Python has a few naming conventions that are based on using either a single or double underscore character (_). These conventions allow you to differentiate between public and non-public names in APIs, write subclasses safely, prevent name collisions, and more.
Following these conventions makes your code look more Pythonic and consistent to other developers. This skill is especially helpful when you’re working on collaborative projects.
By the end of this tutorial, you’ll understand that:
- Underscores in Python names indicate intent: a single leading underscore signals a non-public name, a single trailing underscore helps avoid naming conflicts, and a double leading underscore triggers name mangling for class attributes and methods.
- Python doesn’t enforce public or private names with access restrictions. It relies on naming conventions, where public names have no underscores and non-public names start with a single underscore.
- Python’s name mangling automatically renames attributes or methods with double leading underscores by prefixing them with the class name, helping you avoid accidental overrides in subclasses.
- Double leading and trailing underscores—known as dunders—denote special methods or attributes, such as
.__init__(),.__len__(), and__name__, which Python uses to support internal behaviors.
You’ll explore practical examples of these naming conventions, learn when and why to use each one, and understand their effects on code readability, API design, and inheritance.
Get Your Code: Click here to download the free sample code that shows you how to use single and double underscores in Python names.
Take the Quiz: Test your knowledge with our interactive “Single and Double Underscores in Python Names” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Single and Double Underscores in Python NamesIn this quiz, you'll test your understanding of the use of single and double underscores in Python names. This knowledge will help you differentiate between public and non-public names, avoid name clashes, and write code that looks Pythonic and consistent.
Public Interfaces and Naming Conventions in Python
As a Python programmer, you’ll frequently work with public interfaces, known as application programming interfaces (APIs). An API is a type of programming interface that offers a service to other parts of a program or other programs.
For example, the Python standard library has many modules and packages that provide certain services. To use these modules and packages, you need to access their public components, such as classes, functions, variables, constants, and modules. All these objects are part of the module or package’s public interface. They’re available for you to use directly in your code.
However, many of these packages and modules define objects that aren’t intended for direct access. These objects are meant for internal use within the specific package or module and aren’t part of its public interface.
In the context of object-oriented programming, languages like C++ and Java have the notion of public and private methods and attributes—jointly called members. In these languages, you can use these types of class members as follows:
- Public: You can use them in your own code or client code.
- Private: You can use them only from inside the defining class and its subclasses.
These languages have specific keywords and syntax to define public and private members in their classes. Once you declare a member as private, you can’t use it outside the class because the language restricts access. So, private members aren’t part of the class’s public interface, and there’s no way to access them.
In contrast, Python doesn’t have the notion of public and private members. It has neither dedicated keywords nor syntax for defining them. Therefore, you can always access the members of a Python class.
If Python doesn’t have a specific syntax to define when an object is part of a public interface, then how do you tell your users that they can or can’t use a given class, method, function, variable, constant, or even module in their code?
To approach this question, the Python community has a well-established naming convention:
If a name starts with a letter in uppercase or lowercase, then you should consider that name public and, therefore, part of the code’s API. In contrast, if a name starts with an underscore character (_), then you should consider that name non-public, meaning it’s not a part of the public API.
You should observe these naming conventions to explicitly indicate whether other developers should directly use your variables, constants, functions, methods, and modules in external code.
Note: This naming convention doesn’t restrict access to objects. It only signals to other developers how the code is intended to be used. Because of this, Python programmers avoid the terms public and private. Instead, they distinguish between public and non-public (internal) names.
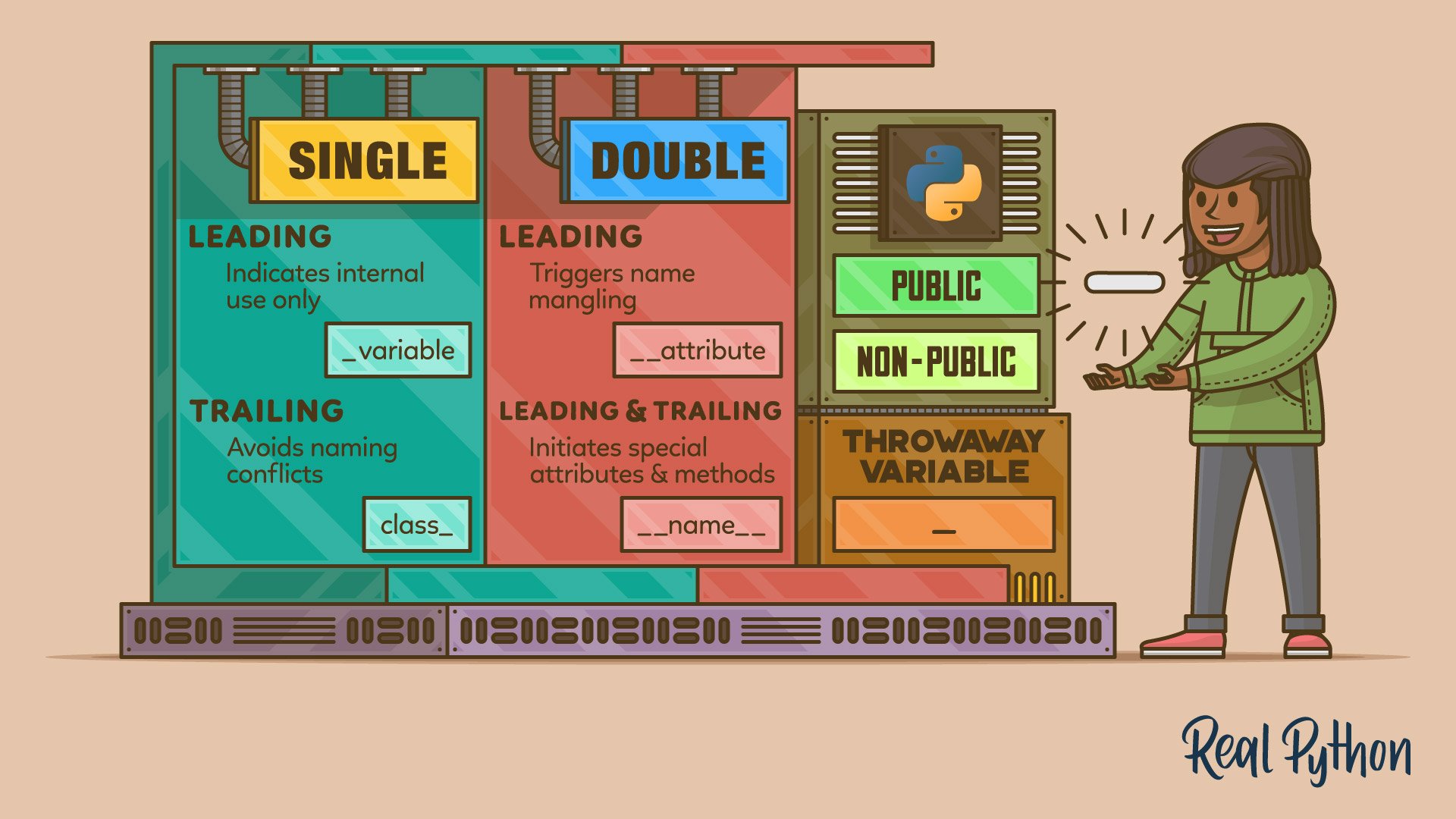
The Python community uses the underscore character (_) as part of other naming conventions. Here’s a summary of what PEP 8 says about using this character in names:
| Convention | Example | Meaning |
|---|---|---|
| Single leading underscore | _variable |
Indicates that the name is meant for internal use only |
| Single trailing underscore | class_ |
Avoids naming conflicts with Python keywords and built-in names |
| Double leading underscore | __attribute |
Triggers name mangling in the context of Python classes |
| Double leading and trailing underscore | __name__ |
Indicates special attributes and methods that Python provides |
| Single underscore | _ |
Indicates a temporary or throwaway variable |
Note that only two of these naming conventions enforce specific Python behaviors. Using double leading underscores triggers name mangling in Python classes. You’ll learn more about this behavior in the section on name mangling.
Additionally, those names with double leading and trailing underscores that are listed in the Python data model trigger internal behaviors in specific contexts. You’ll also learn more about this topic in the section on dunder names in Python.
Note: Python also treats a single underscore (_) as a soft keyword within match … case statements. You’ll learn more about this later.
In the following section, you’ll learn more about using a single leading underscore when naming your Python objects.
Single Leading Underscore in Python Names
As you already learned, Python lacks dedicated keywords or syntax for making objects public or private. It only has a widely accepted naming convention that doesn’t enforce the distinction. Therefore, Python refers to its objects as public or non-public without restricting access to them.
Creating Public and Non-Public Names in Python
Public names define the public interface (API) of your code. These are the names that users of your code rely on to access its functionality. These names should be descriptive, intuitive, and, more importantly, stable over time.
Here’s a quick example:
>>> public = "This is a public name."
>>> public
'This is a public name.'
In this scenario, stable means that once a name is part of your code’s public interface, that name should remain the same over a long period. Otherwise, you risk breaking your users’ code, which can happen when you introduce changes in your public APIs.
When designing your code’s public interface, you must carefully select its public names. Not all the objects in your code should be public. If you have an object that client code shouldn’t use and you give that object a public name, then you risk mistaken usage of your code.
In contrast, you create non-public names to support internal functionality. These names are part of the internal implementation of your code rather than of its API. Therefore, your users shouldn’t use non-public names in their code because those names can change over time or even disappear in future versions of your code.
Here’s an example of a non-public name:
>>> _non_public = "This is a non-public name."
>>> _non_public
'This is a non-public name.'
Python developers let you know when an object is non-public by using a single leading underscore in its name.
In general, you should use a single leading underscore only when you need to indicate that a variable, class, method, function, or module is intended for internal use within the containing module, class, or package. Again, this is just a naming convention. It’s not a strict rule that Python enforces. You can always access non-public names unless they live in an unreachable scope.
Following and respecting this naming convention is a best practice to keep in mind when writing, reading, or using Python code.
In general, objects that you’re likely to change through the evolution of your code should remain non-public. So, when in doubt, give your objects non-public names. If you later decide that a given non-public object should become part of your code’s API, then you can remove the leading underscore. This practice lets you stabilize your API and prevent breaking your users’ code.
If you’re using code from someone else, then finding a leading underscore in an object’s name should be a hint to avoid using it directly in your code.
Using Public vs Non-Public Names in Python
While writing Python code, you can use public and non-public names in different situations. Public names are part of your code’s public interface. So, these names are quite important for the users of your code. You must make sure to select descriptive and easy-to-memorize public names.
In contrast, non-public names are mostly for internal use. They can help you with some of the following tasks:
- Preventing incorrect use of your code: Marking internal parts of your code with non-public names helps guide users toward the correct way to use it.
- Improving code readability: Using non-public names appropriately improves code readability because other people reading your code will immediately know that those names are for internal use only.
- Avoiding name clashes: Using non-public names can help you avoid name collisions between packages, modules, and classes.
You’ll also find some other differences between public and non-public names in Python. Documentation is probably the main one. You should document all your public functions, methods, classes, and objects. In contrast, you don’t have to document non-public ones.
Finally, many Python tools—such as code editors, IDEs, linters, and REPL apps—rely on the leading underscore naming convention to distinguish between public and non-public names. They use this distinction when displaying information about the public interface of your code on-screen.
In the following sections, you’ll learn how and when to use public and non-public names in your Python modules.
Public and Non-Public Names in Modules and Packages
Python modules might be one of those places where you’ll need to decide which names should be public and which should be non-public. At the module level, you can have some of the following objects:
You may need to allow your users to access these objects as part of your module’s API. However, in some cases, you may need to communicate that some of your module-level objects aren’t intended to be part of the API.
Some common examples of module-level non-public objects include the following:
- Internal variables and constants
- Helper functions and classes
In the following sections, you’ll learn about these types of objects. You’ll also learn about non-public modules. Yes, you can even have non-public modules in your packages.
Internal Variables and Constants
Exposing global variables in your modules to external code isn’t a good idea. Even though global variables can come in handy in a few use cases, such as for global settings, utility scripts, and data caching, they have several drawbacks. For example, global variables can:
- Make you lose track of changes to the variable because you can change the variable from anywhere in your code
- Give your code reduced reusability because changes to a global variable can impact the behavior of other parts of your code
- Make your code difficult to test and debug because the behavior and result of your functions will depend on the global variable’s current value
- Affect your code’s reusability because functions that rely on global variables are tightly coupled to those variables
- Cause naming conflicts because you might accidentally reuse a global name in different parts of your code, causing unexpected results
- Break encapsulation because global variables introduce hidden dependencies between different parts of your code
- Make your code hard to refactor because changes in one part of the code can affect other parts
Therefore, in most cases, it’s a good idea to mark your global variables as non-public. Consider the following sample module:
count.py
_count = 0
def increment():
global _count
_count += 1
def decrement():
global _count
_count -= 1
def get_count():
return _count
In this module, you use a module-level or global variable to keep a counter. Your module has public functions to increment and decrement the count. It also has a function to retrieve the count’s state. All of these are part of the module’s public interface, so your users can use them directly in their code.
However, the _count variable itself is non-public because it has a leading underscore in its name. This detail tells the users of your code that they shouldn’t use _count directly in their code. Why?
By avoiding _count, users can prevent invalid states during the counting process. So, to consistently use this module, your users should modify the current count only with the mutator functions increment() and decrement(). If the user needs to access the count, then they should use get_count().
In contrast, doing something like _count = 10 can introduce an invalid state if 10 isn’t the correct expected value for the count.
Note: The above example is for demonstrative purposes only. In Python, there are several better ways to write a counter. Check out Python’s Counter: The Pythonic Way to Count Objects for best practices around this topic.
Another situation where you’d like to make your objects non-public is when you have a constant that’s only relevant to the internal working of its containing module. Consider the following example:
shapes.py
_PI = 3.14
class Circle:
def __init__(self, radius):
self.radius = radius
def calculate_area(self):
return round(_PI * self.radius**2, 2)
In this code, you defined a non-public constant, _PI, using a leading underscore in its name. The leading underscore serves as a polite message to other developers, saying that this constant is intended for internal use only within the shapes module.
In this sample module, the public object is the Circle class, which has no leading underscore in its name.
Helper Functions
Helper functions are another good example of where you may want to use non-public names. The idea behind helper functions is code reuse, and most of the time, they’re intended for internal use only. They shouldn’t be part of a module’s API.
As an example, return to the shapes.py file from the previous section and imagine you need to validate the radius of your Circle class to guarantee that it’s a number greater than zero. In this case, you can use a helper function for the validation. Then, you can reuse the helper function in other shapes:
shapes.py
_PI = 3.14
class Circle:
def __init__(self, radius):
self.radius = _validate(radius)
def calculate_area(self):
return round(_PI * self.radius**2, 2)
class Square:
def __init__(self, side):
self.side = _validate(side)
def calculate_area(self):
return round(self.side**2, 2)
def _validate(value):
if not isinstance(value, int | float) or value <= 0:
raise ValueError("positive number expected")
return value
In this new version of shapes.py, you add a _validate() helper function at the end of the module. The function takes a value as an argument and checks whether it’s a positive number. If that’s not the case, then you get a ValueError exception. Otherwise, you get the same input argument.
Note how you reuse this helper function in the Circle and Square classes. However, you don’t need to make this function part of the module’s API, so you use a leading underscore in its name to signal that it’s a non-public function.
Non-Public Modules
It’s also possible to use a leading underscore in module names. For example, in the CPython source code, plenty of module names start with a leading underscore to signal that the module at hand provides an internal implementation of some piece of code.
While these modules aren’t meant to be part of Python’s public API and aren’t listed in the standard library documentation, you can technically import them if you know their names. However, because they’re considered internal, they may change or disappear without notice between Python releases.
In your own Python projects, you may have modules that provide code for internal use only. In those cases, you can use a leading underscore in their names to tell other developers that they shouldn’t use these modules directly in their code.
Wildcard Imports and Non-Public Names
Sometimes, you’ll find Python libraries that use wildcard imports of the form from module import * to bring all the names defined in a module into your current namespace. The Tkinter library for GUI development is a good example of this practice. These types of imports aren’t particularly common because Python’s style guide, PEP 8, discourages their use:
Wildcard imports (
from <module> import *) should be avoided, as they make it unclear which names are present in the namespace, confusing both readers and many automated tools. (Source)
However, sometimes wildcard imports are useful and quick. To use wildcard imports properly, you should know that they don’t import non-public names. To confirm this Python behavior, open a REPL session in the directory where your shapes.py file lives. Then run the following code:
>>> from shapes import *
>>> dir()
[
'Circle',
'Square',
...
]
In this code snippet, you can see that your wildcard import only imports the Circle and Square classes. The _PI constant and the _validate() helper function aren’t in your current namespace.
Note: Wildcard imports omit names prefixed with a single underscore unless you list them in the __all__ attribute. To learn more about __all__, check out the Python’s __all__: Packages, Modules, and Wildcard Imports tutorial.
Python enforces the above behavior. However, this behavior only applies to wildcard imports. You can still access non-public names using other import statement forms:
>>> from shapes import _PI
>>> _PI
3.14
>>> import shapes
>>> shapes._PI
3.14
Using an import form other than a wildcard import, you can bring any non-public name to your current namespace. In this example, you import the _PI constant from shapes.py even if it’s a non-public object. You can also access _PI by using dot notation on the shapes module. Keep in mind that doing something like this bypasses the intention of the established naming convention regarding non-public names.
Class With Non-Public Members
The distinction between public and non-public names is even more relevant in the context of object-oriented programming. Here’s how PEP 8 defines these terms when referring to the attributes of a class:
Public attributes are those that you expect unrelated clients of your class to use, with your commitment to avoid backwards incompatible changes. Non-public attributes are those that are not intended to be used by third parties; you make no guarantees that non-public attributes won’t change or even be removed. (Source)
Again, public class attributes and methods—also known as members—are part of the class’s public interface, while non-public members aren’t part of it. It’d be best not to use non-public members outside of their defining class. Non-public members are non-public for a reason, so you should respect that.
In most cases, non-public members exist only to support the internal implementation of a given class and may disappear at any time, so your users shouldn’t rely on them.
In the following sections, you’ll explore some use cases of non-public attributes and methods in Python classes.
Non-Public Attributes
You may find several use cases of non-public attributes in your Python classes. These types of attributes can serve many different purposes, including:
-
Promoting encapsulation: You can use non-public attributes to enforce encapsulation by hiding internal implementation details.
-
Implementing caching and memoization: You can use non-public attributes to cache or memoize the results of costly computations.
-
Protecting internal state: You can use non-public attributes to store internal state information that isn’t part of a class’s public interface.
When you’re writing classes, sometimes it’s hard to decide whether an attribute should be public or non-public. This decision will depend on how you want users to use your classes. In most cases, attributes should be non-public to promote the safe use of your classes.
Following this idea, a good approach is to start with all your attributes as non-public and only make them public if real use cases appear.
Note: Accessing and modifying non-public attributes directly violates data encapsulation. This is another reason to avoid using non-public members from outside the defining class.
Programming languages such as Java and C++ encourage you to never have public attributes. Instead, you should provide getter and setter methods and make all the attributes private.
In Python, however, exposing attributes as part of a class’s public interface is common practice. The reason for this is that you can always turn attributes into properties if you ever need to add function-like behavior on top of a given attribute.
To illustrate, say that you need to define a Point class. The class will have two attributes representing its Cartesian coordinates:
point.py
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
In this class, you have two public attributes, .x and .y, which represent the point’s coordinates. You can access and change these attributes using dot notation:
>>> from point import Point
>>> point = Point(12, 5)
>>> # Access the coordinates
>>> point.x
12
>>> point.y
5
>>> # Update a coordinate
>>> point.x = 24
>>> point.x
24
>>> # Assign an invalid data type
>>> point.y = "10"
>>> point.y
'10'
As you can conclude from this short example, you can access and update attributes directly using dot notation. In the final example, you should note that your class doesn’t validate the value that you assign to a coordinate, which may not be the right way to use Point.
To solve the data type inconsistency, you may want to add function-like behavior on top of the .x and .y attributes so that you can implement appropriate validation logic. Plain attributes won’t let you do that. You need a method or a function. So instead of something like point.x, you’ll change the API to something like point.x(), which will break your users’ code.
You can solve this issue without modifying your class’s public interface by turning the attributes into properties:
point.py
class Point:
def __init__(self, x, y):
self.x = x
self.y = y
@property
def x(self):
return self._x
@x.setter
def x(self, value):
self._x = _validate(value)
@property
def y(self):
return self._y
@y.setter
def y(self, value):
self._y = _validate(value)
def _validate(value):
if not isinstance(value, int | float):
raise ValueError("number expected")
return value
A lot is happening in this new version of Point. The first noticeable change is that you’ve stored the coordinates in non-public attributes inside methods named after the attributes. You implement both attributes as properties using the @property decorator to define the getter methods and the @attribute_name.setter decorator to define the setter methods.
In the setter methods, you use the _validate() helper function to make sure that the input values are valid numbers. Note how you store the actual value in the corresponding non-public attribute, which isn’t part of your class’s API. Using the public attributes inside .__init__() makes sure that the validation happens on instantiation as well.
Python’s properties allow you to create attributes with function-like behavior. However, you don’t have to call properties as methods—you can continue accessing them as normal attributes:
>>> from point import Point
>>> point = Point(12, 5)
>>> point.x
12
>>> point.y
5
>>> point.x = 24
>>> point.x
24
>>> point.y = "10"
Traceback (most recent call last):
...
ValueError: number expected
In this code snippet, you use the point instance as you did before. The API didn’t change. However, when you try to assign an invalid value to one of the coordinates, you get a ValueError. This happens because the setter method of a property runs whenever you assign a new value. So, the _validate() function runs every time you try to update the value of .x or .y.
It’s important to note that even though you’ve defined properties to manage the non-public attributes ._x and ._y, you can still access them directly:
>>> point._x
24
>>> point._y
5
Remember that the leading underscore is just a naming convention. Python doesn’t restrict access to these types of attributes. As a Python developer, you should respect the convention and not access non-public attributes from the outside. Why?
In this specific example, assigning a new value to ._x or ._y will bypass the validation, which may trigger wrong behaviors or even break other parts of your code:
>>> point._y = "10"
>>> point.y
'10'
Note how the .y coordinate now contains an invalid value. Instead of a number, it now holds a string. This is a direct consequence of violating the convention and mutating the underlying non-public attribute.
Non-Public Methods
You can also use non-public methods in your Python classes. These types of methods may be essential to the inner workings of your classes. However, they’re not part of the class’s interface. You’ll find many use cases for non-public methods. Here are some of them:
- Helper methods: Non-public methods help you encapsulate repeated logic that supports the public methods. You can also use them to split long or complex methods into several helper methods with a single responsibility each.
- Data validation and integrity: Non-public methods allow you to validate data within a class. You can use them to ensure consistency and maintain data integrity without exposing the validation logic to external code.
- Implementation details: Non-public methods allow you to hide the internal implementation details of a class. You can use them to encapsulate complex algorithms and data transformations.
- Code organization: Non-public methods can help you organize large or complex classes, making your code easier to read, maintain, and extend.
To illustrate one of these use cases, say that you’re working with CSV files that use either commas or tab characters to separate the values. You need to write a class that provides a method to process files that use commas and another method to process files that use tabs.
Here’s a possible implementation of this class:
csv_data.py
import csv
class CSVFileManager:
def __init__(self, file_path):
self.file_path = file_path
def read_csv(self):
return self._read(delimiter=",")
def read_tsv(self):
return self._read(delimiter="\t")
def _read(self, delimiter):
with open(self.file_path, mode="r") as file:
return [row for row in csv.reader(file, delimiter=delimiter)]
This class has two methods as part of its public interface, .read_csv() and .read_tsv(). In the ._read() helper method, you have the base code for both public methods. With this helper method, you avoid having repeated logic in .read_csv() and .read_tsv().
Double Leading Underscore in Classes: Python’s Name Mangling
In the context of Python classes, you’ll find another naming convention related to underscores: using two or more leading underscores in attribute and method names. Unlike a single leading underscore, which doesn’t trigger any Python internal action, double leading underscores launch a behavior that’s known as name mangling.
In the following sections, you’ll learn what name mangling is, how it works, and what it aims to do in Python.
Understanding Name Mangling
When you name an attribute or method with two leading underscores, Python automatically renames it by prefixing its name with the class name and a single leading underscore. This renaming process is called name mangling.
The following example shows how this renaming works:
>>> class SampleClass:
... def __init__(self, attribute):
... self.__attribute = attribute
...
... def __method(self):
... print(self.__attribute)
...
>>> sample_instance = SampleClass("Hello!")
>>> vars(sample_instance)
{'_SampleClass__attribute': 'Hello!'}
In this class, .__attribute and .__method() have two leading underscores in their names. Python mangles those names to ._SampleClass__attribute and ._SampleClass__method(), automatically adding the _SampleClass prefix.
Because of this internal renaming, you can’t access the attribute or method from outside the class using their original names:
>>> sample_instance.__attribute
Traceback (most recent call last):
...
AttributeError: 'SampleClass' object has no attribute '__attribute'
>>> sample_instance.__method()
Traceback (most recent call last):
...
AttributeError: 'SampleClass' object has no attribute '__method'
If you try to access the instance’s .__attribute and .__method() using their original names, then you get an AttributeError exception. That’s because of name mangling, which changes how these attributes appear to the outside world. However, you can still use their original names when referring to them from within the class.
Even though Python mangles names that start with two underscores, it doesn’t completely restrict access to those names. You can always access the mangled name:
>>> sample_instance._SampleClass__attribute
'Hello!'
>>> sample_instance._SampleClass__method()
Hello!
You can still access named-mangled attributes or methods using their mangled names, although this is bad practice, and you should avoid it in your code. If you see a name that uses this convention, then don’t try to force the code to use the name from outside its containing class.
Using Name Mangling in Inheritance
Even though you’ll find many resources out there that claim name mangling is for creating private members, this naming transformation pursues a different goal: preventing name clashes in inheritance. To define non-public members, you should use a single leading underscore, as you’ve done in previous sections.
Name mangling is particularly useful when you want to ensure that a given attribute or method won’t be accidentally overridden in a subclass:
>>> class A:
... def __init__(self):
... self.__attr = 0
...
... def __method(self):
... print("A.__attr = ", self.__attr)
...
>>> class B(A):
... def __init__(self):
... super().__init__()
... self.__attr = 1 # Doesn't override A.__attr
...
... def __method(self): # Doesn't override A.__method()
... print("B.__attr = ", self.__attr)
...
>>> a = A()
>>> b = B()
>>> # Call the mangled methods
>>> a._A__method()
A.__attr = 0
>>> b._B__method()
B.__attr = 1
>>> # Check attributes
>>> a.__dict__
{'_A__attr': 0}
>>> b.__dict__
{'_A__attr': 0, '_B__attr': 1}
>>> # Access the attributes on b
>>> b._A__attr
0
>>> b._B__attr
1
By using two leading underscores in attribute and method names, you can prevent subclasses from overriding them. If your class is intended to be subclassed, and it has attributes that you don’t want subclasses to use, then consider naming them with double leading underscores. Avoid using name mangling to create private or non-public attributes.
Trailing Underscores in Python Names
Another naming convention that you’ll find in Python code is to use a single trailing underscore. This convention comes in handy when you want to use a name that clashes with a Python keyword or a built-in name, like built-in functions and data types. In this situation, adding a trailing underscore will help you avoid the issue.
For example, sometimes when you’re starting to learn Python and you’re diving into using the built-in list data type, you may be tempted to do something like the following:
>>> list = [1, 2, 3, 4]
>>> list
[1, 2, 3, 4]
Even though this code works, it clashes with the list name, which is reserved for a built-in data type. If you continue using the same REPL session, then you’ll be surprised when you get an error like this:
>>> list("Pythonista")
Traceback (most recent call last):
...
TypeError: 'list' object is not callable
What just happened? Why can’t you call the list() constructor? Well, your previous code overrode the built-in name, and now the name list points to a list object rather than to the built-in list class.
You can fix this issue by appending an underscore to the clashing name. Note that for the code below to work, you need to restart your interactive session or use the del statement to remove your custom name from your current namespace:
>>> list_ = [1, 2, 3, 4]
>>> list_
[1, 2, 3, 4]
>>> list("Pythonista")
['P', 'y', 't', 'h', 'o', 'n', 'i', 's', 't', 'a']
In this new version of the example, the name you use doesn’t override the list built-in name. So, the list() constructor works as expected.
Another situation where you’d need to use this trailing underscore naming convention is when you want to use a name that clashes with a keyword. Consider the following toy example:
class Passenger:
def __init__(self, name, class_, seat):
self.name = name
self.class_ = class_
self.seat = seat
# Implementation...
In this code snippet, you use a trailing underscore to define the passenger’s class. If you don’t do it like this, then you’ll get an error because class is a Python keyword, and you can’t use it with a different purpose in your code.
Note: The machine learning library scikit-learn uses a convention where a trailing underscore indicates that an attribute has been estimated or fitted from data. For example, estimated coefficients will be stored in .coef_ instead of .coef.
Even though the trailing underscore trick works, it’s probably best to use a synonym or a multi-word name. In the above example, your code will probably look better if you use something like reserved_class to name the argument and the corresponding attribute.
Dunder Names in Python
Names with double leading and trailing underscores (__) have special meaning to Python itself. These names are known as dunder names, and dunder is short for double underscore. In most cases, Python uses dunder names for methods that support a given functionality in the language’s data model.
Dunder methods are also known as special methods, and in some informal circles, they’re called magic methods. Why magic? Because Python calls them automatically in response to specific actions. For example, when you call the built-in len() function with a list object as an argument, Python calls list.__len__() under the hood to retrieve the list’s length.
In general, dunder names are reserved for supporting internal Python behaviors. So, you should avoid inventing such names. Instead, you should only use documented dunder names. In the end, creating a custom dunder name won’t have a practical effect because Python only calls those special methods that the language defines.
A few examples of commonly used dunder methods include:
| Special Method | Description |
|---|---|
.__init__() |
Provides an initializer in Python classes |
.__call__() |
Makes the instances of a class callable |
.__str__() and .__repr__() |
Provide string representations for objects |
.__iter__() and .__next__() |
Support the iterator protocol |
.__len__() |
Supports the len() function |
These are just a sample of all the special methods that Python defines. As you can see from their descriptions, all these methods support specific Python features. You can provide implementations for these methods in your custom classes so that they support the related features.
To illustrate how dunder methods work, say that you want to create a ShoppingCart class to manage the cart in an online shop. You need this class to support the len() function, which should return the number of items in the cart. Here’s how you can implement this feature:
cart.py
class ShoppingCart:
def __init__(self):
self.products = []
def add_product(self, product):
self.products.append(product)
def get_products(self):
return self.products
def __len__(self):
return len(self.products)
Your class keeps track of the added products using a list object. Then, you implement methods for adding a new product to the cart and retrieving the list of current products. The .__len__() special method returns the number of items in .products using the built-in len() function.
By implementing .__len__(), you ensure that your ShoppingCart class supports the len() function:
>>> from cart import ShoppingCart
>>> cart = ShoppingCart()
>>> cart.add_product("keyboard")
>>> cart.add_product("mouse")
>>> cart.add_product("monitor")
>>> len(cart)
3
In this snippet, you create a shopping cart and add three items. When you call len() with the cart instance as an argument, you get the number of items that are currently in the cart.
Note: It’s important to note that Python doesn’t name-mangle dunder names, even though they start with two leading underscores. That means you can do something like cart.__len__(), and it’ll work. However, calling these methods directly isn’t the recommended way to go.
Finally, Python also defines some dunder names that refer not to special methods but to special attributes and variables. Two of the most commonly used are the following:
__name__uniquely identifies the module in the import system.__file__indicates the path to the file from which a module was loaded.
You’ll often find __name__ in a common Python idiom that’s closely related to executable scripts. So, in many executable Python files, you’ll see a code snippet that looks like the following:
script.py
# ...
def main():
# Implementation...
if __name__ == "__main__":
main()
This name-main idiom allows you to execute code when you run the Python file as a script, but not when you import it as a module.
Other Uses of Underscores in Python
Up to this point, you’ve learned about some Python naming conventions that use leading or trailing underscores. You’ve seen how underscores differentiate between public and non-public names, enable name mangling, and denote dunder methods and attributes.
In this section, you’ll quickly explore other use cases of underscores in Python names. Some of these use cases include the following:
- Placeholder variables in REPL sessions
- Throwaway variables in loops and other constructs
- Wildcards in structural pattern matching
- Named tuple methods
In the context of a REPL session, the underscore character plays an implicit role: it acts as a special variable containing the result of the last evaluated expression:
>>> 12 + 30
42
>>> _
42
>>> pow(4, 2)
16
>>> _
16
In these examples, you evaluate two different expressions. Expressions always evaluate to a concrete value, which Python automatically assigns to the _ variable after the evaluation. You can access and use the _ variable as you’d use any other variable:
>>> numbers = [1, 2, 3, 4]
>>> len(numbers)
4
>>> sum(numbers) / _
2.5
In this example, you first create a list of numbers. Then, you call len() to get the number of values in the list. Python automatically stores this value in the _ variable. Finally, you use _ to compute the average of your list of values.
Throwaway variables are another common use case of underscores in Python names. You’ll often see them in for loops and comprehensions where you don’t need to use the loop variable in any computation.
To illustrate, say that you want to build a list of lists to represent a five-by-five matrix. Every row will contain integer numbers from 0 to 4. In this situation, you can use the following list comprehension:
>>> from pprint import pp
>>> matrix = [[number for number in range(5)] for _ in range(5)]
>>> pp(matrix)
[[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4],
[0, 1, 2, 3, 4]]
In this example, the outer list comprehension, [... for _ in range(5)], creates five lists. Each list represents a row in the resulting matrix. Note how you’ve used an underscore (_) as the loop variable. You do this because you don’t need this variable in the inner list comprehension, [number for number in range(5)], which fills each row with values.
Iterable unpacking is another scenario where throwaway variables can be useful:
>>> first, *_ = [1, 2, 3, 4]
>>> first
1
>>> _, second, *_ = [1, 2, 3, 4]
>>> second
2
In the first example, you unpack a list of numbers into first and *_. This latter syntax allows you to pack the unneeded values in _, which is a throwaway variable. The second example works similarly. It unpacks the numbers to _, second, and *_. In this case, you use throwaway variables for the unpacking to work, but you only care about the value of second.
Structural pattern matching was introduced to Python in version 3.10. It uses a match … case construct to compare an object to several different cases. Such statements are effective at deconstructing data structures and picking out individual elements. Python treats a single underscore as a wildcard in a case statement, so it’ll match anything. You often use it to alert the user that an object doesn’t have the expected structure.
The following example shows a recursive function that uses pattern matching to sum a list of numbers:
>>> def sum_list(numbers):
... match numbers:
... case []:
... return 0
... case [int(first) | float(first), *rest]:
... return first + sum_list(rest)
... case _:
... raise ValueError(f"can only sum lists of numbers")
...
The last case statement uses the _ wildcard and will match if numbers isn’t a list with integer and floating-point numbers. Here’s an example:
>>> sum_list([1, 2, 3])
6
>>> sum_list(["x", "y"])
Traceback (most recent call last):
...
ValueError: can only sum lists of numbers
When you try to sum a list of strings, your final case triggers and raises the ValueError exception.
Finally, have you used named tuples before? They can help you improve the readability of your code by providing named fields to access their items using dot notation. One odd characteristic of named tuples is that some of the attributes and methods in their pubic interface have a leading underscore in their names:
>>> from collections import namedtuple
>>> Point = namedtuple("Point", "x y")
>>> point = Point(2, 4)
>>> point
Point(x=2, y=4)
>>> dir(point)
[
...
'_asdict',
'_field_defaults',
'_fields',
'_make',
'_replace',
'count',
'index',
'x',
'y'
]
Besides the .count() and .index() methods, which named tuples inherit from tuple, named tuples provide three additional methods: ._asdict(), ._make(), and ._replace(). They also have two extra attributes, ._field_defaults and ._fields.
As you can see in the highlighted lines, all these additional attributes and methods have a leading underscore in their names. Why? The leading underscore prevents name conflicts with custom fields. In this case, there’s a strong reason for breaking the established convention, which aligns with the Python principle that practicality beats purity.
To illustrate, say that you have the following named tuple:
>>> from collections import namedtuple
>>> Car = namedtuple("Car", ["make", "model", "color", "year"])
>>> mustang = Car(make="Ford", model="Mustang", color="Red", year=2022)
>>> mustang.make
'Ford'
In this example, if you use the string "make" as a field name and the named tuple had a .make() method instead of the ._make() variation, then you’d have overridden the method with your custom field.
Note: Some of the public attributes of named tuples, like ._field_defaults and ._fields, may seem less likely to cause name clashes. However, they use the same naming convention for consistency. In the end, there’s no way to know what the user will do with your code.
Note that the namedtuple() function will raise an exception if you try to name any of your fields with a leading underscore:
>>> Car = namedtuple("Car", ["make", "_model", "color", "year"])
Traceback (most recent call last):
...
ValueError: Field names cannot start with an underscore: '_model'
This behavior of named tuples ensures that you don’t override any of the methods available as part of a named tuple’s API.
Conclusion
Now you know about some important Python naming conventions that rely on using the underscore character (_). You’ve learned how to differentiate between public and non-public names in Python code, write safe classes for subclassing, and avoid name clashes in your classes.
In this tutorial, you’ve:
- Learned about Python naming conventions that rely on using underscores (
_) - Differentiated public from non-public names using a single leading underscore
- Used double leading underscores to trigger name mangling in Python classes
- Explored other common use cases of underscores in Python names
This knowledge will allow you to write code that looks Pythonic and consistent in the eyes of other Python developers. These skills are especially important when you’re writing code that other developers will read, use, or build upon.
Get Your Code: Click here to download the free sample code that shows you how to use single and double underscores in Python names.
Frequently Asked Questions
Now that you have some experience with Python’s single and double underscore naming conventions, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
You use underscores in Python names to signal intent:
- A single leading underscore marks a name as non-public
- A single trailing underscore avoids naming conflicts
- Double leading underscores trigger name mangling in classes
- Double underscores at both ends indicate special methods or attributes.
Python doesn’t enforce public or private names. Instead, it encourages you to use naming conventions, such as leading underscores, to indicate whether a name is meant for public or internal use.
When you start a class attribute or method name with double leading underscores, Python automatically renames it by prefixing it with the class name to help prevent accidental overrides in subclasses.
A double underscore at both the start and end of a name, like .__init__() or .__len__(), marks it as a special method or attribute that Python uses for built-in behaviors or internal mechanisms.
You can still access name-mangled attributes using their mangled form—for example, _ClassName__attribute. However, you should avoid doing this as it breaks the developer’s intention.
Take the Quiz: Test your knowledge with our interactive “Single and Double Underscores in Python Names” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Single and Double Underscores in Python NamesIn this quiz, you'll test your understanding of the use of single and double underscores in Python names. This knowledge will help you differentiate between public and non-public names, avoid name clashes, and write code that looks Pythonic and consistent.









