Linear algebra is an important topic across a variety of subjects. It allows you to solve problems related to vectors, matrices, and linear equations. In Python, most of the routines related to this subject are implemented in scipy.linalg, which offers very fast linear algebra capabilities.
In particular, linear models play an important role in a variety of real-world problems, and scipy.linalg provides tools to compute them in an efficient way.
In this tutorial, you’ll learn how to:
- Study linear systems using determinants and solve problems using matrix inverses
- Interpolate polynomials to fit a set of points using linear systems
- Use Python to solve linear regression problems
- Use linear regression to predict prices based on historical data
This is the second part of a series of tutorials on linear algebra using scipy.linalg. So, before continuing, make sure to take a look at the first tutorial of the series before reading this one.
Free Source Code: Click here to download the free code and dataset that you’ll use to work with linear systems and algebra in Python with scipy.linalg.
Now you’re ready to get started!
Getting Started With Linear Algebra in Python
Linear algebra is a branch of mathematics that deals with linear equations and their representations using vectors and matrices. It’s a fundamental subject in several areas of engineering, and it’s a prerequisite to a deeper understanding of machine learning.
To work with linear algebra in Python, you can count on SciPy, which is an open-source Python library used for scientific computing, including several modules for common tasks in science and engineering.
Of course, SciPy includes modules for linear algebra, but that’s not all. It also offers optimization, integration, interpolation, and signal processing capabilities. It’s part of the SciPy stack, which includes several other packages for scientific computing, such as NumPy, Matplotlib, SymPy, IPython, and pandas.
scipy.linalg includes several tools for working with linear algebra problems, including functions for performing matrix calculations, such as determinants, inverses, eigenvalues, eigenvectors, and the singular value decomposition.
In the previous tutorial of this series, you learned how to work with matrices and vectors in Python to model practical problems using linear systems. You solved these problems using scipy.linalg.
In this tutorial, you’re going a step further, using scipy.linalg to study linear systems and build linear models for real-world problems.
In order to use scipy.linalg, you have to install and set up the SciPy library. Besides that, you’re going to use Jupyter Notebook to run the code in an interactive environment. SciPy and Jupyter Notebook are third-party packages that you need to install. For installation, you can use the conda or pip package manager. Revisit Working With Linear Systems in Python With scipy.linalg for installation details.
Note: Using Jupyter Notebook to run the code isn’t mandatory, but it facilitates working with numerical and scientific applications.
For a refresher on working with Jupyter Notebooks, take a look at Jupyter Notebook: An Introduction.
Next, you’ll go through some fundamental concepts of linear algebra and explore how to use Python to work with these concepts.
Understanding Vectors, Matrices, and the Role of Linear Algebra
A vector is a mathematical entity used to represent physical quantities that have both magnitude and direction. It’s a fundamental tool for solving engineering and machine learning problems. So are matrices, which are used to represent vector transformations, among other applications.
Note: In Python, NumPy is the most used library for working with matrices and vectors. It uses a special type called ndarray to represent them. As an example, imagine that you need to create the following matrix:
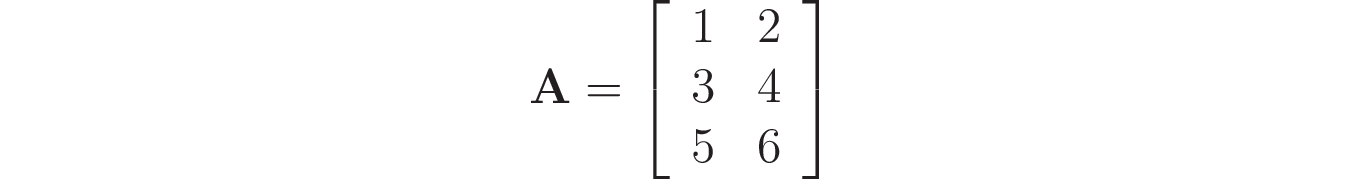
With NumPy, you can use np.array() to create it, providing a nested list containing the elements of each row of the matrix:
In [1]: import numpy as np
In [2]: np.array([[1, 2], [3, 4], [5, 6]])
Out[2]:
array([[1, 2],
[3, 4],
[5, 6]])
NumPy provides several functions to facilitate working with vector and matrix computations. You can find more information on how to use NumPy to represent vectors and matrices and perform operations with them in the previous tutorial in this series.
A linear system or, more precisely, a system of linear equations, is a set of equations linearly relating to a set of variables. Here’s an example of a linear system relating to the variables x₁ and x₂:
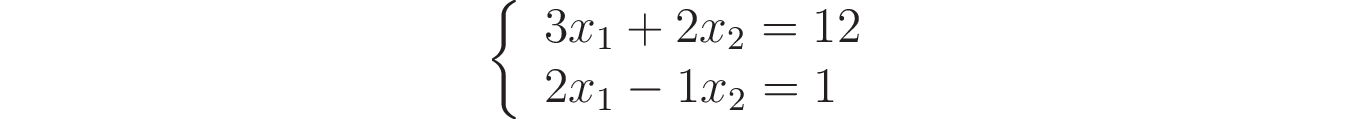
Here you have two equations involving two variables. In order to have a linear system, the values that multiply the variables x₁ and x₂ must be constants, like the ones in this example. It’s common to write linear systems using matrices and vectors. For example, you can write the previous system as the following matrix product:
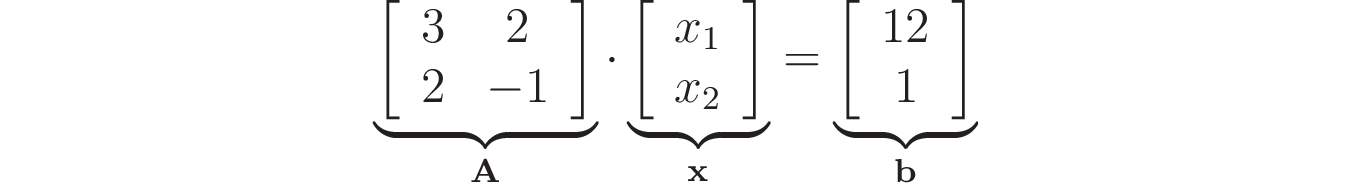
Comparing the matrix product form with the original system, you can notice the elements of matrix A correspond to the coefficients that multiply x₁ and x₂. Besides that, the values in the right-hand side of the original equations now make up vector b.
Linear algebra is a mathematical discipline that deals with vectors, matrices, and vector spaces and linear transformations more generally. By using linear algebra concepts, it’s possible to build algorithms to perform computations for several applications, including solving linear systems.
When there are just two or three equations and variables, it’s feasible to perform the calculations manually, combine the equations, and find the values for the variables.
However, in real-world applications, the number of equations can be very large, making it infeasible to do calculations manually. That’s precisely when linear algebra concepts and algorithms come handy, allowing you to develop usable applications for engineering and machine learning, for example.
In Working With Linear Systems in Python With scipy.linalg, you’ve seen how to solve linear systems using scipy.linalg.solve(). Now you’re going to learn how to use determinants to study the possible solutions and how to solve problems using the concept of matrix inverses.
Solving Problems Using Matrix Inverses and Determinants
Matrix inverses and determinants are tools that allow you to get some information about the linear system and also to solve it. Before going through the details on how to calculate matrix inverses and determinants using scipy.linalg, take some time to remember how to use these structures.
Using Determinants to Study Linear Systems
As you may recall from your math classes, not every linear system can be solved. You may have a combination of equations that’s inconsistent and has no solution. For example, a system with two equations given by x₁ + x₂ = 2 and x₁ + x₂ = 3 is inconsistent and has no solution. This happens because no two numbers x₁ and x₂ can add up to both 2 and 3 at the same time.
Besides that, some systems can be solved but have more than one solution. For example, if you have a system with two equivalent equations, such as x₁ + x₂ = 2 and 2x₁ + 2x₂ = 4, then you can find an infinite number of solutions, such as (x₁=1, x₂=1), (x₁=0, x₂=2), (x₁=2, x₂=0), and so on.
A determinant is a number, calculated using the matrix of coefficients, that tells you if there’s a solution for the system. Because you’ll be using scipy.linalg to calculate it, you don’t need to care much about the details on how to make the calculation. However, keep the following in mind:
- If the determinant of a coefficients matrix of a linear system is different from zero, then you can say the system has a unique solution.
- If the determinant of a coefficients matrix of a linear system is equal to zero, then the system may have either zero solutions or an infinite number of solutions.
Now that you have this in mind, you’ll learn how to solve linear systems using matrices.
Using Matrix Inverses to Solve Linear Systems
To understand the idea behind the inverse of a matrix, start by recalling the concept of the multiplicative inverse of a number. When you multiply a number by its inverse, you get 1 as the result. Take 3 as an example. The inverse of 3 is 1/3, and when you multiply these numbers, you get 3 × 1/3 = 1.
With square matrices, you can think of a similar idea. However, instead of 1, you’ll get an identity matrix as the result. An identity matrix has ones in its diagonal and zeros in the elements outside of the diagonal, like the following examples:
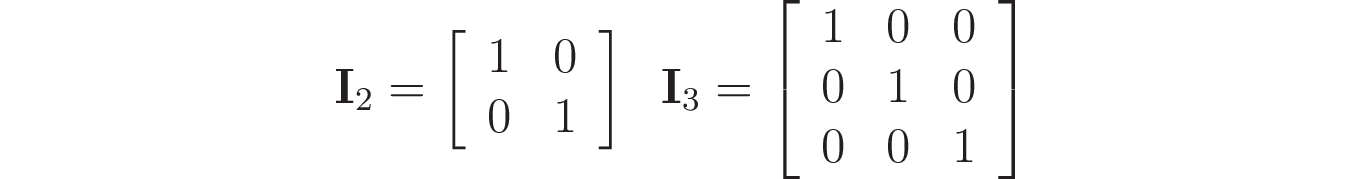
The identity matrix has an interesting property: when multiplied by another matrix A of the same dimensions, the obtained result is A. Recall that this is also true for the number 1, when you consider the multiplication of numbers.
This allows you to solve a linear system by following the same steps used to solve an equation. As an example, consider the following linear system, written as a matrix product:
By calling A⁻¹ the inverse of matrix A, you could multiply both sides of the equation by A⁻¹, which would give you the following result:
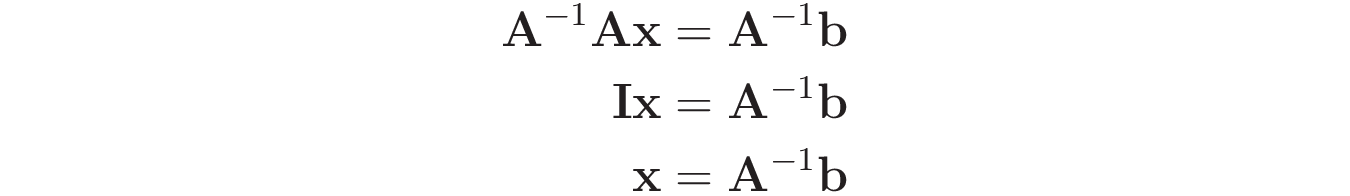
This way, by using the inverse, A⁻¹, you can obtain the solution x for the system by calculating A⁻¹b.
It’s worth noting that while non-zero numbers always have an inverse, not all matrices have an inverse. When the system has no solution or when it has multiple solutions, the determinant of A will be zero, and the inverse, A⁻¹, won’t exist.
Now you’ll see how to use Python with scipy.linalg to make these calculations.
Calculating Inverses and Determinants With scipy.linalg
You can calculate matrix inverses and determinants using scipy.linalg.inv() and scipy.linalg.det().
For example, consider the meal plan problem that you worked on in the previous tutorial of this series. Recall that the linear system for this problem could be written as a matrix product:

Previously, you used scipy.linalg.solve() to obtain the solution 10, 10, 20, 20, 10 for the variables x₁ to x₅, respectively. But as you’ve just learned, it’s also possible to use the inverse of the coefficients matrix to obtain vector x, which contains the solutions for the problem. You have to calculate x = A⁻¹b, which you can do with the following program:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array(
5 ...: [
6 ...: [1, 9, 2, 1, 1],
7 ...: [10, 1, 2, 1, 1],
8 ...: [1, 0, 5, 1, 1],
9 ...: [2, 1, 1, 2, 9],
10 ...: [2, 1, 2, 13, 2],
11 ...: ]
12 ...: )
13
14In [3]: b = np.array([170, 180, 140, 180, 350]).reshape((5, 1))
15
16In [4]: A_inv = linalg.inv(A)
17
18In [5]: x = A_inv @ b
19 ...: x
20Out[5]:
21array([[10.],
22 [10.],
23 [20.],
24 [20.],
25 [10.]])
Here’s a breakdown of what’s happening:
-
Lines 1 and 2 import NumPy as
np, along withlinalgfromscipy. These imports allow you to uselinalg.inv(). -
Lines 4 to 12 create the coefficients matrix as a NumPy array called
A. -
Line 14 creates the independent terms vector as a NumPy array called
b. To make it a column vector with five elements, you use.reshape((5, 1)). -
Line 16 uses
linalg.inv()to obtain the inverse of matrixA. -
Lines 18 and 19 use the
@operator to perform the matrix product in order to solve the linear system characterized byAandb. You store the result inx, which is printed.
You get exactly the same solution as the one provided by scipy.linalg.solve(). Because this system has a unique solution, the determinant of matrix A must be different from zero. You can confirm that it is by calculating it using det() from scipy.linalg:
In [6]: linalg.det(A)
Out[6]:
45102.0
As expected, the determinant isn’t zero. This indicates that the inverse of A, denoted as A⁻¹ and calculated with inv(A), exists, so the system has a unique solution. A⁻¹ is a square matrix with the same dimensions as A, so the product of A⁻¹ and A results in an identity matrix. In this example, it’s given by the following:
In [7]: A_inv
Out[7]:
array([[-0.01077558, 0.10655847, -0.03565252, -0.0058534 , -0.00372489],
[ 0.11287748, -0.00512172, -0.04010909, -0.00658507, -0.0041905 ],
[ 0.0052991 , -0.01536517, 0.21300608, -0.01975522, -0.0125715 ],
[-0.0064077 , -0.01070906, -0.02325839, -0.01376879, 0.08214713],
[-0.00931223, -0.01902355, -0.00611946, 0.1183983 , -0.01556472]])
Now that you know the basics of using matrix inverses and determinants, you’ll see how to use these tools to find the coefficients of polynomials.
Interpolating Polynomials With Linear Systems
You can use linear systems to calculate polynomial coefficients so that these polynomials include some specific points.
For example, consider the second-degree polynomial y = P(x) = a₀ + a₁x + a₂x². Recall that when you plot a second-degree polynomial, you get a parabola, which will be different depending on the coefficients a₀, a₁, and a₂.
Now, suppose that you’d like to find a specific second-degree polynomial that includes the (x, y) points (1, 5), (2, 13), and (3, 25). How could you calculate a₀, a₁, and a₂, such that P(x) includes these points in its parabola? In other words, you want to find the coefficients of the polynomial in this figure:
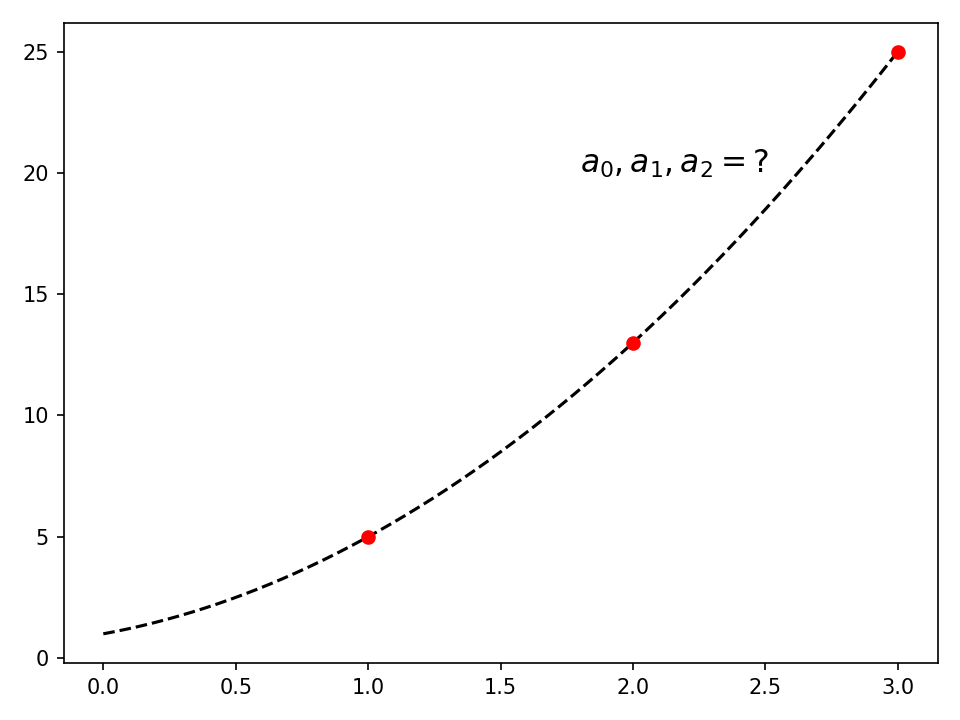
For each point that you’d like to include in the parabola, you can use the general expression of the polynomial in order to get a linear equation. For example, taking the second point, (x=2, y=13), and considering that y = a₀ + a₁x + a₂x², you could write the following equation:
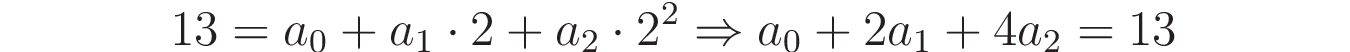
This way, for each point (x, y), you’ll get an equation involving a₀, a₁, and a₂. Because you’re considering three different points, you’ll end up with a system of three equations:
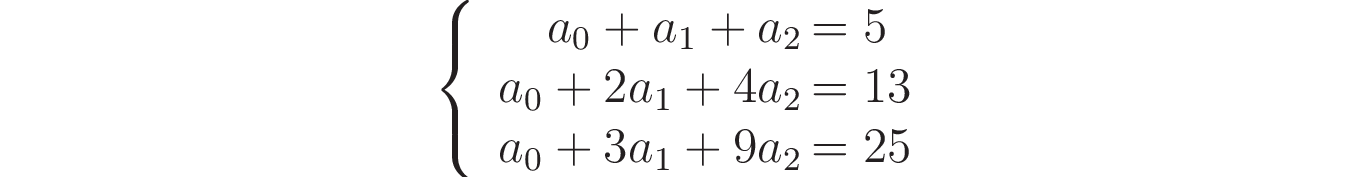
To check if this system has a unique solution, you can calculate the determinant of the coefficients matrix and check if it’s not zero. You can do that with the following code:
In [1]: import numpy as np
...: from scipy import linalg
In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 3, 9]])
In [3]: linalg.det(A)
Out[3]:
1.9999999999999996
It’s worth noting that the existence of the solution only depends on A. Because the value of the determinant isn’t zero, you can be sure that there’s a unique solution for the system. You can solve it using the matrix inverse method with the following code:
In [4]: b = np.array([5, 13, 25]).reshape((3, 1))
In [5]: a = linalg.inv(A) @ b
...: a
Out[5]:
array([[1.],
[2.],
[2.]])
This result tells you that a₀ = 1, a₁ = 2, and a₂ = 2 is a solution for the system. In other words, the polynomial that includes the points (1, 5), (2, 13), and (3, 25) is given by y = P(x) = 1 + 2x + 2x². You can test the solution for each point by inputting x and verifying that P(x) is equal to y.
As an example of a system without any solution, say that you’re trying to interpolate a parabola with the (x, y) points given by (1, 5), (2, 13), and (2, 25). If you look carefully at these numbers, you’ll notice that the second and third points consider x = 2 and different values for y, which makes it impossible to find a function that includes both points.
Following the same steps as before, you’ll arrive at the equations for this system, which are the following:
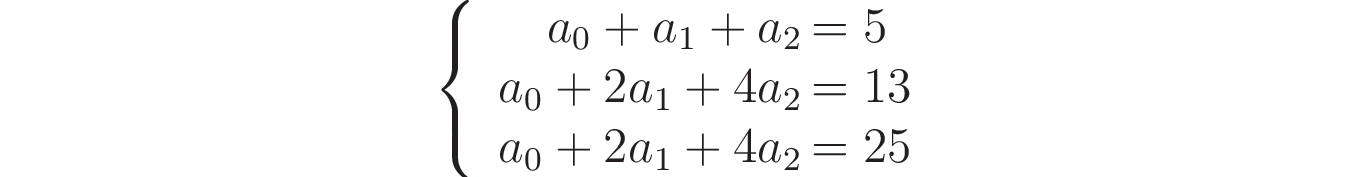
To confirm that this system doesn’t present a unique solution, you can calculate the determinant of the coefficients matrix with the following code:
In [6]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
...: linalg.det(A)
Out[6]:
0.0
You may notice that the value of the determinant is zero, which means that the system doesn’t have a unique solution. This also means that the inverse of the coefficients matrix doesn’t exist. In other words, the coefficients matrix is singular.
Depending on your computer architecture, you may get a very small number instead of zero. This happens due to the numerical algorithms that det() uses to calculate the determinant. In these algorithms, numeric precision errors make this result not exactly equal to zero.
In general, whenever you come across a tiny number, you can conclude that the system doesn’t have a unique solution.
You can try to solve the linear system using the matrix inverse method with the following code:
In [7]: b = np.array([5, 13, 25]).reshape((3, 1))
In [8]: x = linalg.inv(A) @ b
---------------------------------------------------------------------------
LinAlgError Traceback (most recent call last)
<ipython-input-10-e6ee9b06a6fe> in <module>
----> 1 x = linalg.inv(A) @ b
LinAlgError: singular matrix
Because the system has no solution, you get an exception telling you that the coefficients matrix is singular.
When the system has more than one solution, you’ll come across a similar result. The value of the determinant of the coefficients matrix will be zero or very small, indicating that the coefficients matrix again is singular.
As an example of a system with more than one solution, you can try to interpolate a parabola considering the points (x, y) given by (1, 5), (2, 13), and (2, 13). As you may notice, here you’re considering two points at the same position, which allows an infinite number of solutions for a₀, a₁, and a₂.
Now that you’ve gone through how to work with polynomial interpolation using linear systems, you’ll see another technique that makes an effort to find the coefficients for any set of points.
Minimizing Error With Least Squares
You’ve seen that sometimes you can’t find a polynomial that fits precisely to a set of points. However, usually when you’re trying to interpolate a polynomial, you’re not interested in a precise fit. You’re just looking for a solution that approximates the points, providing the minimum error possible.
This is generally the case when you’re working with real-world data. Usually, it includes some noise caused by errors that occur in the collecting process, like imprecision or malfunction in sensors, and typos when users are inputting data manually.
Using the least squares method, you can find a solution for the interpolation of a polynomial, even when the coefficients matrix is singular. By using this method, you’ll be looking for the coefficients of the polynomial that provides the minimum squared error when comparing the polynomial curve to your data points.
Actually, the least squares method is generally used to fit polynomials to large sets of data points. The idea is to try to design a model that represents some observed behavior.
Note: If a linear system has a unique solution, then the least squares solution will be equal to that unique solution.
For example, you could design a model to try to predict car prices. For that, you could collect some real-world data, including the car price and some other features like the mileage, the year, and the type of car. With this data, you can design a polynomial that models the price as a function of the other features and use least squares to find the optimal coefficients of this model.
Soon, you’re going to work on a model to address this problem. But first, you’re going to see how to use scipy.linalg to build models using least squares.
Building Least Squares Models Using scipy.linalg
To solve least squares problems, scipy.linalg provides a function called lstsq(). To see how it works, consider the previous example, in which you tried to fit a parabola to the points (x, y) given by (1, 5), (2, 13), and (2, 25). Remember that this system has no solution, since there are two points with the same value for x.
Just like you did before, using the model y = a₀ + a₁x + a₂x², you arrive at the following linear system:
Using the least squares method, you can find a solution for the coefficients a₀, a₁, and a₂ that provides a parabola that minimizes the squared difference between the curve and the data points. For that, you can use the following code:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
5 ...: b = np.array([5, 13, 25]).reshape((3, 1))
6
7In [3]: p, *_ = linalg.lstsq(A, b)
8 ...: p
9Out[3]:
10array([[-0.42857143],
11 [ 1.14285714],
12 [ 4.28571429]])
In this program, you’ve set up the following:
-
Lines 1 to 2: You import
numpyasnpandlinalgfromscipyin order to uselinalg.lstsq(). -
Lines 4 to 5: You create the coefficients matrix A using a NumPy array called
Aand the vector with the independent terms b using a NumPy array calledb. -
Line 7: You calculate the least squares solution for the problem using
linalg.lstsq(), which takes the coefficients matrix and the vector with the independent terms as input.
lstsq() provides several pieces of information about the system, including the residues, rank, and singular values of the coefficients matrix. In this case, you’re interested only in the coefficients of the polynomial to solve the problem according to the least squares criteria, which are stored in p.
As you can see, even considering a linear system that has no exact solution, lstsq() provides the coefficients that minimize the squared errors. With the following code, you can visualize the solution provided by plotting the parabola and the data points:
1In [4]: import matplotlib.pyplot as plt
2
3In [5]: x = np.linspace(0, 3, 1000)
4 ...: y = p[0] + p[1] * x + p[2] * x ** 2
5
6In [6]: plt.plot(x, y)
7 ...: plt.plot(1, 5, "ro")
8 ...: plt.plot(2, 13, "ro")
9 ...: plt.plot(2, 25, "ro")
This program uses matplotlib to plot the results:
-
Line 1: You import
matplotlib.pyplotasplt, which is typical. -
Lines 3 to 4: You create a NumPy array named
x, with values ranging from0to3, containing1000points. You also create a NumPy array namedywith the corresponding values of the model. -
Line 6: You plot the curve for the parabola obtained with the model given by the points in the arrays
xandy. -
Lines 7 to 9: In red (
"ro"), you plot the three points used to build the model.
The output should be the following figure:
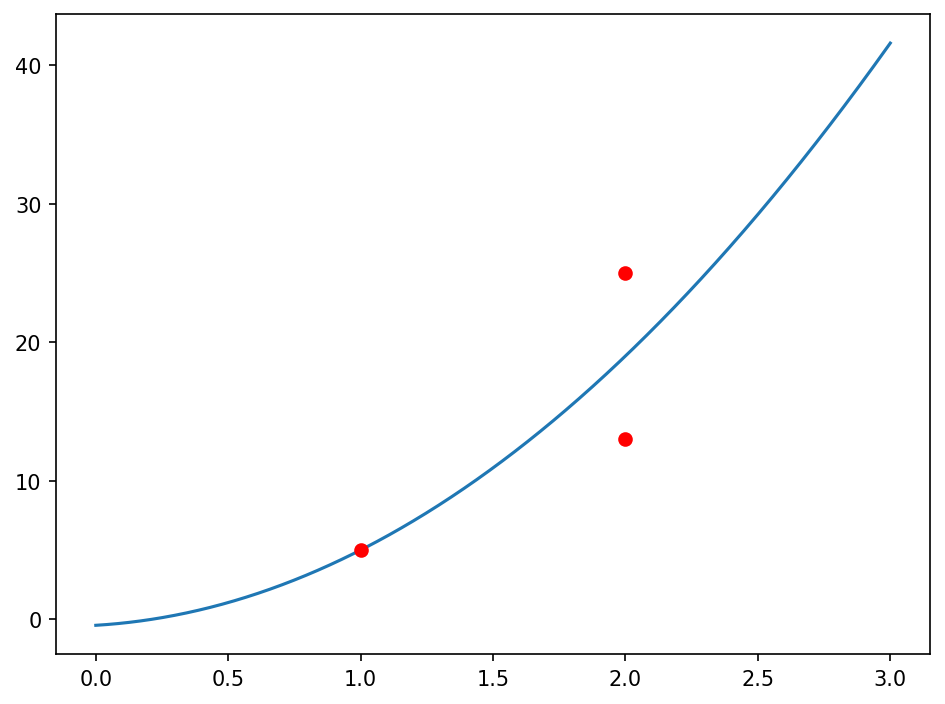
Notice how the curve provided by the model tries to approximate the points as well as possible.
Besides lstsq(), there are other ways to calculate least squares solutions using SciPy. One of the alternatives is using a pseudoinverse, which you’ll explore next.
Obtaining Least Squares Solutions Using a Pseudoinverse
Another way to compute the least squares solution is by using the Moore-Penrose pseudoinverse of a matrix.
You can think of a pseudoinverse as a generalization of the matrix inverse, as it’s equal to the usual matrix inverse when the matrix isn’t singular.
However, when the matrix is singular, which is the case in linear systems that lack a unique solution, then the pseudoinverse computes the matrix that provides the best fit, leading to the least squares solution.
Using the pseudoinverse, you can find the coefficients for the parabola used in the previous example:
1In [1]: import numpy as np
2 ...: from scipy import linalg
3
4In [2]: A = np.array([[1, 1, 1], [1, 2, 4], [1, 2, 4]])
5 ...: b = np.array([5, 13, 25]).reshape((3, 1))
6
7In [3]: A_pinv = linalg.pinv(A)
8
9In [4]: p2 = A_pinv @ b
10 ...: p2
11Out[4]:
12array([[-0.42857143],
13 [ 1.14285714],
14 [ 4.28571429]])
This code is very similar to the code from the previous section, except for the highlighted lines:
-
Line 7: You calculate the pseudoinverse of the coefficients matrix and store it in
A_pinv. -
Line 9: Following the same approach used to solve linear systems with the inverse of a matrix, you calculate the coefficients of the parabola equation using the pseudoinverse and store them in the vector
p2.
As you’d expect, the least squares solution is the same as the lstsq() solution. In this case, because A is a square matrix, pinv() will provide a square matrix with the same dimensions as A, optimizing for the best fit in the least squares sense:
In [5]: A_pinv
Out[5]:
array([[ 1. , -0.14285714, -0.14285714],
[ 0.5 , -0.03571429, -0.03571429],
[-0.5 , 0.17857143, 0.17857143]])
However, it’s worth noting that you can also calculate pinv() for non-square matrices, which is usually the case in practice. You’ll dive into that next, with an example using real-world data.
Example: Predicting Car Prices With Least Squares
In this example, you’re going to build a model using least squares to predict the price of used cars using the data from the Used Cars Dataset. This dataset is a huge collection with 957 MB of vehicle listings from craigslist.org, including very different types of vehicles.
When working with real data, it’s often necessary to perform some steps of filtering and cleaning in order to use the data to build a model. In this case, it’s necessary to narrow down the types of vehicles that you’ll include, in order to get better results with your model.
Since your main focus here is on using least squares to build the model, you’ll start with a cleaned dataset, which is a small subset from the original one. Before you start working on the code, get the cleaned data CSV file by clicking the link below and navigating to vehicles_cleaned.csv:
Free Source Code: Click here to download the free code and dataset that you’ll use to work with linear systems and algebra in Python with scipy.linalg.
In the downloadable materials, you can also check out the Jupyter Notebook to learn more about data preparation.
Preparing the Data
To load the CSV file and process the data, you’ll use pandas. So, make sure to install it in the conda environment linalg as follows:
(linalg) $ conda install pandas
After downloading the data and setting up pandas, you can start a new Jupyter Notebook and load the data by running the following code block:
In [1]: import pandas as pd
...: cars_data = pd.read_csv("vehicles_cleaned.csv")
This will create a pandas DataFrame named cars_data containing the data from the CSV file. From this DataFrame, you’ll generate the NumPy arrays that you’ll use as inputs to lstsq() and pinv() to obtain the least squares solution. To learn more on how to use pandas to process data, take a look at Using pandas and Python to Explore Your Dataset.
A DataFrame object includes an attribute named columns that allows you to consult the names of the columns included in the data. That means you can check the columns included in this dataset with the following code:
In [2]: cars_data.columns
Out[2]:
Index(['price', 'year', 'condition', 'cylinders', 'fuel', 'odometer',
'transmission', 'size', 'type'],
dtype='object')
You can take a look into one of the lines of the DataFrame using .iloc:
In [3]: cars_data.iloc[0]
Out[3]:
price 7000
year 2011
condition good
cylinders 4 cylinders
fuel gas
odometer 76202
transmission automatic
size compact
type sedan
Name: 0, dtype: object
As you can see, this dataset includes nine columns, with the following data:
| Column Name | Description |
|---|---|
price |
The price of the vehicle, which is the column that you want to predict with your model |
year |
The production year of the vehicle |
condition |
A categorical variable that can take the values good, fair, excellent, like new, salvage, or new |
cylinders |
A categorical variable that can take the values 4 cylinders or 6 cylinders |
fuel |
A categorical variable that can take the values gas or diesel |
odometer |
The mileage of the vehicle indicated by the odometer |
transmission |
A categorical variable that can take the values automatic or manual |
size |
A categorical value that can take the values compact, mid-size, sub-compact, or full-size |
type |
A categorical value that can take the values sedan, coupe, wagon, or hatchback |
To use this data to build a least squares model, you’ll need to represent the categorical data in a numeric way. In most cases, categorical data is transformed to a set of dummy variables, which are variables that can take a value of 0 or 1.
As an example of this transformation, consider the column fuel, which can take the value gas or diesel. You could transform this categorical column to a dummy column named fuel_gas that takes the value 1 when fuel is gas and 0 when fuel is diesel.
Note that you’ll need just one dummy column to represent a categorical column that can take two different values. Similarly, for a categorical column that can take N values, you’re going to need N-1 dummy columns, as one of the values will be assumed as the default.
In pandas, you can transform these categorical columns to dummy columns with get_dummies():
In [4]: cars_data_dummies = pd.get_dummies(
...: cars_data,
...: columns=[
...: "condition",
...: "cylinders",
...: "fuel",
...: "transmission",
...: "size",
...: "type",
...: ],
...: drop_first=True,
...: )
Here, you’re creating a new DataFrame named cars_data_dummies, which includes dummy variables for the columns specified in the columns argument. You can now check the new columns included in this DataFrame:
In [5]: cars_data_dummies.columns
Out[5]:
Index(['price', 'year', 'odometer', 'condition_fair', 'condition_good',
'condition_like new', 'condition_new', 'condition_salvage',
'cylinders_6 cylinders', 'fuel_gas', 'transmission_manual',
'size_full-size', 'size_mid-size', 'size_sub-compact', 'type_hatchback',
'type_sedan', 'type_wagon'],
dtype='object')
Now that you’ve transformed the categorical variables to sets of dummy variables, you can use this information to build your model. Basically, the model will include a coefficient for each of these columns—except price, which will be used as the model output. The price will be given by a weighted combination of the other variables, where the weights are given by the model’s coefficients.
However, it’s customary to consider an extra coefficient that represents a constant value that’s added to the weighted combination of the other variables. This coefficient is known as the intercept, and you can include it in your model by adding an extra column to the data, with all the rows equal to 1:
In [6]: cars_data_dummies["intercept"] = 1
Now that you have all the data organized, you can generate the NumPy arrays to build your model using scipy.linalg. That’s what you’ll do next.
Building the Model
To generate the NumPy arrays to input in lstsq() or pinv(), you can use .to_numpy():
In [7]: A = cars_data_dummies.drop(columns=["price"]).to_numpy()
...: b = cars_data_dummies.loc[:, "price"].to_numpy()
The coefficients matrix A is given by all the columns, except price. Vector b, with the independent terms, is given by the values that you want to predict, which is the price column in this case. With A and b set, you can use lstsq() to find the least squares solution for the coefficients:
In [8]: from scipy import linalg
In [9]: p, *_ = linalg.lstsq(A, b)
...: p
Out[9]:
array([ 8.47362988e+02, -3.53913729e-02, -3.47144752e+03, -1.66981155e+03,
-1.80240398e+02, -7.15885691e+03, -6.36540791e+03, 3.76583261e+03,
-1.84837210e+03, 1.31935783e+03, 6.60484388e+02, 6.38913933e+02,
1.54163679e+02, -1.76423109e+03, -1.99439766e+03, 6.97365788e+02,
-1.68998811e+06])
These are the coefficients that you should use to model price in terms of a weighted combination of the other variables in order to minimize the squared error. As you’ve seen, it’s also possible to get these coefficients by using pinv() with the following code:
In [10]: p2 = linalg.pinv(A) @ b
...: p2
Out[10]:
array([ 8.47362988e+02, -3.53913729e-02, -3.47144752e+03, -1.66981155e+03,
-1.80240398e+02, -7.15885691e+03, -6.36540791e+03, 3.76583261e+03,
-1.84837210e+03, 1.31935783e+03, 6.60484388e+02, 6.38913933e+02,
1.54163679e+02, -1.76423109e+03, -1.99439766e+03, 6.97365788e+02,
-1.68998811e+06])
One of the nice characteristics of a linear regression model is that it’s fairly easy to interpret. In this case, you can conclude from the coefficients that the value of the car increases approximately $847 as year increases by 1, which means that the value of the car decreases $847 per year of car age. Similarly, according to the second coefficient, the value of the car decreases approximately $35.39 per 1,000 miles.
Now that you’ve obtained the model, you’ll use it to predict the price of a car.
Predicting Prices
Using the model given by the least squares solution, you can predict the price for a car represented by a vector with the values for each of the variables used in the model:
In [11]: cars_data_dummies.drop(columns=["price"]).columns
Out[11]:
Index(['year', 'odometer', 'condition_fair', 'condition_good',
'condition_like new', 'condition_new', 'condition_salvage',
'cylinders_6 cylinders', 'fuel_gas', 'transmission_manual',
'size_full-size', 'size_mid-size', 'size_sub-compact', 'type_hatchback',
'type_sedan', 'type_wagon', 'intercept'],
dtype='object')
So, a 2010 4-cylinder hatchback, with automatic transmission, gas fuel, and 50,000 miles, in good condition, can be represented with the following vector:
In [12]: import numpy as np
...: car = np.array(
...: [2010, 50000, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1]
...: )
You can obtain the prediction of the price by calculating the dot product between the car vector and the vector p of the coefficients. Because both vectors are one-dimensional NumPy arrays, you can use @ to obtain the dot product:
In [13]: predicted_price = p @ car
...: predicted_price
Out[13]:
6159.510724281656
In this example, the predicted price for the hatchback is approximately $6,160. It’s worth noting that the model coefficients include some uncertainty because the data used to obtain the model could be biased toward a particular type of car, for example.
Besides that, the model choice plays a big role in the quality of the estimates. Least squares is one of the most-used techniques to build models because it’s simple and yields explainable models. In this example, you’ve seen how to use scipy.linalg to build such models. For more details on least squares models, take a look at Linear Regression in Python.
Conclusion
Congratulations! You’ve learned how to use some linear algebra concepts with Python to solve problems involving linear models. You’ve discovered that vectors and matrices are useful for representing data and that, by using linear systems, you can model practical problems and solve them in an efficient manner.
In this tutorial, you’ve learned how to:
- Study linear systems using determinants and solve problems using matrix inverses
- Interpolate polynomials to fit a set of points using linear systems
- Use Python to solve linear regression problems
- Use linear regression to predict prices based on historical data
Linear algebra is a very broad topic. For more information on some other linear algebra applications, check out the following resources:
- Working With Linear Systems in Python With
scipy.linalg - Scientific Python: Using SciPy for Optimization
- Hands-On Linear Programming: Optimization With Python
- NumPy, SciPy, and pandas: Correlation With Python
Keep studying, and feel free to leave any questions or comments below!
Free Source Code: Click here to download the free code and dataset that you’ll use to work with linear systems and algebra in Python with scipy.linalg.








