
Are you a C++ developer comparing Python vs C++? Are you looking at Python and wondering what all the fuss is about? Do you wonder how Python compares to the concepts you already know? Or perhaps you have a bet on who would win if you locked C++ and Python in a cage and let them battle it out? Then this article is for you!
In this article, you’ll learn about:
- Differences and similarities when you’re comparing Python vs C++
- Times when Python might be a better choice for a problem and vice versa
- Resources to turn to as you have questions while learning Python
This article is aimed at C++ developers who are learning Python. It assumes a basic knowledge of both languages and will use concepts from Python 3.6 and up, as well as C++11 or later.
Let’s dive into looking at Python vs C++!
Free Download: Get a sample chapter from Python Tricks: The Book that shows you Python’s best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
Comparing Languages: Python vs C++
Frequently, you’ll find articles that extoll the virtues of one programming language over another. Quite often, they devolve into efforts to promote one language by degrading the other. This isn’t that type of article.
When you’re comparing Python vs C++, remember that they’re both tools, and they both have uses for different problems. Think about comparing a hammer and a screwdriver. You could use a screwdriver to drive in nails, and you could use a hammer to force in screws, but neither experience will be all that effective.
Using the right tool for the job is important. In this article, you’ll learn about the features of Python and C++ that make each of them the right choice for certain types of problems. So, don’t view the “vs” in Python vs C++ as meaning “against.” Rather, think of it as a comparison.
Compilation vs Virtual Machine
Let’s start with the biggest difference when you’re comparing Python vs C++. In C++, you use a compiler that converts your source code into machine code and produces an executable. The executable is a separate file that can then be run as a stand-alone program:

This process outputs actual machine instructions for the specific processor and operating system it’s built for. In this drawing, it’s a Windows program. This means you’d have to recompile your program separately for Windows, Mac, and Linux:
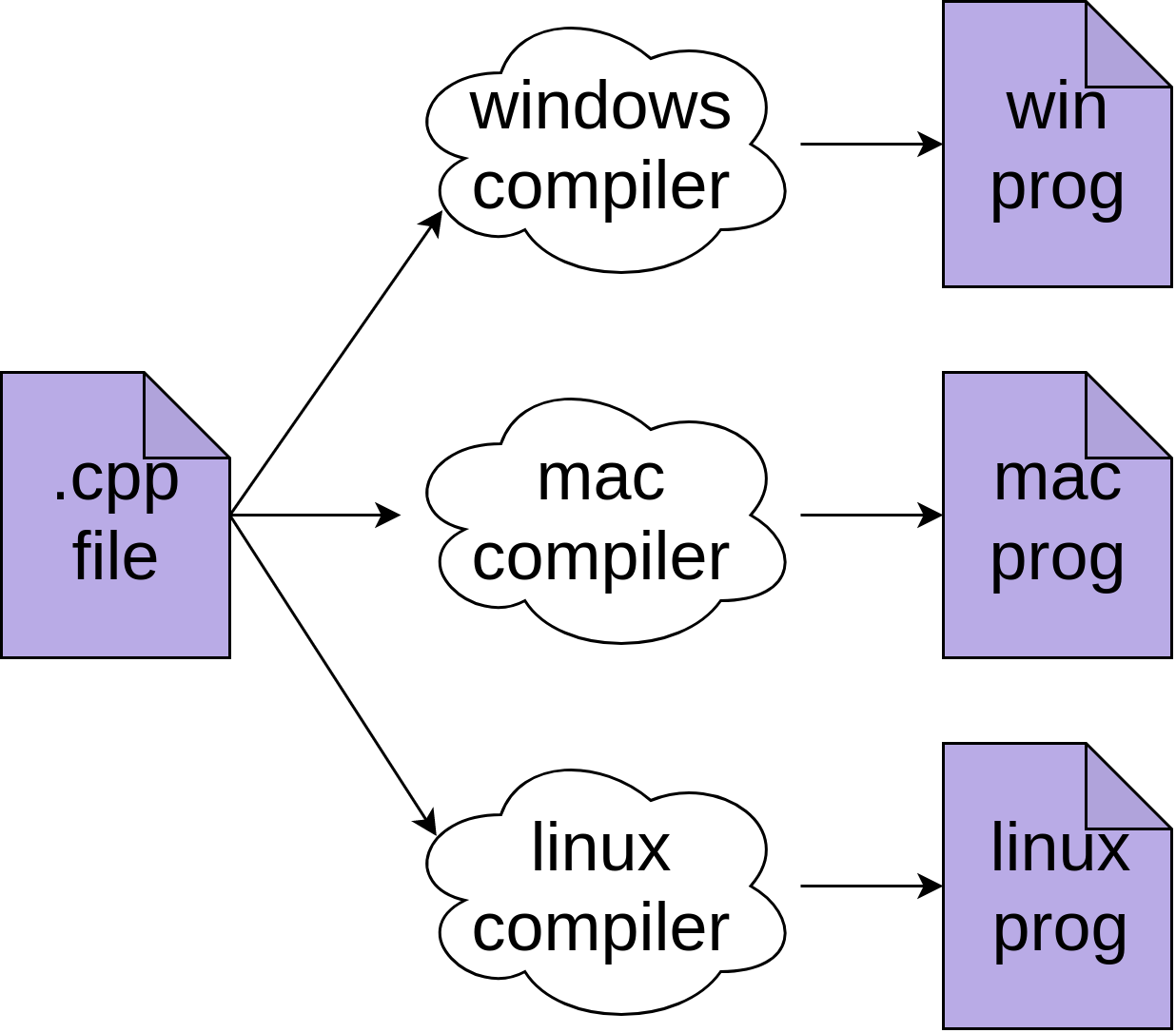
You’ll likely need to modify your C++ code to run on those different systems as well.
Python, on the other hand, uses a different process. Now, remember that you’ll be looking at CPython which is the standard implementation for the language. Unless you’re doing something special, this is the Python you’re running.
Python runs each time you execute your program. It compiles your source just like the C++ compiler. The difference is that Python compiles to bytecode instead of native machine code. Bytecode is the native instruction code for the Python virtual machine. To speed up subsequent runs of your program, Python stores the bytecode in .pyc files:

If you’re using Python 2, then you’ll find these files next to the .py files. For Python 3, you’ll find them in a __pycache__ directory.
The generated bytecode doesn’t run natively on your processor. Instead, it’s run by the Python virtual machine. This is similar to the Java virtual machine or the .NET Common Runtime Environment. The initial run of your code will result in a compilation step. Then, the bytecode will be interpreted to run on your specific hardware:

As long as the program hasn’t been changed, each subsequent run will skip the compilation step and use the previously compiled bytecode to interpret:

Interpreting code is going to be slower than running native code directly on the hardware. So why does Python work that way? Well, interpreting the code in a virtual machine means that only the virtual machine needs to be compiled for a specific operating system on a specific processor. All of the Python code it runs will run on any machine that has Python.
Note: CPython is written in C, so it can run on most systems that have a C compiler.
Another feature of this cross-platform support is that Python’s extensive standard library is written to work on all operating systems.
Using pathlib, for example, will manage path separators for you whether you’re on Windows, Mac, or Linux. The developers of those libraries spent a lot of time making it portable so you don’t need to worry about it in your Python program!
Before you move on, let’s start keeping track of a Python vs C++ comparison chart. As you cover new comparisons, they’ll be added in italics:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x |
Now that you’ve seen the differences in run time when you’re comparing Python vs C++, let’s dig into the specifics of the languages’ syntax.
Syntax Differences
Python and C++ share many syntactical similarities, but there are a few areas worth discussing:
- Whitespace
- Boolean expressions
- Variables and pointers
- Comprehensions
Let’s start with the most contentious one first: whitespace.
Whitespace
The first thing most developers notice when comparing Python vs C++ is the “whitespace issue.” Python uses leading whitespace to mark scope. This means that the body of an if block or other similar structure is indicated by the level of indentation. C++ uses curly braces ({}) to indicate the same idea.
While the Python lexer will accept any whitespace as long as you’re consistent, PEP8 (the official style guide for Python) specifies 4 spaces for each level of indentation. Most editors can be configured to do this automatically.
There has been an enormous amount of writing, shouting, and ranting about Python’s whitespace rules already, so let’s just jump past that issue and on to other matters.
Instead of relying on a lexical marker like ; to end each statement, Python uses the end of the line. If you need to extend a statement over a single line, then you can use the backslash (\) to indicate that. (Note that if you’re inside a set of parentheses, then the continuation character is not needed.)
There are people who are unhappy on both sides of the whitespace issue. Some Python developers love that you don’t have to type out braces and semicolons. Some C++ developers hate the reliance on formatting. Learning to be comfortable with both is your best bet.
Now that you’ve looked at the whitespace issue, let’s move on to one that’s a bit less contentious: Boolean expressions.
Boolean Expressions
The way you’ll use Boolean expressions changes slightly in Python vs C++. In C++, you can use numeric values to indicate true or false, in addition to the built-in values. Anything that evaluates to 0 is considered false, while every other numeric value is true.
Python has a similar concept but extends it to include other cases. The basics are quite similar. The Python documentation states that the following items evaluate to False:
- Constants defined as false:
NoneFalse
- Zeros of any numeric type:
00.00jDecimal(0)Fraction(0, 1)
- Empty sequences and collections:
''()[]{}set()range(0)
All other items are True. This means that an empty list [] is False, while a list containing only zero [0] is still True.
Most objects will evaluate to True, unless the object has __bool__() which returns False or __len__() which returns 0. This allows you to extend your custom classes to act as Boolean expressions.
Python has a few slight changes from C++ in the Boolean operators as well. For starters, if and while statements do not require the surrounding parentheses as they do in C++. Parentheses can aid in readability, however, so use your best judgment.
Most C++ Boolean operators have similar operators in Python:
| C++ Operator | Python Operator |
|---|---|
&& |
and |
|| |
or |
! |
not |
& |
& |
| |
| |
Most of the operators are similar to C++, but if you want to brush up you can read Operators and Expressions in Python.
Variables and Pointers
When you first start using Python after writing in C++, you might not give variables much thought. They seem to generally work as they do in C++. However, they’re not the same. Whereas in C++ you use variables to reference values, in Python you use names.
Note: For this section, where you’re looking at variables and names in Python vs C++, you’ll use variables for C++ and names for Python. Elsewhere, they will both be called variables.
First, let’s back up a bit and take a broader look at Python’s object model.
In Python, everything is an object. Numbers are held in objects. Modules are held in objects. Both the object of a class and the class itself are objects. Functions are also objects:
>>> a_list_object = list()
>>> a_list_object
[]
>>> a_class_object = list
>>> a_class_object
<class 'list'>
>>> def sayHi(name):
... print(f'Hello, {name}')
...
>>> a_function_object = sayHi
>>> a_function_object
<function sayHi at 0x7faa326ac048>
Calling list() creates a new list object, which you assign to a_list_object. Using the name of the class list by itself places a label on the class object. You can place a new label on a function as well. This is a powerful tool and, like all powerful tools, it can be dangerous. (I’m looking at you, Mr. Chainsaw.)
Note: The code above is shown running in a REPL, which stands for “Read, Eval, Print Loop.” This interactive environment is used frequently to try out ideas in Python and other interpreted languages.
If you type python at a command prompt, then it will bring up a REPL where you can start typing in code and trying things out for yourself!
Moving back to the Python vs C++ discussion, note that this is behavior is different from what you’ll see in C++. Unlike Python, C++ has variables that are assigned to a memory location, and you must indicate how much memory that variable will use:
int an_int;
float a_big_array_of_floats[REALLY_BIG_NUMBER];
In Python, all objects are created in memory, and you apply labels to them. The labels themselves don’t have types, and they can be put on any type of object:
>>> my_flexible_name = 1
>>> my_flexible_name
1
>>> my_flexible_name = 'This is a string'
>>> my_flexible_name
'This is a string'
>>> my_flexible_name = [3, 'more info', 3.26]
>>> my_flexible_name
[3, 'more info', 3.26]
>>> my_flexible_name = print
>>> my_flexible_name
<built-in function print>
You can assign my_flexible_name to any type of object, and Python will just roll with it.
When you’re comparing Python vs C++, the difference in variables vs names can be a bit confusing, but it comes with some excellent benefits. One is that in Python you don’t have pointers, and you never need to think about heap vs stack issues. You’ll dive into memory management a bit later in this article.
Comprehensions
Python has a language feature called list comprehensions. While it’s possible to emulate list comprehensions in C++, it’s fairly tricky. In Python, they’re a basic tool that’s taught to beginning programmers.
One way of thinking about list comprehensions is that they’re like a super-charged initializer for lists, dicts, or sets. Given one iterable object, you can create a list, and filter or modify the original as you do so:
>>> [x**2 for x in range(5)]
[0, 1, 4, 9, 16]
This script starts with the iterable range(5) and creates a list that contains the square for each item in the iterable.
It’s possible to add conditions to the values in the first iterable:
>>> odd_squares = [x**2 for x in range(5) if x % 2]
>>> odd_squares
[1, 9]
The if x % 2 at the end of this comprehension limits the numbers used from range(5) to only the odd ones.
At this point you might be having two thoughts:
- That’s a powerful syntax trick that will simplify some parts of my code.
- You can do the same thing in C++.
While it’s true that you can create a vector of the squares of the odd numbers in C++, doing so usually means a little more code:
std::vector<int> odd_squares;
for (int ii = 0; ii < 10; ++ii) {
if (ii % 2) {
odd_squares.push_back(ii*ii);
}
}
For developers coming from C-style languages, list comprehensions are one of the first noticeable ways they can write more Pythonic code. Many developers start writing Python with C++ structure:
odd_squares = []
for ii in range(5):
if (ii % 2):
odd_squares.append(ii)
This is perfectly valid Python. It will likely run more slowly, however, and it’s not as clear and concise as the list comprehension. Learning to use list comprehensions will not only speed up your code, but it will also make your code more Pythonic and easier to read!
Note: When you’re reading about Python, you’ll frequently see the word Pythonic used to describe something. This is just a term the community uses to describe code that is clean, elegant and looks like it was written by a Python Jedi.
Python’s std::algorithms
C++ has a rich set of algorithms built into the standard library. Python has a similar set of built-in functions that cover the same ground.
The first and most powerful of these is the in operator, which provides a quite readable test to see if an item is included in a list, set, or dictionary:
>>> x = [1, 3, 6, 193]
>>> 6 in x
True
>>> 7 in x
False
>>> y = { 'Jim' : 'gray', 'Zoe' : 'blond', 'David' : 'brown' }
>>> 'Jim' in y
True
>>> 'Fred' in y
False
>>> 'gray' in y
False
Note that the in operator, when used on dictionaries, only tests for keys, not values. This is shown by the final test, 'gray' in y.
in can be combined with not for quite readable syntax:
if name not in y:
print(f"{name} not found")
Next up in your parade of Python built-in operators is any(). This is a boolean function that returns True if any element of the given iterable evaluates to True. This can seem a little silly until you remember your list comprehensions! Combining these two can produce powerful, clear syntax for many situations:
>>> my_big_list = [10, 23, 875]
>>> my_small_list = [1, 2, 8]
>>> any([x < 3 for x in my_big_list])
False
>>> any([x < 3 for x in my_small_list])
True
Finally, you have all(), which is similar to any(). This returns True only if—you guessed it—all of the elements in the iterable are True. Again, combining this with list comprehensions produces a powerful language feature:
>>> list_a = [1, 2, 9]
>>> list_b = [1, 3, 9]
>>> all([x % 2 for x in list_a])
False
>>> all([x % 2 for x in list_b])
True
any() and all() can cover much of the same ground where C++ developers would look to std::find or std::find_if.
Note: In the any() and all() examples above, you can remove the brackets ([]) without any loss of functionality. (for example: all(x % 2 for x in list_a)) This makes use of generator expressions which, while quite handy, are beyond the scope of this article.
Before moving on to variable typing, let’s update your Python vs C++ comparison chart:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x | |
| Single-Type Variables | x | |
| Multiple-Type Variables | x | |
| Comprehensions | x | |
| Rich Set of Built-In Algorithms | x | x |
Okay, now you’re ready to look at variable and parameter typing. Let’s go!
Static vs Dynamic Typing
Another large topic when you’re comparing Python vs C++ is the use of data types. C++ is a statically typed language, while Python is dynamically typed. Let’s explore what that means.
Static Typing
C++ is statically typed, which means that each variable you use in your code must have a specific data type like int, char, float, and so forth. You can only assign values of the correct type to a variable, unless you jump through some hoops.
This has some advantages for both the developer and the compiler. The developer gains the advantage of knowing what the type of a particular variable is ahead of time, and therefore which operations are allowed. The compiler can use the type information to optimize the code, making it smaller, faster, or both.
This advance knowledge comes at a cost, however. The parameters passed into a function must match the type expected by the function, which can reduce the flexibility and potential usefulness of the code.
Duck Typing
Dynamic typing is frequently referred to as duck typing. It’s an odd name, and you’ll read more about that in just a minute! But first, let’s start with an example. This function takes a file object and reads the first ten lines:
def read_ten(file_like_object):
for line_number in range(10):
x = file_like_object.readline()
print(f"{line_number} = {x.strip()}")
To use this function, you’ll create a file object and pass it in:
with open("types.py") as f:
read_ten(f)
This shows how the basic design of the function works. While this function was described as “reading the first ten lines from a file object,” there is nothing in Python that requires that file_like_object be a file. As long as the object passed in supports .readline(), the object can be of any type:
class Duck():
def readline(self):
return "quack"
my_duck = Duck()
read_ten(my_duck)
Calling read_ten() with a Duck object produces:
0 = quack
1 = quack
2 = quack
3 = quack
4 = quack
5 = quack
6 = quack
7 = quack
8 = quack
9 = quack
This is the essence of duck typing. The saying goes, “If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck.”
In other words, if the object has the needed methods, then it’s acceptable to pass it in, regardless of the object’s type. Duck or dynamic typing gives you an enormous amount of flexibility, as it allows any type to be used where it meets the required interfaces.
However, there is a problem here. What happens if you pass in an object that doesn’t meet the required interface? For example, what if you pass in a number to read_ten(), like this: read_ten(3)?
This results in an exception being thrown. Unless you catch the exception, your program will blow up with a traceback:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "duck_test.py", line 4, in read_ten
x = file_like_object.readline()
AttributeError: 'int' object has no attribute 'readline'
Dynamic typing can be quite a powerful tool, but as you can see, you must use caution when employing it.
Note: Python and C++ are both considered strongly typed languages. Although C++ has a stronger type system, the details of this are generally not significant to someone learning Python.
Let’s move on to a feature that benefits from Python’s dynamic typing: templates.
Templates
Python doesn’t have templates like C++, but it generally doesn’t need them. In Python, everything is a subclass of a single base type. This is what allows you to create duck typing functions like the ones above.
The templating system in C++ allows you to create functions or algorithms that operate on multiple different types. This is quite powerful and can save you significant time and effort. However, it can also be a source of confusion and frustration, as compiler errors in templates can leave you baffled.
Being able to use duck typing instead of templates makes some things much easier. But this, too, can cause hard-to-detect issues. As in all complex decisions, there are trade-offs when you’re comparing Python vs C++.
Type Checking
There’s been a lot of interest and discussion in the Python community lately about static type checking in Python. Projects like mypy have raised the possibility of adding pre-runtime type checking to specific spots in the language. This can be quite useful in managing interfaces between portions of large packages or specific APIs.
It helps to address one of the downsides of duck typing. For developers using a function, it helps if they can fully understand what each parameter needs to be. This can be useful on large project teams where many developers need to communicate through APIs.
Once again, let’s take a look at your Python vs C++ comparison chart:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x | |
| Single-Type Variables | x | |
| Multiple-Type Variables | x | |
| Comprehensions | x | |
| Rich Set of Built-In Algorithms | x | x |
| Static Typing | x | |
| Dynamic Typing | x |
Now you’re ready to move on to differences in object-oriented programming.
Object-Oriented Programming
Like C++, Python supports an object-oriented programming model. Many of the same concepts you learned in C++ carry over into Python. You’ll still need to make decisions about inheritance, composition, and multiple inheritance.
Similarities
Inheritance between classes works similarly in Python vs C++. A new class can inherit methods and attributes from one or more base classes, just like you’ve seen in C++. Some of the details are a bit different, however.
Base classes in Python do not have their constructor called automatically like they do in C++. This can be confusing when you’re switching languages.
Multiple inheritance also works in Python, and it has just as many quirks and strange rules as it does in C++.
Similarly, you can also use composition to build classes, where you have objects of one type hold other types. Considering everything is an object in Python, this means that classes can hold anything else in the language.
Differences
There are some differences, however, when you’re comparing Python vs C++. The first two are related.
The first difference is that Python has no concept of access modifiers for classes. Everything in a class object is public. The Python community has developed a convention that any member of a class starting with a single underscore is treated as private. This is in no way enforced by the language, but it seems to work out pretty well.
The fact that every class member and method is public in Python leads to the second difference: Python has far weaker encapsulation support than C++.
As mentioned, the single underscore convention makes this far less of an issue in practical codebases than it is in a theoretical sense. In general, any user that breaks this rule and depends on the internal workings of a class is asking for trouble.
Operator Overloads vs Dunder Methods
In C++, you can add operator overloads. These allow you to define the behavior of specific syntactical operators (like ==) for certain data types. Usually, this is used to add more natural usage of your classes. For the == operator, you can define exactly what it means for two objects of a class to be equal.
One difference that takes some developers a long time to grasp is how to work around the lack of operator overloads in Python. It’s great that Python’s objects all work in any of the standard containers, but what if you want the == operator to do a deep comparison between two objects of your new class? In C++, you would create an operator==() in your class and do the comparison.
Python has a similar structure that’s used quite consistently across the language: dunder methods. Dunder methods get their name because they all start and end with a double underscore, or “d-under.”
Many of the built-in functions that operate on objects in Python are handled by calls to that object’s dunder methods. For your example above, you can add __eq__() to your class to do whatever fancy comparison you like:
class MyFancyComparisonClass():
def __eq__(self, other):
return True
This produces a class that compares the same way as any other instance of its class. Not particularly useful, but it demonstrates the point.
There are a large number of dunder methods used in Python, and the built-in functions make use of them extensively. For example, adding __lt__() will allow Python to compare the relative order of two of your objects. This means that not only will the < operator now work, but that >, <=, and >= will also work as well.
Even better, if you have several objects of your new class in a list, then you can use sorted() on the list and they’ll be sorted using __lt__().
Once again, let’s take a look at your Python vs C++ comparison chart:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x | |
| Single-Type Variables | x | |
| Multiple-Type Variables | x | |
| Comprehensions | x | |
| Rich Set of Built-In Algorithms | x | x |
| Static Typing | x | |
| Dynamic Typing | x | |
| Strict Encapsulation | x |
Now that you’ve seen object-oriented coding across both languages, let’s look at how Python and C++ manage those objects in memory.
Memory Management
One of the biggest differences, when you’re comparing Python vs C++, is how they handle memory. As you saw in the section about variables in C++ and Python’s names, Python does not have pointers, nor does it easily let you manipulate memory directly. While there are times when you want to have that level of control, most of the time it’s not necessary.
Giving up direct control of memory locations brings a few benefits. You don’t need to worry about memory ownership, or making sure that memory is freed once (and only once) after it’s been allocated. You also never have to worry about whether or not an object was allocated on the stack or the heap, which tends to trip up beginning C++ developers.
Python manages all of these issues for you. To do this everything in Python is a derived class from Python’s object. This allows the Python interpreter to implement reference counting as a means of keeping track of which objects are still in use and which can be freed.
This convenience comes at a price, of course. To free allocated memory objects for you, Python will occasionally need to run what is called a garbage collector, which finds unused memory objects and frees them.
Note: CPython has a complex memory management scheme, which means that freeing memory doesn’t necessarily mean the memory gets returned to the operating system.
Python uses two tools to free memory:
- The reference counting collector
- The generational collector
Let’s look at each of these individually.
Reference Counting Collector
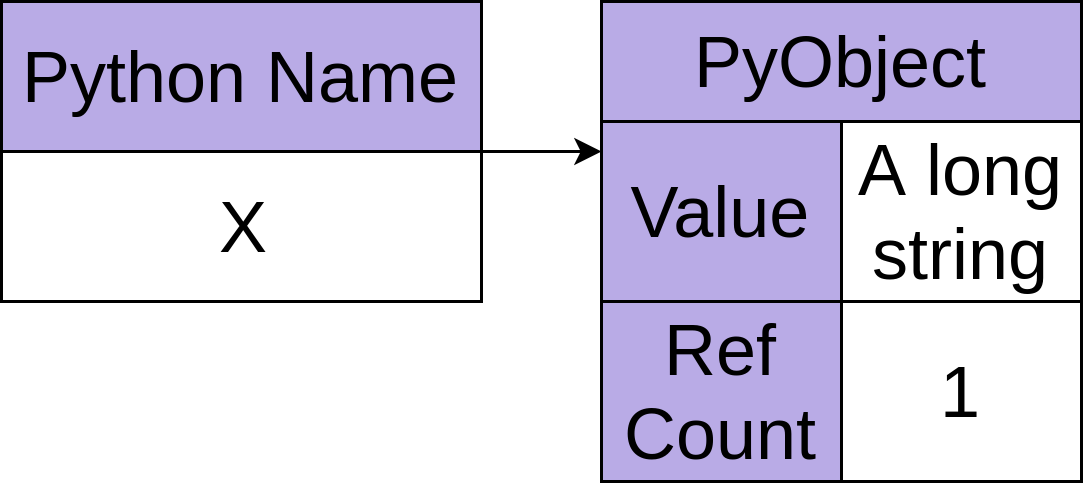
The reference counting collector is fundamental to the standard Python interpreter and is always running. It works by keeping track of how many times a given block of memory (which is always a Python object) has a name attached to it while your program is running. Many rules describe when the reference count is incremented or decremented, but an example of one case might clarify:
1>>> x = 'A long string'
2>>> y = x
3>>> del x
4>>> del y
In the above example, line 1 creates a new object containing the string "A long string". It then places the name x on this object, increasing the object’s reference count to 1:
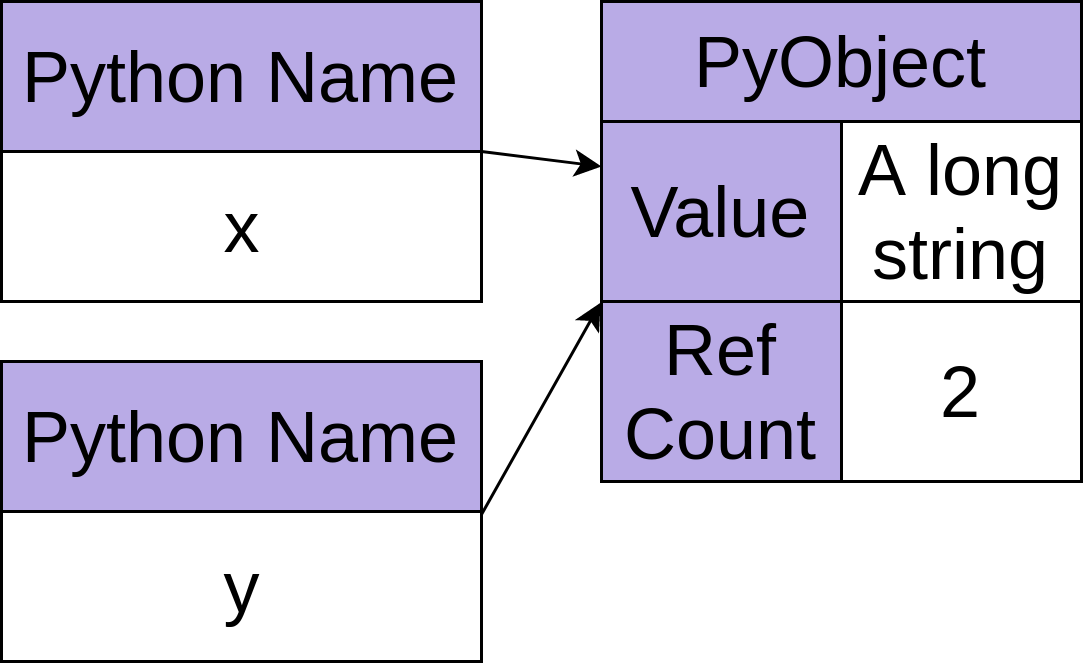
On line 2 it assigns y to name the same object, which will increase the reference count to 2:
When you call del with x in line 3, you’re removing one of the references to the object, dropping the count back to 1:

Finally, when you remove y, the final reference to the object, its reference count drops to zero and it can be freed by the reference counting garbage collector. It may or may not be freed immediately at this point, but generally, that shouldn’t matter to the developer:

While this will take care of finding and freeing many of the objects that need to be freed, there are a few situations it will not catch. For that, you need the generational garbage collector.
Generational Garbage Collector
One of the big holes in the reference counting scheme is that your program can build a cycle of references, where object A has a reference to object B, which has a reference back to object A. It’s entirely possible to hit this situation and have nothing in your code referring to either object. In this case, neither of the objects will ever hit a reference count of 0.
The generational garbage collector involves a complex algorithm that is beyond the scope of this article, but it will find some of these orphaned reference cycles and free them for you. It runs on an occasional basis controlled by settings described in the documentation. One of these parameters is to disable this garbage collector entirely.
When You Don’t Want Garbage Collection
When you’re comparing Python vs C++, as when you’re comparing any two tools, each advantage comes with a trade-off. Python doesn’t require explicit memory management, but occasionally it will spend a longer amount of time than expected on garbage collection. The inverse is true for C++: your program will have consistent response times, but you’ll need to expend more effort in managing memory.
In many programs the occasional garbage collection hit is unimportant. If you’re writing a script that only runs for 10 seconds, then you’re unlikely to notice the difference. Some situations, however, require consistent response times. Real-time systems are a great example, where responding to a piece of hardware in a fixed amount of time can be essential to the proper operation of your system.
Systems with hard real-time requirements are some of the systems for which Python is a poor language choice. Having a tightly controlled system where you’re certain of the timing is a good use of C++. These are the types of issues to consider when you’re deciding on the language for a project.
Time to update your Python vs C++ chart:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x | |
| Single-Type Variables | x | |
| Multiple-Type Variables | x | |
| Comprehensions | x | |
| Rich Set of Built-In Algorithms | x | x |
| Static Typing | x | |
| Dynamic Typing | x | |
| Strict Encapsulation | x | |
| Direct Memory Control | x | |
| Garbage Collection | x |
Threading, Multiprocessing, and Async IO
The concurrency models in C++ and Python are similar, but they have different results and benefits. Both languages have support for threading, multiprocessing, and Async IO operations. Let’s look at each of these.
Threading
While both C++ and Python have threading built into the language, the results can be markedly different, depending on the problem you’re solving. Frequently, threading is used to address performance problems. In C++, threading can provide a general speed-up for both computationally bound and I/O bound problems, as threads can take full advantage of the cores on a multiprocessor system.
Python, on the other hand, has made a design trade-off to use the Global Interpreter Lock, or the GIL, to simplify its threading implementation. There are many benefits to the GIL, but the drawback is that only one thread will be running at a single time, even if there are multiple cores.
If your problem is I/O bound, like fetching several web pages at once, then this limitation will not bother you in the least. You’ll appreciate Python’s easier threading model and built-in methods for inter-thread communications. If your problem is CPU-bound, however, then the GIL will restrict your performance to that of a single processor. Fortunately, Python’s multiprocessing library has a similar interface to its threading library.
Multiprocessing
Multiprocessing support in Python is built into the standard library. It has a clean interface that allows you to spin up multiple processes and share information between them. You can create a pool of processes and spread work across them using several techniques.
While Python still uses similar OS primitives to create the new processes, much of the low-level complication is hidden from the developer.
C++ relies on fork() to provide multiprocessing support. While this gives you direct access to all of the controls and issues of spawning multiple processes, it’s also much more complex.
Async IO
While both Python and C++ support Async IO routines, they’re handled differently. In C++, the std::async methods are likely to use threading to achieve the Async IO nature of their operations. In Python, Async IO code will only run on a single thread.
There are trade-offs here as well. Using separate threads allows the C++ Async IO code to perform faster on computationally bound problems. The Python tasks used in its Async IO implementation are more lightweight, so it’s faster to spin up a large number of them to handle I/O bound issues.
Your Python vs C++ comparison chart remains unchanged for this section. Both languages support a full range of concurrency options, with varying trade-offs between speed and convenience.
Miscellaneous Issues
If you’re comparing Python vs C++ and looking at adding Python to your toolbelt, then there are a few other things to consider. While your current editor or IDE will certainly work for Python, you might want to add certain extensions or language packs. It’s also worth giving PyCharm a look, as it’s Python-specific.
Several C++ projects have Python bindings. Things like Qt, WxWidgets, and many messaging APIs having multiple-language bindings.
If you want to embed Python in C++, then you can use the Python/C API.
Finally, there are several methods for using your C++ skills to extend Python and add functionality, or to call your existing C++ libraries from within your Python code. Tools like CTypes, Cython, CFFI, Boost.Python and Swig can help you combine these languages and use each for what it’s best at.
Summary: Python vs C++
You’ve spent some time reading and thinking about the differences between Python vs C++. While Python has easier syntax and fewer sharp edges, it’s not a perfect fit for all problems. You’ve looked at the syntax, memory management, processing, and several other aspects of these two languages.
Let’s take a final look at your Python vs C++ comparison chart:
| Feature | Python | C++ |
|---|---|---|
| Faster Execution | x | |
| Cross-Platform Execution | x | |
| Single-Type Variables | x | |
| Multiple-Type Variables | x | |
| Comprehensions | x | |
| Rich Set of Built-In Algorithms | x | x |
| Static Typing | x | |
| Dynamic Typing | x | |
| Strict Encapsulation | x | |
| Direct Memory Control | x | |
| Garbage Collection | x |
If you’re comparing Python vs C++, then you can see from your chart that this is not a case where one is better than the other. Each of them is a tool that’s well crafted for various use cases. Just like you don’t use a hammer for driving screws, using the right language for the job will make your life easier!
Conclusion
Congrats! You’ve now seen some of the strengths and weaknesses of both Python and C++. You’ve learned some of the features of each language and how they are similar.
You’ve seen that C++ is great when you want:
- Fast execution speed (potentially at the cost of development speed)
- Complete control of memory
Conversely, Python is great when you want:
- Fast development speed (potentially at the cost of execution speed)
- Managed memory
You’re now ready to make a wise language choice when it comes to your next project!







