
plot = ax.plot(positions, looping_ratio, label="loop")
plot = ax.plot(positions, generator_ratio, label="generator")
plt.xlim([0, LIST_SIZE])
plt.ylim([0, max(max(looping_ratio), max(generator_ratio))])
plt.xlabel("Index of element to be found")
plt.ylabel("Speed to find element, relative to loop")
plt.title("Relative Speed to Find First Match")
plt.legend()
plt.show()
Depending on the system that you’re running and the values for TIMEIT_TIMES, LIST_SIZE, and POSITION_INCREMENT that you use, running the script can take a while, but it should produce one chart that shows the times plotted against each other:
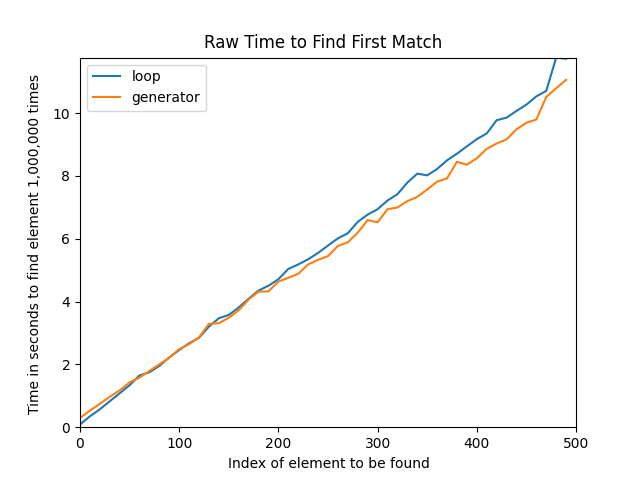
Additionally, after closing the first chart, you’ll get another chart that shows the ratio between the two strategies:
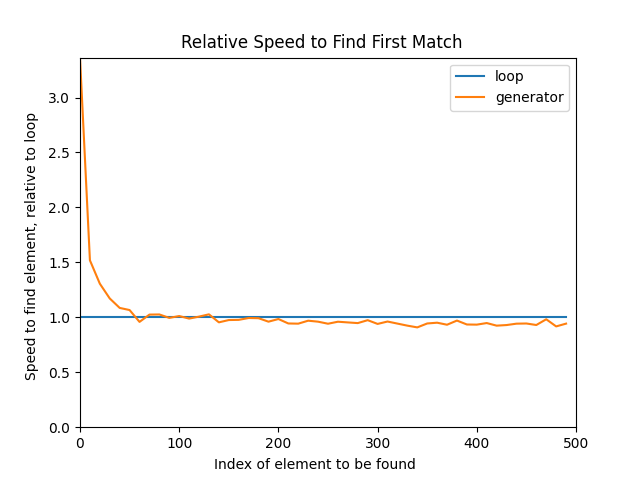
This last chart clearly illustrates that in this test, when the target item is near the beginning of the iterator, generators are far slower than for loops. However, once the element to find is at position 100 or greater, generators beat the for loop quite consistently and by a fair margin:
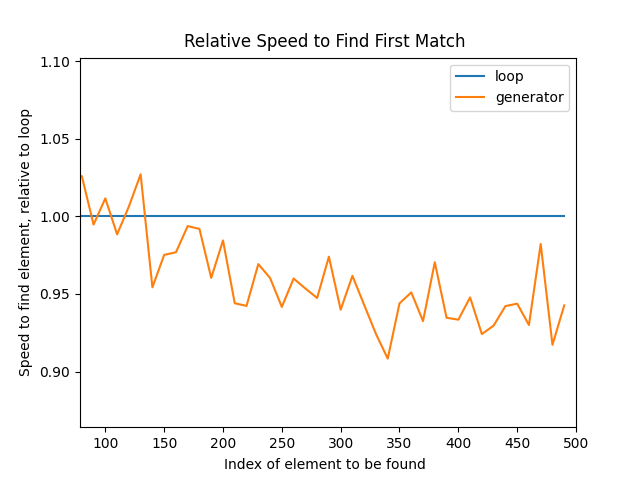
You can interactively zoom in on the previous chart with the magnifying glass icon. The zoomed chart shows that there’s a performance gain of around five or six percent. Five percent may not be anything to write home about, but it’s also not negligible. Whether it’s worth it for you depends on the specific data that you’ll be using, and how often you need to use it.
Note: For low values of TIMEIT_TIMES, you’ll often get spikes in the chart, which are an inevitable side effect of testing on a computer that’s not dedicated to testing:
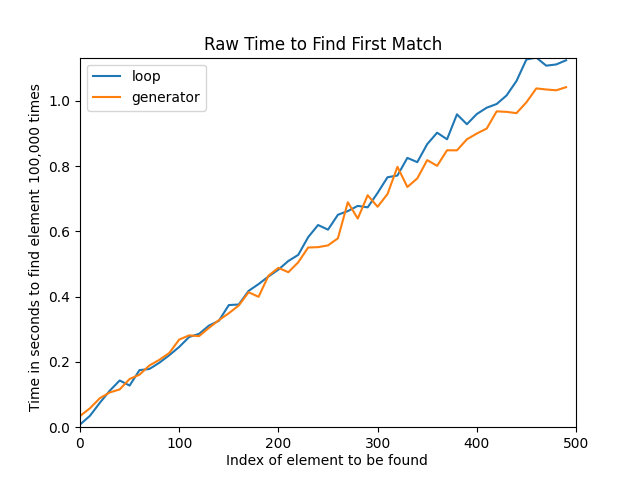
If the computer needs to do something, then it’ll pause the Python process without hesitation, and this can inflate certain results. If you repeat the test various times, then the spikes will appear in random locations.
To smooth out the lines, increase the value of TIMEIT_TIMES.
With those results, you can tentatively say that generators are faster than for loops, even though generators can be significantly slower when the item to find is in the first hundred elements of the iterable. When you’re dealing with small lists, the overall difference in terms of raw milliseconds lost isn’t much. Yet for large iterables where a 5 percent gain can mean minutes, it’s something to bear in mind:
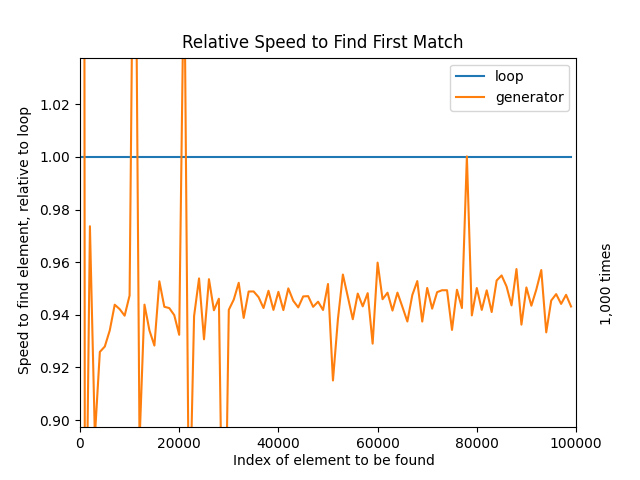
As you can see by this last chart, for very large iterables, the increase in performance stabilizes at around 6 percent. Also, ignore the spikes—to test this large iterable, the TIMEIT_TIMES were decreased substantially.
Making a Reusable Python Function to Find the First Match
Say that the iterables you expect to use are going to be on the large side, and you’re interested in squeezing out every bit of performance out of your code. For that reason, you’ll use generators instead of a for loop. You’ll also be dealing with a variety of different iterables with a variety of items and want flexibility in the way you match, so you’ll design your function to be able to accomplish various goals:
- Returning the first truthy value
- Returning the first match
- Returning the first truthy result of values being passed through a key function
- Returning the first match of values being passed through a key function
- Returning a default value if there’s no match
While there are many ways to implement this, here’s a way to do it with pattern matching:
def get_first(iterable, value=None, key=None, default=None):
match value is None, callable(key):
case (True, True):
gen = (elem for elem in iterable if key(elem))
case (False, True):
gen = (elem for elem in iterable if key(elem) == value)
case (True, False):
gen = (elem for elem in iterable if elem)
case (False, False):
gen = (elem for elem in iterable if elem == value)
return next(gen, default)
You can call the function with up to four arguments, and it’ll behave differently depending on the combination of arguments that you pass into it.
The function’s behavior mainly depends on the value and key arguments. That’s why the match statement checks if value is None and uses the callable() function to learn whether key is a function.
For example, if both the match conditions are True, then it means that you’ve passed in a key but no value. This means that you want each item in the iterable to be passed through the key function, and the return value should be the first truthy result.
As another example, if both match conditions are False, that means that you’ve passed in a value but not a key. Passing a value and no key means that you want the first element in the iterable that’s a direct match with the value provided.
Once match is over, you have your generator. All that’s left to do is to call next() with the generator and the default argument for the first match.
With this function, you can search for matches in four different ways:
>>> countries = [
... {"country": "Austria", "population": 8_840_521},
... {"country": "Canada", "population": 37_057_765},
... {"country": "Cuba", "population": 11_338_138},
... {"country": "Dominican Republic", "population": 10_627_165},
... {"country": "Germany", "population": 82_905_782},
... {"country": "Norway", "population": 5_311_916},
... {"country": "Philippines", "population": 106_651_922},
... {"country": "Poland", "population": 37_974_750},
... {"country": "Scotland", "population": 5_424_800},
... {"country": "United States", "population": 326_687_501},
... ]
>>> # Get first truthy item
>>> get_first(countries)
{'country': 'Austria', 'population': 8840521}
>>> # Get first item matching the value argument
>>> get_first(countries, value={"country": "Germany", "population": 82_905_782})
{'country': 'Germany', 'population': 82905782}
>>> # Get first result of key(item) that equals the value argument
>>> get_first(
... countries, value=5_311_916, key=lambda country: country["population"]
... )
{'country': 'Norway', 'population': 5311916}
>>> # Get first truthy result of key(item)
>>> get_first(
... countries, key=lambda country: country["population"] > 100_000_000
... )
{'country': 'Philippines', 'population': 106651922}
With this function, you have lots of flexibility in how to match. For instance, you could deal with only values, or only key functions, or both!
In the first package mentioned earlier, the function signature is slightly different. It doesn’t have a value parameter. You can still accomplish the same effect as above by relying on the key parameter:
>>> from first import first
>>> first(
... countries,
... key=lambda item: item == {"country": "Cuba", "population": 11_338_138}
... )
{'country': 'Cuba', 'population': 11338138}
In the downloadable materials, you can also find an alternative implementation of get_first() that mirrors the first package’s signature:
Sample Code: Click here to download the free source code that you’ll use to find the first match in a Python list or iterable.
Regardless of which implementation you ultimately use, you now have a performant, reusable function that can get the first item you need.
Conclusion
In this tutorial, you’ve learned how to find the first element in a list or any iterable in a variety of ways. You learned that the fastest and most basic way to match is by using the in operator, but you’ve seen that it’s limited for anything more complex. So you’ve examined the humble for loop, which will be the most readable and straightforward way. However, you’ve also looked at generators for that extra bit of performance and swagger.
Finally, you’ve looked at one possible implementation of a function that gets the first item from an iterable, whether that be the first truthy value or a value transformed by a function that matches on certain criteria.






