A Python function is a named block of code that performs specific tasks and can be reused in other parts of your code. Python has several built-in functions that are always available, and you can also create your own. These are known as user-defined functions.
To define a function in Python, you use the def keyword, followed by the function name and an optional list of parameters enclosed in a required pair of parentheses. You can call and reuse a function by using its name, a pair of parentheses, and the necessary arguments.
Learning to define and call functions is a fundamental skill for any Python developer. Functions help organize your code and make it more modular, reusable, and easier to maintain.
By the end of this tutorial, you’ll understand that:
- A Python function is a self-contained block of code designed to perform a specific task, which you can call and reuse in different parts of your code.
- You can define a Python function with the
defkeyword, followed by the function name, parentheses with optional parameters, a colon, and then an indented code block. - You call a Python function by writing its name followed by parentheses, enclosing any necessary arguments, to execute its code block.
Understanding functions is key to writing organized and efficient Python code. By learning to define and use your own functions, you’ll be able to manage complexity and make your code easier to read.
Get Your Code: Click here to download the free sample code that shows you how to define your own function in Python.
Take the Quiz: Test your knowledge with our interactive “Defining Your Own Python Function” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Defining Your Own Python FunctionIn this quiz, you'll test your understanding of defining and calling Python functions. You'll revisit the def keyword, parameters, arguments, and more.
Getting to Know Functions in Python
In mathematics, a function is a relationship or mapping between one or more inputs and a set of outputs. This concept is typically represented by the following equation:
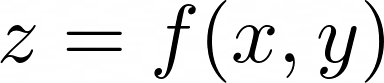
Here, f() is a function that operates on the variables x and y, and it generates a result that’s assigned to z. You can read this formula as z is a function of x and y. But how does this work in practice? As an example, say that you have a concrete function that looks something like the following:
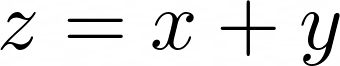
Now, say that x is equal to 4 and y is 2. You can find the value of z by evaluating the function. In other words, you add 4 + 2 to get 6 as a result. That’s it!
Functions are also used in programming. In fact, functions are so fundamental to software development that virtually all modern, mainstream programming languages support them. In programming, a function is a self-contained block of code that encapsulates a specific task under a descriptive name that you can reuse in different places of your code.
Many programming languages have built-in functions, and Python is no exception. For example, Python’s built-in id() function takes an object as an argument and returns its unique identifier:
>>> language = "Python"
>>> id(language)
4390667816
The integer number in this output uniquely identifies the string object you’ve used as an argument. In CPython, this number represents the memory address where the object is stored.
Note how similar this notation is to what you find in mathematics. In this example, language is equivalent to x or y, and the pair of parentheses calls the function to run its code, comparable to evaluating a math function. You’ll learn more about calling Python functions in a moment.
Note: To learn more about built-in functions, check out Python’s Built-in Functions: A Complete Exploration.
Similarly, the built-in len() function takes a data collection as an argument and returns its length:
>>> numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> items = len(numbers)
>>> items
10
In this example, the list of numbers has ten values, so len() returns 10. You assign this value to the items variable, which is equivalent to z in the mathematical equation you saw before.
Most programming languages—including Python—allow you to define your own functions. When you define a Python function, you decide whether it takes arguments. You’re also responsible for how the function internally computes its result.
Once you’ve defined a function, you can call it from different parts of your code to execute its specific computation or action. When the function finishes running, it returns to the location where you called it.
With this quick introduction to Python functions, you’re ready to dive deeper into creating and using functions in your code. First, you’ll examine some of the main benefits of using functions.
Exploring Some Benefits of Functions
So, why should you bother defining and using functions in Python? What are their benefits? There are several good reasons to define and use functions in your code. In the following sections, you’ll explore some of these benefits.
Abstraction
Abstraction is about managing complexity by exposing a simplified interface to the user or programmer, while keeping the internal workings of a piece of code private or irrelevant to the context of use. You can do this by hiding a given functionality inside a function and exposing only the function’s interface, consisting of its name and expected arguments, to the rest of the program.
For example, in previous sections, you used some Python built-in functions even though you don’t know how they’re implemented internally. You only knew the function’s name and its arguments. So, built-in functions abstract the implementation details and only show you a user-friendly interface.
Defining custom functions enriches your vocabulary by introducing new black boxes that the language didn’t originally have. This increases your code’s readability by using descriptive function names that unambiguously identify specific tasks, rather than using long sequences of statements without an obvious, visible goal.
Encapsulation
Encapsulation refers to bundling data and behaviors into a single unit and restricting direct access to some of these components.
When you call a function, Python creates a dedicated namespace for that function call. This namespace will hold the names you define inside the function. It’s a namespace distinct from all other existing ones, such as the global and built-in namespaces.
The practical upshot of this behavior is that the variables defined within a function are only accessible from within the function itself, which allows for data encapsulation.
Even when function’s local variables have the same names as outer variables, there will be no confusion or interference because they’re in separate namespaces. So, you can’t modify the function’s behavior by altering the value of a given local variable from the outside, whether by accident or on purpose.
Modularity
Modularity is a design principle that divides a program into separate, independent, and interchangeable components. Each component is a self-contained unit that encapsulates a specific part of the program’s functionality.
Functions allow you to divide a large program into smaller chunks that perform a specific task, making your code modular.
Imagine, for example, that you have a program that reads in a file, transforms its contents, and writes the result to a different file. You could handle these operations as a plain sequence of statements:
# Main program
# Read the file
<statement_0>
<statement_1>
...
<statement_n>
# Process the file
<statement_0>
<statement_1>
...
<statement_n>
# Write the result to another file
<statement_0>
<statement_1>
...
<statement_n>
In this example, your program is a bunch of sequential statements, with whitespace and comments to help organize it. However, if the code were to get much longer and more complex, then you’d have an increasingly difficult time wrapping your head around it.
Alternatively, you could structure the code as shown below:
def read_file():
<statement_0>
<statement_1>
...
<statement_n>
def process_file():
<statement_0>
<statement_1>
...
<statement_n>
def write_file():
<statement_0>
<statement_1>
...
<statement_n>
# Main program
read_file()
process_file()
write_file()
In this example, you modularize the code. Instead of all the code being strung together, it’s broken into separate functions, each focusing on a specific task. Those tasks are read, process, and write. The main program now calls each of these functions in turn.
Note: The def keyword lets you define a new function in Python. You’ll learn all about this keyword in the section on function definition.
As programs become more complicated, modularizing them with functions becomes increasingly beneficial. Breaking a task into smaller subtasks helps you manage complex programming problems. It also facilitates debugging because you can focus on simpler tasks that are often easier to debug than complex and overly long tasks.
Reusability
Reusability is the ability to use existing code in new contexts without repeating the code itself. It implies writing code in a way that allows you to use it multiple times across different parts of a program, or even across multiple projects, with little or no modification.
Suppose you’ve written some code that does something useful. As you continue development, you find that the code performs a task you often need in many different locations within your program. What should you do?
Say that you decide to replicate the code over and over again, using your editor’s copy-and-paste capability. What would happen if you later realize that the piece of code in question must be modified or updated? If copies of the code are scattered all over your program, then you’ll need to make the necessary changes in every location.
Code duplication can lead to another issue. If a developer updates most but not all instances of the repeated code, this can result in inconsistencies in data or behavior across the program.
A better solution is to define a Python function that performs the task. Then, you can call the function from any part of your program that you need to accomplish the task. Down the line, if you decide to change how the code works, then you only need to change the code in one location: the function’s definition. The changes will automatically be picked up anywhere you call the function.
Note: Functions aren’t a one-size-fits-all solution. Sometimes, repeating a chunk of code in multiple places would be the best approach, especially if you’re working with code where the execution speed is critical. In this scenario, repeating the code might be faster than calling the function multiple times, because function calls might add significant speed overhead to the code.
The don’t repeat yourself (DRY) principle of software development is a strong motivation for using functions. Functions help eliminate repetitive code. They also allow you to align with other core software engineering principles, such as the single-responsibility principle (SRP).
Maintainability
In programming, maintainable code refers to code that you can quickly and easily understand, correct, enhance, or adapt over time. A maintainable codebase is clear, well-structured, and modular, allowing developers to make changes with minimal risk of introducing bugs.
Functions help with code maintainability because they allow you to do the following:
- Break down code into logical parts
- Encourage reuse and consistency
- Reduce duplication and errors
- Facilitate testing and debugging
- Encourage clear documentation
In short, functions are a great tool for writing maintainable code. This type of code is easier to improve and scale with new features, which is often a common need.
Testability
Testability refers to how easy it is to effectively test a piece of code to ensure it behaves as expected. You have a piece of testable code if it’s straightforward to write automated tests that verify its correctness.
Writing functions with clear arguments and explicit return values makes your code easier to test and predict. When you avoid side effects in your functions and follow the single responsibility principle, they become easier to reason about. Additionally, keeping your functions small and readable further enhances their quality. Together, these practices greatly improve the testability of your code.
Defining Functions in Python
Now it’s time to start defining your own functions in Python. The general syntax for defining a function is shown below:
def function_name([parameters]):
<block>
Below, you have a breakdown of this syntax’s components:
| Component | Description |
|---|---|
def |
The keyword that begins the function definition |
function_name |
A valid Python identifier that names the function |
[parameters] |
An optional, comma-separated list of formal parameters for the function |
: |
The punctuation that denotes the end of the function header |
<block> |
The function’s code block |
The final item, <block>, is usually called the function’s body. The body is a series of statements that will run when you call the function. The body is defined by indentation. This is the same as code blocks associated with a control structure, like an if or while statement.
Note: Python has what are known as lambda functions. These allow you to create custom anonymous functions whose bodies consist of a single expression. This tutorial doesn’t cover this type of function. To learn more about them, check out How to Use Python Lambda Functions.
Here’s your first Python function:
>>> def greet(name):
... print(f"Hello, {name}!")
...
>>> greet("Pythonista")
Hello, Pythonista!
You start the function’s definition with the def keyword. Then, you have the function name, greet, followed by a pair of parentheses enclosing an argument called name. To close the function header, you use a colon (:).
Next, you have an indented code block consisting of a call to the built-in print() function. This call will display a greeting message on your screen. Finally, you call the function using "Pythonista" as an argument. As a result, you get Hello, Pythonista! printed on the screen.
Note: Occasionally, you may want to define a function that does nothing. This is referred to as a stub, which is usually a temporary placeholder for a Python function that will be fully implemented at a later time. To define a stub function in Python, you use the pass statement, or in some contexts, a Python ellipsis (...):
>>> def function():
... pass
...
>>> function()
As you can conclude from this example, this stub function is syntactically valid but doesn’t do anything when you call it. You need the pass statement to make the function syntactically correct, as function bodies can’t be empty.
Now you know the basics of defining functions. In the following section, you’ll learn more about different ways to call functions in Python.
Calling Functions in Python
You’ve already called a few functions so far. The syntax consists of writing the function’s name followed by a pair of parentheses, which encloses an optional series of arguments:
function_name([arguments])
Here, <arguments> represent the concrete values that you pass into the function. They correspond to the <parameters> in the Python function definition.
Note: There’s a subtle distinction between the terms parameter and argument. Parameters are those names used in the function definition, while arguments are the concrete values that you supply for each parameter in the function call. In Python, the term argument is often used informally to refer to both.
The arguments are optional, meaning that you can have functions without arguments. However, the parentheses are required when you intend to call the function, even if the function takes no arguments. Both function definitions and calls must always include parentheses, even when they’re empty.
You’ll get a syntax error if you forget the parentheses in a function definition. If you forget the parentheses in a function call, then you’ll get a function object instead of the expected result that the function should produce.
Note: Forgetting the parentheses in a function call might be a common mistake when you’re starting out with Python. So, if you intend to call a function, make sure you add the parentheses. Otherwise, you could end up with unexpected behavior and a hard-to-track bug.
In the following two sections, you’ll learn about two main ways to call Python functions. Maybe you’ll even figure out which one feels most natural to you.
Positional Arguments
The quickest way to call a function with arguments is to rely on the specific position of each argument. In this case, you’ll be using what’s known as positional arguments.
In the function definition, you specify a series of comma-separated parameters inside the parentheses. For example, consider the following function that computes the cost of a product and displays a message to the screen:
>>> def calculate_cost(item, quantity, price):
... print(f"{quantity} {item} cost ${quantity * price:.2f}")
...
To call this function, you must specify a corresponding list of arguments in the correct order:
>>> calculate_cost("bananas", 6, 0.74)
6 bananas cost $4.44
The parameters item, quantity, and price are like variables defined locally in the function. When you call the function, the values "bananas", 6, and 0.74 are bound to the parameters in order, as though by variable assignment:
| Parameter | Value | |
|---|---|---|
item |
← | "bananas" |
quantity |
← | 6 |
price |
← | 0.74 |
Although positional arguments are a common way to pass data to a function, they could cause some issues. The order of the arguments in the call must match the order of parameters in the definition. If you change the order, then you may get unexpected behavior or an error:
>>> calculate_cost("bananas", 0.74, 6)
0.74 bananas cost $4.44
>>> calculate_cost(6, "bananas", 0.74)
Traceback (most recent call last):
...
TypeError: can't multiply sequence by non-int of type 'float'
As in the first call above, the function may still run, but it’s unlikely to produce the correct results. The programmer who defines the function must document the arguments appropriately, and the user must be aware of that information and stick to it.
Note: When documenting functions, you’ll find the concept of a signature useful. The signature of a function consists of its name followed by its arguments in parentheses. For example, here’s the signature of your calculate_cost() function:
calculate_cost(item, quantity, price)
If you’ve used descriptive names for the function and its arguments, then this notation will give a good idea of how to use the function.
In summary, the arguments in the call and the parameters in the definition of a function must agree in order and number. In a sense, positional arguments are required because if they don’t have a default argument value, then you can’t leave them out when calling the function:
>>> # Too few arguments
>>> calculate_cost("bananas", 6)
Traceback (most recent call last):
...
TypeError: calculate_cost() missing 1 required positional argument: 'price'
>>> # Too many arguments
>>> calculate_cost("bananas", 6, 0.74, "mango")
Traceback (most recent call last):
...
TypeError: calculate_cost() takes 3 positional arguments but 4 were given
Positional arguments are conceptually straightforward to use, but they’re not forgiving. You must specify the same number of arguments in the function call as there are parameters in the definition. They must also be in exactly the same order.
Another drawback of positional arguments is that they can make the code hard to read at times. For example, consider the following hypothetical function call:
update_product(1234, 15, 2.55, "12-31-2025")
Can you tell the meaning of each argument by looking at the function call? Probably not. In the following section, you’ll explore a different way to call Python functions to help you deal with these two issues.
Keyword Arguments
When calling a function, you can specify arguments in the form argument=value. This way of passing arguments to a Python function is known as using keyword arguments. For example, you can call the calculate_cost() function as shown below:
>>> calculate_cost(item="bananas", quantity=6, price=0.74)
6 bananas cost $4.44
Using keyword arguments lifts the restriction on argument order because each keyword argument explicitly designates a specific parameter by name, so you can specify them in any order, and Python will know which argument goes with which parameter:
>>> calculate_cost(price=0.74, quantity=6, item="bananas")
6 bananas cost $4.44
If you use keyword arguments in a function call, Python has an unambiguous way to determine which argument goes to which parameter. So, you don’t have the restriction of providing the arguments in a strict order.
Like with positional arguments, though, the number of arguments and parameters must still match:
>>> calculate_cost(item="bananas", quantity=6)
Traceback (most recent call last):
...
TypeError: calculate_cost() missing 1 required positional argument: 'price'
So, keyword arguments allow flexibility in the order that function arguments are specified, but the number of arguments is still rigid.
The second advantage of keyword arguments is readability. Do you remember the update_product() function from the previous section? Check out at how it’d look using keyword arguments in the call:
# Using positional arguments
update_product(1234, 15, 2.55, "12-31-2025")
# Using keyword arguments
update_product(
product_id=1234,
quantity=15,
price=2.55,
expiration_date="12-31-2025"
)
Isn’t the call with keyword arguments way more readable than the call with positionals? When you call functions in your code, if there’s a risk of ambiguity, try to use keyword arguments if possible. This tiny detail will improve your code’s readability.
You can also call a function using both positional and keyword arguments:
>>> calculate_cost("bananas", quantity=6, price=0.74)
6 bananas cost $4.44
In this example, you’ve provided item as a positional argument. In contrast, quantity and price are keyword arguments.
When you use positional and keyword arguments in a function call, all the positional arguments must come first. Otherwise, you’ll get a syntax error:
>>> calculate_cost(item="bananas", quantity=6, 0.74)
File "<input>", line 1
calculate_cost(item="bananas", quantity=6, 0.74)
^
SyntaxError: positional argument follows keyword argument
Once you’ve specified a keyword argument, you can’t place any positional arguments after it. In this example, you use keyword arguments for item and quantity, but positional arguments for price. This raises a SyntaxError exception because Python’s grammar prohibits positional arguments following keyword arguments to avoid ambiguity.
Finally, referencing a keyword that doesn’t match any of the declared parameters generates an exception:
>>> calculate_cost(item="bananas", quantity=6, cost=0.74)
Traceback (most recent call last):
...
TypeError: calculate_cost() got an unexpected keyword argument 'cost'
In this example, you use cost as a keyword argument. This argument doesn’t match any parameter in the function definition, so you get a TypeError exception.
Returning From Functions
Up to this point, you’ve learned the basics of defining and calling functions. However, there are important details to consider when you define functions in Python. For example, how should a function affect its caller or the global environment?
In general, functions can do one or more of the following:
- Cause a side effect on its environment
- Return a value to its caller
- Cause a side effect and return a value
For example, a function that only prints data to the screen is just causing a side effect on its environment. This is the case with your calculate_cost() function in the last example.
In contrast, a function can return a value to the caller, which the caller can then use in further computations. That’s the case with the built-in len() function, which doesn’t produce any effects on its environment. It only returns the number of items in a collection.
In the following sections, you’ll learn how to write Python functions that cause side effects and functions that return concrete values to the caller.
Producing Side Effects
In a Python function, you can modify an object from an outer scope. That change will reflect in the calling environment and affect the general behavior of your code. For example, you can modify the value of a global variable within a function. This is a classic example of what’s known as a side effect.
More generally, a Python function is said to cause a side effect if it modifies its calling environment in any way.
Note: Hidden or unexpected side effects can lead to errors that are difficult to track down. Generally, you should avoid side effects even in some situations where they could be intentional.
A piece of code that relies on functions with side effects can be hard to debug and understand because it will have many sources of changes that will affect the code’s state.
Suppose you have the following instruction from your employer: Write a function that takes a list of integer values and doubles them. Since these instructions aren’t very precise, you could end up with something like the following:
>>> def double(numbers):
... for i, _ in enumerate(numbers):
... numbers[i] *= 2
...
>>> numbers = [1, 2, 3, 4, 5]
>>> double(numbers)
>>> numbers
[2, 4, 6, 8, 10]
This function works by generating a side effect. It takes a list of numbers, iterates over it with a for loop, gets the index of each value with the help of enumerate(), and modifies the input list by replacing each value with its double. You’ve completed your assignment.
Note: In Python functions, if you modify the content of mutable arguments like a list or dictionary in place, then these changes will reflect on the original object outside the function.
However, if you assign a new value to an argument inside a function, then the change won’t reflect on the outer object unless you use the global statement.
To learn more about this particular topic, check out the Using and Creating Global Variables in Your Python Functions tutorial.
Now you present your results to your boss, who says: “This function isn’t quite right. It overrides the original data, and that’s not what we want.”
So how can you avoid this side effect? Well, instead of modifying the input list, you can just create a new list containing the double values:
>>> def double(numbers):
... result = []
... for number in numbers:
... result.append(number * 2)
... return result
...
>>> numbers = [1, 2, 3, 4, 5]
>>> double_numbers = double(numbers)
>>> double_numbers
[2, 4, 6, 8, 10]
>>> numbers
[1, 2, 3, 4, 5]
Now, your function takes a list of numbers and creates a new list of double numbers. Note how the original data is unchanged. You’ve removed the unwanted side effect.
Note: You can refactor the double() function a bit using a list comprehension:
def double(numbers):
return [number * 2 for number in numbers]
This implementation works the same as the previous one but is more compact and Pythonic. To learn more about list comprehensions, check out the tutorial on When to Use a List Comprehension in Python.
Side effects aren’t necessarily consummate evil. They can have their place. However, because you can virtually return anything from a function, the same result of a side effect can be accomplished through return values.
Returning Values
Python functions can return concrete values, as you briefly saw at the end of the previous section. To do this, you can use the return statement, which serves two purposes:
- Passing data back to the caller
- Terminating the function and passing execution control back to the caller
If you place a return statement followed by an expression inside a Python function, then the calling environment will get the value of that expression back:
>>> def identity(x):
... return x
...
>>> x = identity(42)
>>> x
42
This function mimics an identity function in math. It maps every input value to itself. In this example, you use return x to return a concrete value from your function. The general syntax for a return statement is shown below:
def function_name():
return [expression_0[, expression_1, ..., expression_n]]
First, you need to know that you can’t use the return statement outside of a function. If you do so, then you’ll get a SyntaxError exception. Second, the expression or expressions that follow the return keyword are optional. That’s what the square brackets mean in this syntax.
Note: To dive deeper into returning from functions, check out The Python return Statement: Usage and Best Practices.
In summary, you can have a return statement with zero, one, or more expressions. If you have multiple expressions, then you must separate them with commas. In this case, the caller will receive a tuple of values:
>>> def create_point(x, y):
... return x, y
...
>>> create_point(2, 4)
(2, 4)
If you specify multiple comma-separated expressions in a return statement, then they’re packed and returned as a tuple object, as shown in the example above.
Note: You can have multiple return statements in a function. You’ll learn more about this throughout the tutorial.
Python functions can return any object. That means anything whatsoever, even other functions. In the calling environment, you can use a function’s return value in any way that’s appropriate for its type.
For example, in this code, as_dict() returns a dictionary. In the calling environment, the call to this function returns a dictionary, and something like as_dict()["key"] is an entirely valid syntax:
>>> def as_dict():
... return dict(one=1, two=2, three=3)
...
>>> as_dict()
{'one': 1, 'two': 2, 'three': 3}
>>> as_dict()["two"]
2
When you call a function that returns a concrete value, you can use that value in any expression or further computation. So, you’ll often find and use function calls in expressions.
You can also have a bare return with no expression at the end. In this case, the function will return None:
>>> def function():
... return
...
>>> print(function())
None
Here, the return value is None by default. Note that Python REPL sessions don’t show None when you call a function that returns this object. That’s why you need to use print() in this example.
You can alternatively return None explicitly when this value has a specific semantic meaning in your code. In this case, doing something like return None will explicitly express your code’s intent. For example, the function below takes a username and checks whether that name is in the current user list:
>>> def find_user(username, user_list):
... for user in user_list:
... if user["username"] == username:
... return user
... return None
...
>>> users = [
... {"username": "alice", "email": "alice@example.com"},
... {"username": "bob", "email": "bob@example.com"},
... ]
>>> find_user("alice", users)
{'username': 'alice', 'email': 'alice@example.com'}
>>> print(find_user("linda", users))
None
Although not mandatory, returning None explicitly is an appropriate and readable solution in this example. If you get None, it’s because the user wasn’t found.
Python returns None automatically from a function that doesn’t include explicit return statements:
>>> def function():
... pass
...
>>> print(function())
None
This function doesn’t have an explicit return statement. However, it returns None as in the previous example. This is the default behavior for all Python functions where you don’t have an explicit return statement, or where a specific execution doesn’t hit any of the existing ones.
You can use functions that return None explicitly in a Boolean context. In this case, the Pythonic way to check the return value would be as shown below:
>>> if find_user("linda", users) is None:
... print("Linda isn't a registered user")
...
Linda isn't a registered user
You compare the function’s return value against None using the is operator. You can also use the is not operator for appropriate situations.
Note: To learn more about the is and is not operators, check out Python != Is Not is not: Comparing Objects in Python tutorial.
For example, if you want to do some further processing with the user’s data, then you can do something like the following:
>>> if find_user("alice", users) is not None:
... print("Do something with Alice's data...")
...
Do something with Alice's data...
In Python, if you have a condition that can evaluate to None, then you should explicitly compare it with that object using the is and is not operators. This makes it clear that you’re specifically checking for the absence of a value, avoiding confusion with other falsy values like 0, "", or False.
Exiting Functions Early
The return statement causes Python to exit from a function immediately and transfer the execution’s control back to the caller. This behavior allows you to use a bare return when you need to terminate a function’s execution early.
Consider the following toy example that processes a file:
from pathlib import Path
def read_file_contents(file_path):
path = Path(file_path)
if not path.exists():
print(f"Error: The file '{file_path}' does not exist.")
return
if not path.is_file():
print(f"Error: '{file_path}' is not a file.")
return
return path.read_text(encoding="utf-8")
In this function, you have two conditionals. The first one checks if the file exists. If it doesn’t, an error message is printed and the function exits. Next, the second one checks if the provided path points to a file. If not, another error message is printed and the function returns. In the final line of this function, you have another return statement that returns the file’s content, which is the function’s primary goal.
Returning Boolean Values
Another common use case of the return statement is when you need a function to return True or False depending on some concrete condition of your code. These types of functions are known as Boolean-valued functions or predicates.
For example, here’s a function that checks whether a number is even:
>>> def is_even(number):
... return number % 2 == 0
...
>>> is_even(2)
True
>>> is_even(3)
False
In this example, the return value comes from a condition that evaluates to either True or False, depending on the input number.
Predicate functions are common and useful in programming. For example, Python’s built-in functions all(), any(), hasattr(), isinstance(), and issubclass() are all predicate functions.
Returning Generator Iterators
Generator iterators are objects that allow you to iterate over a stream of data or large datasets without storing the entire dataset in memory at once. Instead, generator iterators yield items on demand, which makes them memory efficient.
With the yield keyword, you can convert a normal Python function into a generator function that returns a generator iterator.
Note: To learn more about generators, check out the How to Use Generators and yield in Python tutorial.
These functions are handy when you’re working with large datasets and aiming to make your code more memory-efficient. For example, say that you have a large list of numeric data and want to iterate over it while you compute the current average:
>>> def cumulative_average(numbers):
... total = 0
... for items, number in enumerate(numbers, 1):
... total += number
... yield total / items
...
>>> values = [5, 3, 8, 2, 5] # Simulates a large data set
>>> for cum_average in cumulative_average(values):
... print(f"Cumulative average: {cum_average:.2f}")
...
Cumulative average: 5.00
Cumulative average: 4.00
Cumulative average: 5.33
Cumulative average: 4.50
Cumulative average: 4.60
In this example, cumulative_average() is a generator that calculates and yields the cumulative average of a sequence of numbers. Because generator iterators yield items on demand, you only keep the original data in memory. The computed averages are generated one by one, so at any given time, you only have one of those values in memory.
Again, generator functions allow you to efficiently process large datasets or manage data streams, as values are produced one at a time on demand. Using a generator avoids storing all the data in memory, which is useful in data pipelines, financial calculations, or monitoring applications.
Creating Closures
A closure is a function that remembers, accesses, and uses variables from its enclosing function, even after that outer function has finished executing. In other words, it’s an inner function that closes over the variables it needs from the outer function, keeping them alive for later use.
Here’s a toy example of a closure:
>>> def function():
... value = 42
... def closure():
... print(f"The value is: {value}!")
... return closure
...
>>> reveal_number = function()
>>> reveal_number()
The value is: 42!
Inside function(), you first define a variable called value. Then, you define an inner function called closure(). This function prints a message using the variable value from its enclosing scope.
Finally, you return the closure function object from function(). Because of this, when you call function(), you get a function object as a result. This function object remembers the value variable even though the outer function has terminated. You can call reveal_number() to confirm this behavior.
Note: To learn more about closures, check out the Python Closures: Common Use Cases and Examples tutorial.
Likewise, to learn more about inner functions in general, check out the Python Inner Functions: What Are They Good For? tutorial.
In practice, closures have several use cases. You can use closures to create stateful functions, callbacks, decorators, factory functions, and more.
Consider the following example:
>>> def generate_power(exponent):
... def power(base):
... return base**exponent
... return power
...
>>> square = generate_power(2)
>>> square(4)
16
>>> square(6)
36
>>> cube = generate_power(3)
>>> cube(3)
27
>>> cube(5)
125
In this example, the generate_power() function returns a closure. The inner function, power(), uses its base argument and the exponent argument from the outer function to compute the specified power.
Note how the closure object that results from calling generate_power() remembers the exponent between calls. This is a good example of how to use closures to create factory functions.
Defining and Calling Functions: Advanced Features
Up to this point, you’ve learned the basics of Python functions. Beyond that, Python offers a rich set of features that make functions quite flexible and powerful. You’ll explore advanced features that let you provide default argument values and accept a variable number of positional or keyword arguments. You’ll also learn about positional-only and keyword-only arguments.
All these features give you finer control over how you define and call functions. By understanding them, you can write cleaner, more reusable, and more robust code that adapts to different contexts.
Default Argument Values
If you assign a value to a given parameter in the definition of a function, then that value becomes a default argument value. Parameters with a default value are optional parameters, which means that you can call the function without providing a concrete argument value because you can rely on the default value.
Note: To dive deeper into default argument values and optional arguments, check out the Using Python Optional Arguments When Defining Functions tutorial.
Here’s a quick toy example of a function definition with a default argument value:
>>> def greet(name="World"):
... print(f"Hello, {name}!")
...
>>> greet()
Hello, World!
>>> greet("Pythonista")
Hello, Pythonista!
While defining greet(), you provide a default value to the name parameter. This way, when you call the function, you can rely on that default value. If you pass a concrete argument, then Python overrides the default to use whatever you passed.
Objects like None, True, and False are commonly used as default argument values in Python functions. Boolean values are useful when your functions have arguments that work as flags.
Consider the following example:
>>> def greet(name, verbose=False):
... if verbose:
... print(f"Hello, {name}! Welcome to Real Python!")
... else:
... print(f"Hello, {name}!")
...
>>> greet("Pythonista", verbose=True)
Hello, Pythonista! Welcome to Real Python!
>>> greet("Pythonista")
Hello, Pythonista!
In this new implementation of greet(), you define name as a required positional argument. In contrast, verbose is an optional flag that defaults to False. When you call the function, you can set verbose to True and get a longer greeting, or you can ignore the argument to get a shorter one instead.
A common gotcha in Python is to use a mutable object as a default argument value. Consider the function below:
>>> def append_to(item, target=[]):
... target.append(item)
... return target
...
This is just a demonstrative function. It appends item to the end of target, which defaults to an empty list. At first glance, it may seem that consecutive calls to append_to() will return single-item lists like in the following hypothetical code:
>>> append_to(1)
[1]
>>> append_to(2)
[2]
>>> append_to(3)
[3]
However, because Python defines the default argument value when it first parses the function and doesn’t overwrite it in every call, you’ll be working with the same list object in every call. Therefore, you don’t get the behavior above. Instead, you get the following:
>>> append_to(1)
[1]
>>> append_to(2)
[1, 2]
>>> append_to(3)
[1, 2, 3]
The target list remembers the data between calls. This happens because you’re using the same list object that appears as the default value in the function’s definition.
As a workaround, consider using a default argument value that communicates that no argument has been specified. In this situation, using None is a common choice. When the sentinel value indicates that no argument is given, you create a new empty list inside the function:
>>> def append_to(item, target=None):
... if target is None:
... target = []
... target.append(item)
... return target
...
>>> append_to(1)
[1]
>>> append_to(2)
[2]
>>> append_to(3)
[3]
Now, target defaults to None instead of an empty list. Then, you check whether the variable is None. If that’s the case, then you create a new empty list that’s local to the function.
Using other mutable objects, such as dictionaries or sets, can cause a similar issue. The function can change items in place within the object, and these changes will be reflected in the calling environment.
Variable Number of Positional Arguments: *args
Python provides a syntax for passing an arbitrary number of positional arguments to a function. The syntax consists of adding a leading asterisk to the argument’s name. In most scenarios, you’ll see this syntax as *args, but you can use whatever argument name fits your needs.
Here’s a quick demonstration of how this syntax works:
>>> def function(*args):
... print(args)
...
>>> function(1, 2, 3, 4, 5)
(1, 2, 3, 4, 5)
In the function’s definition, you use the *args syntax. Then, when you call this function with an arbitrary number of arguments, Python packs them into a tuple.
To illustrate with a more realistic example, say that you want to implement an average() function that can take any number of positional arguments and compute their average. You can do this with *args:
>>> def average(*args):
... return sum(args) / len(args)
...
>>> average(1, 2, 3, 4, 5, 6)
3.5
>>> average(1, 2, 3, 4, 5, 6, 7)
4.0
>>> average(1, 2, 3, 4, 5, 6, 7, 8)
4.5
This function is quite flexible, allowing you to compute the average of an arbitrary number of input values. Because args is a tuple, you can use the len() function to determine the number of provided arguments and calculate the average in a quick and accurate way.
Note that this implementation of average() glosses over some edge cases, like calling the function with no arguments. It’s only a quick demonstration of how you can use *args in a real-world use case.
Variable Number of Keyword Arguments: **kwargs
The Python feature covered in the previous section is pretty useful, isn’t it? Well, the story doesn’t end there. Python also has the **kwargs syntax that lets you pass an arbitrary number of keyword arguments to a function.
Placing a double asterisk (**) before a parameter name in a function definition tells Python to pack the provided keyword arguments into a dictionary:
>>> def function(**kwargs):
... print(kwargs)
...
>>> function(one=1, two=2, three=3)
{'one': 1, 'two': 2, 'three': 3}
In this case, Python packs the keyword arguments one=1, two=2, and three=3 into a dictionary. Then, you can use the kwargs dictionary in the function body as a regular dictionary.
Again, you can use any name, but the peculiar kwargs—which is short for keyword arguments—is widely used and has become a standard. You don’t have to adhere to it, but if you do, then anyone familiar with Python conventions will know what you mean.
It’s important to note that for this feature to work, you must use valid Python identifiers for the keyword arguments. You can’t use things that could be valid dictionary keys but invalid identifiers like, for example, 1="one".
Here’s a practical example of using **kwargs. Say you want to write a function that builds a report, but you don’t always know ahead of time which fields will be passed:
>>> def report(**kwargs):
... print("Report:")
... for key, value in kwargs.items():
... print(f" - {key.capitalize()}: {value}")
...
>>> report(name="Keyboard", price=19.99, quantity=5, category="PC Components")
Report:
- Name: Keyboard
- Price: 19.99
- Quantity: 5
- Category: PC Components
In this example, your report() function uses the **kwargs syntax to accept an arbitrary number of keyword arguments. The kwargs object is a dictionary, so you can iterate over it as you would with a regular dictionary. You take advantage of this fact to build a formatted report with the input data.
Again, you need to be aware that report() doesn’t consider the edge case of calling the function without arguments.
Positional and Keywords Combined: *args and **kwargs
Think of *args as a variable-length positional argument list, and **kwargs as a variable-length keyword argument list.
Note: For a closer look at *args and **kwargs, check out the Python args and kwargs: Demystified tutorial.
You can combine *args and **kwargs in one Python function definition. In fact, this is a pretty common practice. To combine them correctly, you must specify them in order:
>>> def function(*args, **kwargs):
... print(args)
... print(kwargs)
...
>>> function(1, 2, 3, one=1, two=2, three=3)
(1, 2, 3)
{'one': 1, 'two': 2, 'three': 3}
This feature gives you just about as much flexibility as you could ever need in a function interface! Note that you can also combine this syntax with regular positional arguments:
>>> def function(a, b, *args, **kwargs):
... print(a)
... print(b)
... print(args)
... print(kwargs)
...
>>> function("A", "B", 1, 2, 3, one=1, two=2, three=3)
A
B
(1, 2, 3)
{'one': 1, 'two': 2, 'three': 3}
If you combine these types of arguments, then you must define them in order. The positional arguments first, then *args, and finally **kwargs.
Positional-Only Arguments
As of Python 3.8, the language allows you to have what is known as positional-only arguments in your functions. These arguments must be supplied positionally and can’t be specified by keyword.
To specify that one or more arguments are positional-only, you use a bare slash (/) in the parameter list of your function definition. The parameters to the left of the slash must be passed by position in the calls to the function. This means that you can’t pass them as keyword arguments.
For example, in the following function definition, first_name and last_name are positional-only arguments, but title may be specified by keyword:
>>> def format_name(first_name, last_name, /, title=None):
... full_name = f"{first_name} {last_name}"
... if title is not None:
... full_name = f"{title} {full_name}"
... return full_name
...
>>> # Correct calls
>>> format_name("Jane", "Doe")
'Jane Doe'
>>> format_name("John", "Doe", title="Dr.")
'Dr. John Doe'
>>> format_name("Linda", "Brown", "PhD.")
'PhD. Linda Brown'
>>> # Incorrect calls
>>> format_name("John", last_name="Doe", title="Dr.")
Traceback (most recent call last):
...
TypeError: format_name() got some positional-only arguments passed as
⮑ keyword arguments: 'last_name'
The first three calls are valid because you pass the first two arguments by position, and the final argument is either a keyword or a positional argument. In contrast, the final call raises a TypeError exception because you tried to call the function using last_name as a keyword argument, which isn’t allowed, as this argument is positional-only.
You can also use the / symbol as the last item in the list of parameters if you don’t have any additional arguments and want all the function arguments to be positional-only:
def hypotenuse(a, b, /):
return (a**2 + b**2)**0.5
Both legs, a and b, must be provided as positional arguments in this function. This is probably a safe way to go because the order in which you provide the legs doesn’t affect the result. Because you don’t need any additional argument, the / symbol is at the last position in the parameter list.
Note that in this case, you can’t use keyword arguments to call this function like in hypotenuse(a=3, b=4). If you do, then you’ll get a TypeError as before.
Keyword-Only Arguments
You can also define functions where you must provide arguments using the keyword syntax. These arguments are known as keyword-only arguments. There are two main ways to define these types of arguments:
- Add parameters to the right of
*argsin a function’s definition - Include a bare asterisk (
*) in the list of parameters and place more parameters after it
In general, the parameters to the right of the asterisk (*) only accept values provided as keyword arguments. That’s why they’re called keyword-only arguments.
For example, the following function adds a series of numbers together and lets you set the precision:
>>> def sum_numbers(*numbers, precision=2):
... return round(sum(numbers), precision)
...
>>> sum_numbers(1.3467, 2.5243, precision=3)
3.871
>>> sum_numbers(1.3467, 2.5243, 3)
6.87
In this example, the *numbers syntax lets your function accept an arbitrary number of values. The precision parameter can only be provided as a keyword argument. Note the different results that you get from the two calls. In the first call, you use a keyword argument to provide the precision. As a result, you get the sum of the first two arguments with a precision of 3 digits.
In the second call, you get the sum of the three arguments with a precision of 2. In this call, the precision argument relies on its default value, and all the arguments are packed into numbers.
To illustrate the second approach for keyword-only arguments, the following function performs the specified operation on two numerical arguments. The third argument defines the operation and must be passed as a keyword argument. Note that this argument doesn’t have a default value, so it’s required:
>>> def calculate(x, y, *, operator):
... if operator == "+":
... return x + y
... elif operator == "-":
... return x - y
... elif operator == "*":
... return x * y
... elif operator == "/":
... return x / y
... else:
... raise ValueError("invalid operator")
...
>>> calculate(3, 4, operator="+")
7
>>> calculate(3, 4, operator="-")
-1
>>> calculate(3, 4, operator="*")
12
>>> calculate(3, 4, operator="/")
0.75
>>> calculate(3, 4, "+")
Traceback (most recent call last):
...
TypeError: calculate() takes 2 positional arguments but 3 were given
The bare asterisk * in the list of parameters indicates that the parameters on its right must be passed as keyword arguments. If you try to pass this argument as a normal positional argument, then you get a TypeError exception.
Finally, you can combine positional-only and keyword-only arguments in the same function definition. Here’s a toy example:
>>> def function(x, y, /, z, w, *, a, b):
... print(x, y, z, w, a, b)
...
>>> # Correct calls
>>> function(1, 2, 3, 4, a="A", b="B")
1 2 3 4 A B
>>> function(1, 2, z=3, w=4, a="A", b="B")
1 2 3 4 A B
>>> # Incorrect calls
>>> function(1, y=2, z=3, w=4, a="A", b="B")
Traceback (most recent call last):
...
TypeError: function() got some positional-only arguments passed as
⮑ keyword arguments: 'y'
>>> function(1, 2, 3, 4, "A", b="B")
Traceback (most recent call last):
...
TypeError: function() takes 4 positional arguments but 5 positional
⮑ arguments (and 1 keyword-only argument) were given
In this function, you have the following combination of arguments:
xandyare positional-only arguments, so you can’t provide them as keyword arguments.zandware normal positional arguments, so you may specify them as positional or as keyword arguments.aandbare keyword-only arguments, so you can’t provide them as positional arguments.
As you can see, these combinations of argument types allow you to have flexible and powerful functions that you can call in many different ways depending on your needs and context.
Using Other Advanced Ways to Call Functions
Beyond the standard approaches of passing arguments as positional, keyword, positional-only, and keyword-only arguments, Python also provides powerful techniques for unpacking collections of values directly into function arguments.
In this section, you’ll learn how to use the iterable unpacking operator (*) to unpack an iterable into positional arguments, and how to use the dictionary unpacking operator (**) to unpack a mapping or dictionary into keyword arguments.
Unpacking an Iterable Into Positional Arguments
When you precede an iterable in a function call with an asterisk (*), you’re performing an unpacking operation. You unpack the iterable into a series of independent values. If you use this syntax in a function call, then the unpacked values become positional arguments.
Here’s a demonstrative example:
>>> def function(x, y, z):
... print(f"{x = }")
... print(f"{y = }")
... print(f"{z = }")
...
>>> numbers = [1, 2, 3]
>>> function(*numbers)
x = 1
y = 2
z = 3
The syntax *numbers in this function call indicates that numbers is an iterable and should be unpacked into individual values. The unpacked values, 1, 2, and 3, are then assigned to the arguments x, y, and z, in that order.
The unpacking syntax shown in the example above is way cleaner and more concise than something like the following:
>>> function(numbers[0], numbers[1], numbers[2])
x = 1
y = 2
z = 3
Even though you get the same result, the unpacking syntax is more Pythonic. Note that this type of call often involves using numeric indices, which can be error-prone.
The iterable unpacking (*) operator can be applied to any iterable in a Python function call. For example, you can use a list, a tuple, or a set. If you use a set, then you must be aware that sets are unordered containers, which can cause issues when the order of positional arguments is relevant.
However, in some cases, using a set is okay. For example, here’s your hypotenuse() function:
>>> def hypotenuse(a, b, /):
... return (a**2 + b**2)**0.5
...
>>> legs = {2, 5}
>>> legs
{2, 5}
>>> hypotenuse(*legs)
5.385164807134504
In this example, you can provide the arguments in any order, so it’s safe to unpack the legs from a set.
You can use the iterable unpacking operator and the *args syntax at the same time:
>>> def function(*args):
... print(args)
...
>>> numbers = [1, 2, 3, 4, 5]
>>> function(*numbers)
(1, 2, 3, 4, 5)
Here, the call function(*numbers) tells Python to unpack the numbers list and pass its items to the function as individual values. The *args parameter causes the values to be packed back into the tuple and stored in args.
You can even use the unpacking operator multiple times in a function call:
>>> numbers = [1, 2, 3, 4, 5]
>>> letters = ("a", "b", "b", "c")
>>> function(*numbers, *letters)
(1, 2, 3, 4, 5, 'a', 'b', 'b', 'c')
In this example, you unpack two sequences in the call to your toy function. All the values are packed into the args tuple as usual.
Unpacking Keyword Arguments
You can also unpack dictionaries in function calls. This is analogous to using iterable unpacking, as in the previous section. When you precede an argument with the dictionary unpacking operator (**) in a function call, you’re specifying that the argument is a dictionary that should be unpacked to keyword arguments:
>>> def function(one, two, three):
... print(f"{one = }")
... print(f"{two = }")
... print(f"{three = }")
...
>>> numbers = {"one": 1, "two": 2, "three": 3}
>>> function(**numbers)
one = 1
two = 2
three = 3
When you call the function in this example, the items in the numbers dictionary are unpacked and passed to function() as keyword arguments. So, this function call is equivalent to the following:
>>> function(one=numbers["one"], two=numbers["two"], three=numbers["three"])
one = 1
two = 2
three = 3
This time, you provide the arguments manually by using the dictionary values directly. This call is way more verbose and complex than the previous one.
Again, you can combine the dictionary unpacking operator (**) with the **kwargs syntax. You can also specify multiple dictionary unpackings in a function call:
>>> def function(**kwargs):
... for key, value in kwargs.items():
... print(key, "->", value)
...
>>> numbers = {"one": 1, "two": 2, "three": 3}
>>> letters = {"a": "A", "b": "B", "c": "C"}
>>> function(**numbers, **letters)
one -> 1
two -> 2
three -> 3
a -> A
b -> B
c -> C
In this example, you combine the **kwargs syntax in the function definition and the dictionary unpacking operator in the function call. You also use multiple dictionaries in the call, which is a great feature too.
Exploring Optional Features of Functions
Python allows you to add optional docstrings and annotations to your functions.
Docstrings are strings that you add at the beginning of a function to provide built-in documentation. They explain what a function does, what arguments it expects, and what it returns. Annotations let you optionally specify the expected types of arguments and return values, making your code clearer to readers and compatible with type-checking tools.
In this section, you’ll learn how to add and use both of these optional yet highly valuable features in your Python functions.
Docstrings
When the first statement in a function’s body is a string literal, it’s known as the function’s docstring.
You can use a docstring to supply quick documentation for a function. It can contain information about the function’s purpose, arguments, raised exceptions, and return values. It can also include basic examples of using the function and any other relevant information.
Note: For more on docstrings, check out the Documenting Python Code: A Complete Guide tutorial and How to Write Docstrings in Python.
Below is your average() showing a docstring in Google’s style and with doctest test examples:
def average(*args):
"""Calculate the average of given numbers.
Args:
*args (float or int): One or more numeric values.
Returns:
float: The arithmetic mean of the provided values.
Raises:
ZeroDivisionError: If no arguments are provided.
Examples:
>>> average(10, 20, 30)
20.0
>>> average(5, 15)
10.0
>>> average(7)
7.0
"""
return sum(args) / len(args)
Technically, docstrings can use any string quoting variant. However, the recommended and more common variant is to use triple quotes using double quote characters ("""), as shown above. If the docstring fits on one line, then the closing quotes should be on the same line as the opening quotes.
Multiline docstrings are used for lengthier documentation. A multiline docstring should consist of a summary line ending in a dot, a blank line, and finally, a detailed description. The closing quotes should be on a line by themselves.
Note: Docstring formatting and semantic conventions are detailed in PEP 257.
In the example above, you’ve used Google’s docstring style, which includes a description of the function’s arguments and return value. You’ve also used doctest examples. These examples mimic a REPL session and allow you to provide a quick reference for how to use the function. They can also serve as tests that you can run with the doctest module from the standard library.
When a docstring is defined, Python assigns it to a special function attribute called .__doc__. You can access a function’s docstring as shown below:
>>> print(average.__doc__)
Calculate the average of given numbers.
Args:
*args (float or int): One or more numeric values.
Returns:
float: The arithmetic mean of the provided values.
Raises:
ZeroDivisionError: If no arguments are provided.
Examples:
>>> average(10, 20, 30)
20.0
>>> average(5, 15)
10.0
>>> average(7)
7.0
The .__doc__ attribute gives you access to the docstring of any Python function that has one. Alternatively, you can run help(function_name) to display the docstring for the target function, which is the recommended practice.
Specifying a docstring for each Python function you define is considered best coding practice. Nowadays, you can take advantage of large language models (LLMs) and chatbots like ChatGPT to help document your code. However, always review and tailor the generated text to ensure it accurately describes your code and follows your project’s conventions.
Annotations
Function annotations provide a way to attach metadata to a function’s arguments and return value.
To add annotations to a function’s arguments, you use a colon (:) followed by the desired metadata after the argument in the function definition. Similarly, to provide annotations for the return value, add the arrow characters (->) and the desired metadata between the closing parentheses and the colon that terminates the function header.
In practice, annotations are widely used to provide type hints for arguments and return values. Here’s the general syntax for this:
def function(arg_0: <type>, arg_1: <type>, ..., arg_n: <type>) -> <type>:
<block>
Each argument’s data type could be any built-in data type, a custom type or class, or any combination of existing types. Note that Python doesn’t enforce type hints at runtime. They’re just type-related metadata that you, other developers, or an automated tool can inspect to have additional information about the function itself.
Consider the following toy function:
>>> def function(a: int, b: str) -> float:
... print(type(a), type(b))
... return 1, 2, 3
...
>>> function("Hello!", 123)
<class 'str'> <class 'int'>
(1, 2, 3)
What’s going on in this example? The annotations for function() indicate that the first argument should be an int, the second argument a str, and the return value a float. However, the call to function() ignores all those expected types. The arguments are a str and an int, respectively, and the return value is a tuple. Yet the interpreter lets it all slide without a single complaint.
Annotations don’t impose any restrictions on the code whatsoever. They’re metadata attached to the function through a dictionary called .__annotations__. This dictionary is available as an attribute of function objects:
>>> function.__annotations__
{'a': <class 'int'>, 'b': <class 'str'>, 'return': <class 'float'>}
Even though Python doesn’t do anything to ensure that the arguments and return values are of the declared data types, type hints can be pretty useful.
If you use annotations to add type hints to your functions, then you can use a static type checker, like mypy, to detect potential type-related errors in your code before you run it in production. This way, you can fix potential type errors that can cause issues at runtime, making your code more robust and reliable.
Note: To dive deeper into annotations, type hints, and type checking, take a look at the following tutorials:
To illustrate how type hints can help improve your code’s quality, say that you write the following function and expect it to be used with numeric arguments:
>>> def add(a, b):
... return a + b
...
>>> add(3, 4)
7
This function takes two numbers and adds them together. That’s pretty straightforward. Now, say that you pack this function with a bunch of other related functions in a library and make it available for people to use it freely. One of your users could do something like this, and think that your function is wrong:
>>> add("3", "4")
'34'
In this example, the function was called with two strings. Internally, the plus operator (+) concatenates the strings and produces a new string, "34". This isn’t the expected result. Of course, the reason is that the provided arguments aren’t of the correct data type, but because you didn’t provide type hints, the user could think that the function would work with strings too.
Here’s the type-hinted version:
>>> type Number = int | float
>>> def add(a: Number, b: Number) -> Number:
... return a + b
...
In this version of add(), you use type hints to express that the function should take numeric values of either int or float types. You also specify that the function can return an integer or a floating-point number. To make the code cleaner, you use a type alias, Number, that represents integer or floating-point values.
As you know, you can still call this function with two string arguments. However, a static type checker will warn you that the function is being used in an unexpected way.
Static type checkers are often integrated into modern code editors and integrated development environments (IDEs). So, your editor will probably automatically highlight the call add("3", "4") as something that can cause issues at runtime.
You can also run a static type checker on your code from the command line. For example, say that you have the code in a script like the following:
calculations.py
1def add(a: int | float, b: int | float) -> int | float:
2 return a + b
3
4add("3", "4")
To run mypy on this file, the first step is to install it in your environment. Once you have, you can run the following command:
$ mypy calculations.py
calculations.py:4: error: Argument 1 to "add" has incompatible type "str";
⮑ expected "int | float" [arg-type]
calculations.py:4: error: Argument 2 to "add" has incompatible type "str";
⮑ expected "int | float" [arg-type]
Found 2 errors in 1 file (checked 1 source file)
As you can see, the static type checker detects two possible errors in the function call. Both arguments have a type that doesn’t match the expected type. With this information, you can go back to your code and fix the function call using numeric values instead of strings.
You can use annotations for other purposes apart from type hinting. For example, you can use a dictionary to attach multiple items of metadata to function arguments and the return value:
>>> def rectangle_area(
... width: {"description": "Width of rectangle", "type": float},
... height: {"description": "Height of rectangle", "type": float},
... ) -> {"description": "Area of rectangle", "type": float}:
... return width * height
...
>>> rectangle_area.__annotations__
{
'width': {'description': 'Width of rectangle', 'type': <class 'float'>},
'height': {'description': 'Height of rectangle', 'type': <class 'float'>},
'return': {'description': 'Area of rectangle', 'type': <class 'float'>}
}
In this example, you attach annotations to the width and height parameters and also to the function’s return value. Each annotation is a dictionary containing a description and the expected data type for the object at hand.
Note: You can use any valid Python expression as an annotation, not just a dictionary or a data type. To learn more about expressions, check out Expression vs Statement in Python: What’s the Difference?
Again, even though it’s possible to use annotations to attach any metadata to a function’s arguments and return value, the most common and generalized use case of annotations is to provide type hints. A modern static type checker will expect you to do this in your Python code.
For example, if you run mypy on the code above, then you’ll get errors saying something like: Invalid type comment or annotation. However, Python won’t complain at all.
Taking a Quick Look at Asynchronous Functions
Python supports asynchronous programming with a few tools, including the asyncio module and the async and await keywords. Asynchronous code allows you to handle multiple tasks concurrently without blocking the execution of your main program.
This programming paradigm lets you write more efficient and responsive code, especially for I/O-bound tasks, such as network operations or file reading, where the main program would be idle while waiting for data.
Note: To dive deeper into asynchronous programming in Python, check out the following tutorials:
At the heart of asynchronous programming in Python are coroutine functions, which you can define with the async keyword:
async def function_name([parameters]):
<block>
This type of function returns a coroutine object, which can be entered, exited, and resumed at many different points. This object can pass the control back to an event loop, unblocking the main program, which can run other tasks in the meantime.
Calling an async function directly isn’t the way to go. However, the example below is intended to show that they return a coroutine object:
>>> async def get_number():
... return 42
...
>>> get_number()
<coroutine object get_number at 0x10742a8d0>
As you can see, the function returns a coroutine object instead of the number 42. What’s the correct or expected way to use this function? You can await it inside another coroutine function or run it directly in an event loop.
Here’s an example that follows the latter path:
>>> import asyncio
>>> async def get_number():
... return 42
...
>>> asyncio.run(get_number())
42
The asyncio.run() function starts an event loop that runs your coroutine function. This way, you get the actual return value, 42.
Even though this code works, it doesn’t take advantage of asynchronous programming because the function runs synchronously from start to finish without yielding control back to the event loop. The issue is that there’s typically little advantage in making a function async if it doesn’t await anything. To await something, you can use the await keyword.
The following example simulates a situation where you’re retrieving data from the network using asynchronous code:
>>> import asyncio
>>> async def fetch_data():
... print("Fetching data from the server...")
... await asyncio.sleep(1) # Simulate network delay
... print("Data received!")
... return {"user": "john", "status": "active"}
...
>>> async def main():
... data = await fetch_data()
... print(f"Received data: {data}")
...
>>> asyncio.run(main())
Fetching data from the server...
Data received!
Received data: {'user': 'john', 'status': 'active'}
In this example, you define an async function that simulates fetching user data from a network. The highlighted line introduces the await statement with asyncio.sleep(1) as the target awaitable object. This statement simulates a network delay of one second. In the meantime, the control returns to the event loop, which could perform other asynchronous tasks.
The main() function is the entry point to your code, so you can run it in the event loop with run(). Note that fetch_data() is also awaitable because it’s an async function.
Conclusion
You’ve learned about Python functions, which are essential for creating reusable and modular code. You’ve learned how to define functions using the def keyword, call them with appropriate arguments, and return values to the calling environment.
Additionally, you’ve explored more advanced features such as keyword arguments, default argument values, and techniques for handling a variable number of arguments. You also delved into the importance of documenting functions with docstrings and using annotations for type hints.
Understanding functions is crucial for any Python developer, as they promote code reusability, modularity, and maintainability.
In this tutorial, you’ve learned how to:
- Define and call Python functions effectively
- Use positional and keyword arguments to pass data
- Return values and handle side effects within functions
- Document functions with docstrings and enhance code with annotations
Now that you have these skills, you’re ready to write modular and clean Python code. You can confidently tackle more complex projects, knowing how to break them down into manageable, reusable functions.
Get Your Code: Click here to download the free sample code that shows you how to define your own function in Python.
Frequently Asked Questions
Now that you have some experience with Python functions, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
A function in Python is a named block of code that performs a specific task, which you can call and reuse in different parts of your code.
You use functions in Python to promote code reusability, modularity, and maintainability by encapsulating repetitive code in a single callable unit.
You define a Python function using the def keyword, followed by the function name, parentheses with optional arguments, a colon, and an indented code block.
To call a Python function, write its name followed by a pair of parentheses. Inside the parentheses, include any required arguments to execute the function’s code block.
Take the Quiz: Test your knowledge with our interactive “Defining Your Own Python Function” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Defining Your Own Python FunctionIn this quiz, you'll test your understanding of defining and calling Python functions. You'll revisit the def keyword, parameters, arguments, and more.







