
Python 3.9 is here! Volunteers from all over the world have been working on improvements to Python for the past year. While beta versions have been available for some time, the first official version of Python 3.9 was released on October 5, 2020.
Every release of Python includes new, improved, and deprecated features, and Python 3.9 is no different. The documentation gives a complete list of the changes. Below, you’ll take an in-depth look at the coolest features that the latest version of Python brings to the table.
In this tutorial, you’ll learn about:
- Accessing and calculating with time zones
- Merging and updating dictionaries effectively
- Using decorators based on expressions
- Combining type hints and other annotations
To try out the new features yourself, you need to have Python 3.9 installed. You can download and install it from the Python home page. Alternatively, you can try it out using the official Docker image. See Run Python Versions in Docker: How to Try the Latest Python Release for more details.
Free Download: Get a sample chapter from Python Tricks: The Book that shows you Python’s best practices with simple examples you can apply instantly to write more beautiful + Pythonic code.
Bonus Learning Materials: Check out Real Python Podcast Episode #30 and this Office Hours recording with Python 3.9 tips and a panel discussion with members of the Real Python team.
Proper Time Zone Support
Python has extensive support for working with dates and times through the datetime module in the standard library. However, support for working with time zones has been somewhat lacking. Until now, the recommended way of working with time zones has been to use third-party libraries like dateutil.
The biggest challenge to working with time zones in plain Python has been that you’ve had to implement time zones rules yourself. A datetime supports setting time zones, but only UTC is immediately available. Other time zones need to be implemented on top of the abstract tzinfo base class.
Accessing Time Zones
You can get a UTC time stamp from the datetime library like this:
>>> from datetime import datetime, timezone
>>> datetime.now(tz=timezone.utc)
datetime.datetime(2020, 9, 8, 15, 4, 15, 361413, tzinfo=datetime.timezone.utc)
Note that the resulting time stamp is time zone aware. It has an attached time zone as specified by tzinfo. Time stamps without any time zone information are called naive.
Paul Ganssle has been the maintainer of dateutil for years. He joined the Python core developers in 2019 and helped add a new zoneinfo standard library that makes working with time zones much more convenient.
zoneinfo provides access to the Internet Assigned Numbers Authority (IANA) Time Zone Database. The IANA updates its database several times each year, and it’s the most authoritative source for time zone information.
Using zoneinfo, you can get an object describing any time zone in the database:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
zoneinfo.ZoneInfo(key='America/Vancouver')
You access a time zone using one of several keys. In this case, you use "America/Vancouver".
Note: zoneinfo uses an IANA time zone database residing on your local computer. It’s possible—on Windows in particular—that you don’t have any such database or that zoneinfo won’t be able to locate it. If you get an error like the following, then zoneinfo hasn’t been able to locate a time zone database:
>>> from zoneinfo import ZoneInfo
>>> ZoneInfo("America/Vancouver")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ZoneInfoNotFoundError: 'No time zone found with key America/Vancouver'
A Python implementation of the IANA Time Zone Database is available on PyPI as tzdata. You can install it with pip:
$ python -m pip install tzdata
Once tzdata is installed, zoneinfo should be able to read information about all supported time zones. tzdata is maintained by the Python core team. Note that you need to keep the package updated in order to have access to the latest changes in the IANA Time Zone Database.
You can make time zone–aware time stamps using the tz or tzinfo arguments to datetime functions:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> datetime.now(tz=ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 9, 8, 17, 12, 0, 939001,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
>>> datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
datetime.datetime(2020, 10, 5, 3, 9,
tzinfo=zoneinfo.ZoneInfo(key='America/Vancouver'))
Having the time zone recorded with the time stamp is great for record keeping. It also makes it convenient to convert between time zones:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=ZoneInfo("America/Vancouver"))
>>> release.astimezone(ZoneInfo("Europe/Oslo"))
datetime.datetime(2020, 10, 5, 12, 9,
tzinfo=zoneinfo.ZoneInfo(key='Europe/Oslo'))
Note that the time in Oslo is nine hours later than in Vancouver.
Investigating Time Zones
The IANA Time Zone Database is quite massive. You can list all available time zones using zoneinfo.available_timezones():
>>> import zoneinfo
>>> zoneinfo.available_timezones()
{'America/St_Lucia', 'SystemV/MST7', 'Asia/Aqtau', 'EST', ... 'Asia/Beirut'}
>>> len(zoneinfo.available_timezones())
609
The number of time zones in the database may vary with your installation. In this example, you can see that there are 609 time zone names listed. Each of these time zones documents historical changes that have happened, and you can look more closely at each of them.
Kiritimati, also known as Christmas Island, is currently in the westernmost time zone in the world, UTC+14. That hasn’t always been the case. Before 1995, the island was on the other side of the International Date Line, in UTC-10. In order to move across the date line, Kiritimati completely skipped December 31, 1994.
You can see how this happened by looking closer at the "Pacific/Kiritimati" time zone object:
>>> from datetime import datetime, timedelta
>>> from zoneinfo import ZoneInfo
>>> hour = timedelta(hours=1)
>>> tz_kiritimati = ZoneInfo("Pacific/Kiritimati")
>>> ts = datetime(1994, 12, 31, 9, 0, tzinfo=ZoneInfo("UTC"))
>>> ts.astimezone(tz_kiritimati)
datetime.datetime(1994, 12, 30, 23, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
>>> (ts + 1 * hour).astimezone(tz_kiritimati)
datetime.datetime(1995, 1, 1, 0, 0,
tzinfo=zoneinfo.ZoneInfo(key='Pacific/Kiritimati'))
The new year started one hour after the clock read 23:00 on December 30, 1994, on Kiritimati. December 31, 1994, never happened!
You can also see that the offset from UTC changed:
>>> tz_kiritimati.utcoffset(datetime(1994, 12, 30)) / hour
-10.0
>>> tz_kiritimati.utcoffset(datetime(1995, 1, 1)) / hour
14.0
.utcoffset() returns a timedelta. The most effective way to calculate how many hours are represented by a given timedelta is to divide it by a timedelta representing one hour.
There are many other weird stories about time zones. Paul Ganssle covers some of them in his PyCon 2019 presentation, Working With Time Zones: Everything You Wish You Didn’t Need to Know. See if you can find traces of any of the others in the Time Zone Database.
Using Best Practices
Working with time zones can be tricky. However, with the availability of zoneinfo in the standard library, it’s gotten a bit easier. Here are a few suggestions to keep in mind when working with dates and times:
-
Civil times like the time of a meeting, a train departure, or a concert, are best stored in their native time zone. You can often do this by storing a naive time stamp together with the IANA key of the time zone. One example of a civil time stored as a string would be
"2020-10-05T14:00:00,Europe/Oslo". Having information about the time zone ensures that you can always recover the information, even if the time zones themselves change. -
Time stamps represent specific moments in time and typically record an order of events. Computer logs are an example of this. You don’t want your logs to be jumbled up just because your time zone changes from Daylight Saving Time to standard time. Usually, you would store these kinds of time stamps as naive datetimes in UTC.
Because the IANA time zone database is updated all the time, you should be conscious of keeping your local time zone database in sync. This is particularly important if you’re running any applications that are sensitive to time zones.
On Mac and Linux, you can usually trust your system to keep the local database updated. If you rely on the tzdata package, then you should remember to update it from time to time. In particular, you shouldn’t leave it pinned to one particular version for years.
Names like "America/Vancouver" give you unambiguous access to a given time zone. However, when communicating time zone–aware datetimes to your users, it’s better to use regular time zone names. These are available as .tzname() on a time zone object:
>>> from datetime import datetime
>>> from zoneinfo import ZoneInfo
>>> tz = ZoneInfo("America/Vancouver")
>>> release = datetime(2020, 10, 5, 3, 9, tzinfo=tz)
>>> f"Release date: {release:%b %d, %Y at %H:%M} {tz.tzname(release)}"
'Release date: Oct 05, 2020 at 03:09 PDT'
You need to provide a time stamp to .tzname(). This is necessary because the name of the time zone may change over time, such as for Daylight Saving Time:
>>> tz.tzname(datetime(2021, 1, 28))
'PST'
During the winter, Vancouver is in Pacific Standard Time (PST), while in summer it’s in Pacific Daylight Time (PDT).
zoneinfo is available in the standard library only for Python 3.9 and later. However, if you’re using earlier versions of Python, then you can still take advantage of zoneinfo. A backport is available on PyPI and can be installed with pip:
$ python -m pip install backports.zoneinfo
You can then use the following idiom when importing zoneinfo:
try:
import zoneinfo
except ImportError:
from backports import zoneinfo
This makes your program compatible with all Python versions from 3.6 and up. See PEP 615 for more details about zoneinfo.
Simpler Updating of Dictionaries
Dictionaries are one of the fundamental data structures in Python. They’re used everywhere in the language and have gotten quite optimized over time.
There are several ways you can merge two dictionaries. However, the syntax is either a bit cryptic or cumbersome:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> {**pycon, **europython}
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> merged = pycon.copy()
>>> for key, value in europython.items():
... merged[key] = value
...
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
Both of these methods merge the dictionaries without changing the original data. Note that "Cleveland" has been overwritten by "Edinburgh" in merged. You can also update a dictionary in place:
>>> pycon.update(europython)
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
This changes your original dictionary, though. Remember that .update() doesn’t return the updated dictionary, so clever attempts at using .update() while leaving the original data untouched don’t work so well:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> merged = pycon.copy().update(europython) # Does NOT work
>>> print(merged)
None
Note that merged is None, and while the two dictionaries were merged, that result has been thrown away. You can use the walrus operator (:=) introduced in Python 3.8 to make this work:
>>> (merged := pycon.copy()).update(europython)
>>> merged
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
Still, this is not a particularly readable or satisfying solution.
Based on PEP 584, the new version of Python introduces two new operators for dictionaries: union (|) and in-place union (|=). You can use | to merge two dictionaries, while |= will update a dictionary in place:
>>> pycon = {2016: "Portland", 2018: "Cleveland"}
>>> europython = {2017: "Rimini", 2018: "Edinburgh", 2019: "Basel"}
>>> pycon | europython
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
>>> pycon |= europython
>>> pycon
{2016: 'Portland', 2018: 'Edinburgh', 2017: 'Rimini', 2019: 'Basel'}
If d1 and d2 are two dictionaries, then d1 | d2 does the same as {**d1, **d2}. The | operator is used for calculating the union of sets, so the notation may already be familiar to you.
One advantage of using | is that it works on different dictionary-like types and keeps the type through the merge:
>>> from collections import defaultdict
>>> europe = defaultdict(lambda: "", {"Norway": "Oslo", "Spain": "Madrid"})
>>> africa = defaultdict(lambda: "", {"Egypt": "Cairo", "Zimbabwe": "Harare"})
>>> europe | africa
defaultdict(<function <lambda> at 0x7f0cb42a6700>,
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'})
>>> {**europe, **africa}
{'Norway': 'Oslo', 'Spain': 'Madrid', 'Egypt': 'Cairo', 'Zimbabwe': 'Harare'}
You can use a defaultdict when you want to effectively handle missing keys. Note that | preserves the defaultdict, while {**europe, **africa} does not.
There are some similarities between how | works for dictionaries and how + works for lists. In fact, the + operator was originally proposed to merge dictionaries as well. This correspondence becomes even more evident when you look at the in-place operator.
The basic use of |= is to update a dictionary in place, similar to .update():
>>> libraries = {
... "collections": "Container datatypes",
... "math": "Mathematical functions",
... }
>>> libraries |= {"zoneinfo": "IANA time zone support"}
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support'}
When you merge dictionaries with |, both dictionaries need to be of a proper dictionary type. On the other hand, the in-place operator (|=) is happy to work with any dictionary-like data structure:
>>> libraries |= [("graphlib", "Functionality for graph-like structures")]
>>> libraries
{'collections': 'Container datatypes', 'math': 'Mathematical functions',
'zoneinfo': 'IANA time zone support',
'graphlib': 'Functionality for graph-like structures'}
In this example, you update libraries from a list of 2-tuples. When there are overlapping keys in two dictionaries that you want to merge, the last value is kept:
>>> asia = {"Georgia": "Tbilisi", "Japan": "Tokyo"}
>>> usa = {"Missouri": "Jefferson City", "Georgia": "Atlanta"}
>>> asia | usa
{'Georgia': 'Atlanta', 'Japan': 'Tokyo', 'Missouri': 'Jefferson City'}
>>> usa | asia
{'Missouri': 'Jefferson City', 'Georgia': 'Tbilisi', 'Japan': 'Tokyo'}
In the first example, "Georgia" points to "Atlanta" because usa is the last dictionary in the merge. The value "Tbilisi" from asia has been overwritten. Note that the key "Georgia" is still first in the resulting dictionary because it’s the first element in asia. Reversing the order of the merge changes both the position and the value of "Georgia".
The operators | and |= have been added not only to regular dictionaries but also to many dictionary-like classes including UserDict, ChainMap, OrderedDict, defaultdict, WeakKeyDictionary, WeakValueDictionary, _Environ, and MappingProxyType. They have not been added to the abstract base classes Mapping or MutableMapping. The Counter container already uses | for finding maximal counts. This hasn’t changed.
You can change the behavior of | and |= by implementing .__or__() and .__ior__(), respectively. See PEP 584 for more details.
More Flexible Decorators
Traditionally, a decorator has had to be a named, callable object, usually a function or a class. PEP 614 allows decorators to be any callable expression.
Most people don’t consider the old decorator syntax to be limiting. Indeed, loosening up the grammar for decorators mainly helps in a few niche use cases. According to the PEP, the motivating use case relates to callbacks in GUI frameworks.
PyQT uses signals and slots to connect widgets with callbacks. Conceptually, you can do something like the following to connect the clicked signal of button to the slot say_hello():
button = QPushButton("Say hello")
@button.clicked.connect
def say_hello():
message.setText("Hello, World!")
This will display the text Hello, World! when you click the button Say hello.
Note: This is not a complete example, and it will raise an error if you try to run it. It’s been kept deliberately short to keep the focus on decorators instead of getting bogged down in details about how PyQT works.
For more information on getting started with PyQT and setting up a complete application, see Python and PyQt: Building a GUI Desktop Calculator.
Now assume that you have several buttons, and to keep track of them, you store them in a dictionary:
buttons = {
"hello": QPushButton("Say hello"),
"leave": QPushButton("Goodbye"),
"calculate": QPushButton("3 + 9 = 12"),
}
This is all fine. However, it creates a challenge for you if you want to use a decorator to connect a button to a slot. In earlier versions of Python, you couldn’t access items using square brackets when using a decorator. You would need to do something like the following:
hello_button = buttons["hello"]
@hello_button.clicked.connect
def say_hello():
message.setText("Hello, World!")
In Python 3.9, these restrictions are lifted and you can now use any expression, including one accessing items in a dictionary:
@buttons["hello"].clicked.connect
def say_hello():
message.setText("Hello, World!")
While this isn’t a big change, it allows you to write cleaner code in a few cases. The extended syntax also makes it easier to choose decorators dynamically at runtime. Say that you have the following decorators available:
# story.py
import functools
def normal(func):
return func
def shout(func):
@functools.wraps(func)
def shout_decorator(*args, **kwargs):
return func(*args, **kwargs).upper()
return shout_decorator
def whisper(func):
@functools.wraps(func)
def whisper_decorator(*args, **kwargs):
return func(*args, **kwargs).lower()
return whisper_decorator
The @normal decorator doesn’t change the original function at all, while @shout and @whisper make whatever text is returned from a function either uppercase or lowercase. You can then store references to these decorators in a dictionary and make them available to the user:
# story.py (continued)
DECORATORS = {"normal": normal, "shout": shout, "whisper": whisper}
voice = input(f"Choose your voice ({', '.join(DECORATORS)}): ")
@DECORATORS[voice]
def get_story():
return """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into
the book her sister was reading, but it had no pictures or
conversations in it, "and what is the use of a book," thought Alice
"without pictures or conversations?"
"""
print(get_story())
When you run this script, you’ll be asked which decorator to apply to the story. The resulting text is then printed to the screen:
$ python3.9 story.py
Choose your voice (normal, shout, whisper): shout
ALICE WAS BEGINNING TO GET VERY TIRED OF SITTING BY HER SISTER ON THE
BANK, AND OF HAVING NOTHING TO DO: ONCE OR TWICE SHE HAD PEEPED INTO
THE BOOK HER SISTER WAS READING, BUT IT HAD NO PICTURES OR
CONVERSATIONS IN IT, "AND WHAT IS THE USE OF A BOOK," THOUGHT ALICE
"WITHOUT PICTURES OR CONVERSATIONS?"
This example is the same as if @shout had been applied to get_story(). However, here it has been applied at runtime based on your input. As with the button example, you can achieve the same effect in earlier versions of Python by using a temporary variable.
For more information about decorators, check out Primer on Python Decorators. For more details about the relaxed grammar, see PEP 614.
Annotated Type Hints
Function annotations were introduced in Python 3.0. The syntax supports adding arbitrary metadata to Python functions. Here’s one example adding units to a formula:
# calculator.py
def speed(distance: "feet", time: "seconds") -> "miles per hour":
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
In this example, the annotations are used only as documentation for the reader. You’ll see later how to access annotations at runtime.
PEP 484 suggested that annotations should be used for type hints. As type hints have grown in popularity, they’ve mostly crowded out any other uses of annotations in Python.
Since there are several use cases for annotations outside of static typing, PEP 593 introduces typing.Annotated, which you can use to combine type hints with other information. You can redo the calculator.py example from above like this:
# calculator.py
from typing import Annotated
def speed(
distance: Annotated[float, "feet"], time: Annotated[float, "seconds"]
) -> Annotated[float, "miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Annotated takes at least two arguments. The first argument is a regular type hint, and the rest of the arguments are arbitrary metadata. A type checker will care about only the first argument, leaving the interpretation of the metadata to you and your application. A type hint like Annotated[float, "feet"] will be treated equally to float by type checkers.
You can access annotations through .__annotations__ as usual. Import speed() from calculator.py:
>>> from calculator import speed
>>> speed.__annotations__
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
Each of the annotations is available in the dictionary. The metadata you defined with Annotated are stored in .__metadata__:
>>> speed.__annotations__["distance"].__metadata__
('feet',)
>>> {var: th.__metadata__[0] for var, th in speed.__annotations__.items()}
{'distance': 'feet', 'time': 'seconds', 'return': 'miles per hour'}
The last example picks out all the units by reading the first metadata item for each variable. Another way to access type hints at runtime is to use get_type_hints() from the typing module. get_type_hints() will ignore metadata by default:
>>> from typing import get_type_hints
>>> from calculator import speed
>>> get_type_hints(speed)
{'distance': <class 'float'>,
'time': <class 'float'>,
'return': <class 'float'>}
This should allow most programs that access type hints at runtime to continue working without change. You can use the new optional parameter include_extras to ask for metadata to be included:
>>> get_type_hints(speed, include_extras=True)
{'distance': typing.Annotated[float, 'feet'],
'time': typing.Annotated[float, 'seconds'],
'return': typing.Annotated[float, 'miles per hour']}
Using Annotated could result in quite verbose code. One way to keep your code short and readable is to use type aliases. You can define new variables representing annotated types:
# calculator.py
from typing import Annotated
Feet = Annotated[float, "feet"]
Seconds = Annotated[float, "seconds"]
MilesPerHour = Annotated[float, "miles per hour"]
def speed(distance: Feet, time: Seconds) -> MilesPerHour:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Type aliases may take some work to set up, but they can make your code quite clear and readable.
If you have an application in which you use annotations extensively, you could also consider implementing an annotation factory. Add the following to the top of calculator.py:
# calculator.py
from typing import Annotated
class AnnotationFactory:
def __init__(self, type_hint):
self.type_hint = type_hint
def __getitem__(self, key):
if isinstance(key, tuple):
return Annotated[(self.type_hint, ) + key]
else:
return Annotated[self.type_hint, key]
def __repr__(self):
return f"{self.__class__.__name__}({self.type_hint})"
AnnotationFactory can create Annotated objects with different metadata. You can use the annotation factory to create more dynamic aliases. Update calculator.py to use AnnotationFactory:
# calculator.py (continued)
Float = AnnotationFactory(float)
def speed(
distance: Float["feet"], time: Float["seconds"]
) -> Float["miles per hour"]:
"""Calculate speed as distance over time"""
fps2mph = 3600 / 5280 # Feet per second to miles per hour
return distance / time * fps2mph
Float[<metadata>] represents Annotated[float, <metadata>], so this example works exactly the same as the previous two examples.
A More Powerful Python Parser
One of the coolest features of Python 3.9 is one that you won’t notice in your daily coding life. A fundamental component of the Python interpreter is the parser. In the latest version, the parser has been reimplemented.
Since its inception, Python has used a basic LL(1) parser to parse source code into parse trees. You can think of an LL(1) parser as one that reads one character at a time and figures out how to interpret the source code without backtracking.
One advantage of using a simple parser is that it’s fairly straightforward to implement and reason about. A disadvantage is that there are hard cases that you need to circumvent with special hacks.
In a series of blog posts, Guido van Rossum—Python’s creator—investigated PEG (parsing expression grammar) parsers. PEG parsers are more powerful than LL(1) parsers and avoid the need for special hacks. As a result of Guido’s research, a PEG parser was implemented in Python 3.9. See PEP 617 for more details.
The goal is for the new PEG parser to produce the same abstract syntax tree (AST) as the old LL(1) parser. The latest version actually ships with both parsers. While the PEG parser is the default, you can run your program using the old parser by using the -X oldparser command-line flag:
$ python -X oldparser script_name.py
Alternatively, you can set the PYTHONOLDPARSER environment variable.
The old parser will be removed in Python 3.10. This will allow for new features without the limitations of an LL(1) grammar. One such feature currently being considered for inclusion in Python 3.10 is structural pattern matching, as described in PEP 622.
Having both parsers available is great for validating the new PEG parser. You can run any code on both parsers and compare it at the AST level. During testing, the whole standard library as well as many popular third-party packages were compiled and compared.
You can also compare the performance of the two parsers. In general, the PEG parser and the LL(1) perform similarly. Over the whole standard library, the PEG parser is slightly faster, but it also uses slightly more memory. In practice, you shouldn’t notice any change in performance, good or bad, when using the new parser.
Other Pretty Cool Features
So far, you’ve seen the biggest new features in Python 3.9. However, each new release of Python includes many small changes as well. The official documentation includes a list of all those changes. In this section, you’ll get to know a few of the other pretty cool new features that you can start playing with.
String Prefix and Suffix
If you need to remove the beginning or the end of a string, then .strip() seems like it can do the job:
>>> "three cool features in Python".strip(" Python")
'ree cool features i'
The suffix " Python" has been removed, but so has "th" at the beginning of the string. The actual behavior of .strip() is sometimes surprising—and has triggered many bug reports. It’s natural to assume that .strip(" Python") will remove the substring " Python", but it removes the individual characters " ", "P", "y", "t", "h", "o", and "n" instead.
To actually remove a string suffix, you could do something like this:
>>> def remove_suffix(text, suffix):
... if text.endswith(suffix):
... return text[:-len(suffix)]
... else:
... return text
...
>>> remove_suffix("three cool features in Python", suffix=" Python")
'three cool features in'
This works better but is a bit cumbersome. This code also has a subtle bug:
>>> remove_suffix("three cool features in Python", suffix="")
''
If suffix happens to be the empty string, somehow the whole string has been removed. This is because the length of the empty string is 0, so then text[:0] ends up being returned. You can fix this by rephrasing the test to be on suffix and text.endswith(suffix).
In Python 3.9, there are two new string methods that solve this exact use case. You can use .removeprefix() and .removesuffix() to remove the beginning or end of a string, respectively:
>>> "three cool features in Python".removesuffix(" Python")
'three cool features in'
>>> "three cool features in Python".removeprefix("three ")
'cool features in Python'
>>> "three cool features in Python".removeprefix("Something else")
'three cool features in Python'
Note that if the given prefix or suffix doesn’t match the string, then you get the string back untouched.
.removeprefix() and .removesuffix() remove at most one copy of the affix. If you want to be sure to remove all of them, then you can use a while loop:
>>> text = "Waikiki"
>>> text.removesuffix("ki")
'Waiki'
>>> while text.endswith("ki"):
... text = text.removesuffix("ki")
...
>>> text
'Wai'
See PEP 616 for more information about .removeprefix() and .removesuffix().
Type Hint Lists and Dictionaries Directly
It’s usually quite straightforward to add type hints for basic types like str, int, and bool. You annotate with the type directly. This situation is similar with custom types you create yourself:
radius: float = 3.9
class NothingType:
pass
nothing: NothingType = NothingType()
Generics are a different story. A generic type is typically a container that can be parametrized, such as a list of numbers. For technical reasons, in previous Python versions you haven’t been able to use list[float] or list(float) as type hints. Instead, you’ve needed to import a different list object from the typing module:
from typing import List
numbers: List[float]
In Python 3.9, this parallel hierarchy is no longer necessary. You can now finally use list for proper type hints as well:
numbers: list[float]
This will make your code easier to write and eliminate the confusion about having both list and List. In the future, using typing.List and similar generics like typing.Dict and typing.Type will be deprecated and the generics will eventually be removed from typing.
If you need to write code that’s compatible with older versions of Python, then you can still take advantage of the new syntax by using the __future__ import that was made available in Python 3.7. In Python 3.7, you’ll usually see something like this:
>>> numbers: list[float]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'type' object is not subscriptable
However, using the __future__ import makes this example work:
>>> from __future__ import annotations
>>> numbers: list[float]
>>> __annotations__
{'numbers': 'list[float]'}
This works because the annotation isn’t evaluated at runtime. If you try to evaluate the annotations, then you’ll still experience the TypeError. For more information about this new syntax, see PEP 585.
Topological Sort
Graphs consisting of nodes and edges are useful for representing different kinds of data. For example, when you use pip to install a package from PyPI, that package may depend on other packages, which may in turn have more dependencies.
This structure can be represented by a graph in which each package is a node and each dependency is represented by an edge:
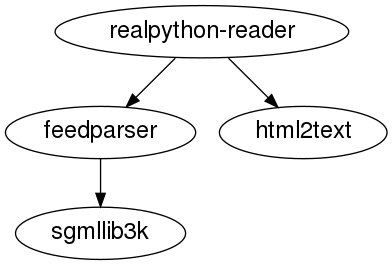
This graph shows the dependencies of the realpython-reader package. It depends directly on feedparser and html2text, while feedparser in turn depends on sgmllib3k.
Say that you want to install these packages in an order such that all dependencies are always fulfilled. You would then do what’s called a topological sort to find a total order of your dependencies.
Python 3.9 introduces a new module, graphlib, into the standard library to do topological sorting. You can use it to find the total order of a set or to do more advanced scheduling taking into account tasks that can be parallelized. To see an example, you can represent the earlier dependencies in a dictionary:
>>> dependencies = {
... "realpython-reader": {"feedparser", "html2text"},
... "feedparser": {"sgmllib3k"},
... }
...
This expresses the dependencies you saw in the figure above. For example, realpython-reader depends on feedparser and html2text. In this case, the specific dependencies of realpython-reader are written as a set: {"feedparser", "html2text"}. You can use any iterable to specify these, including a list.
Note: Remember that a string is an iterable over its characters. Therefore, you usually want to wrap single strings in some kind of container:
>>> dependencies = {"feedparser": "sgmllib3k"} # Will NOT work
This does not say that feedparser depends on sgmllib3k. Instead, it says that feedparser depends on each of s, g, m, l, l, i, b, 3, and k.
To calculate a total order of the graph, you can use TopologicalSorter from graphlib:
>>> from graphlib import TopologicalSorter
>>> ts = TopologicalSorter(dependencies)
>>> list(ts.static_order())
['html2text', 'sgmllib3k', 'feedparser', 'realpython-reader']
The given order suggests that you should first install html2text, then sgmllib3k, then feedparser, and finally realpython-reader.
Note: The total order of a graph is not necessarily unique. In this example, other valid orderings would be:
sgmllib3k,html2text,feedparser,realpython-readersgmllib3k,feedparser,html2text,realpython-reader
TopologicalSorter has an extensive API that allows you to add nodes and edges incrementally using .add(). You can also consume the graph iteratively, which is especially useful when scheduling tasks that can be done in parallel. See the documentation for a full example.
Greatest Common Divisor (GCD) and Least Common Multiple (LCM)
The divisors of a number are an important property that has applications in cryptography and other areas. Python has had a function for calculating the greatest common divisor (GCD) of two numbers for a long time:
>>> import math
>>> math.gcd(49, 14)
7
The GCD of 49 and 14 is 7 because 7 is the largest number that divides both 49 and 14.
The least common multiple (LCM) is related to GCD. The LCM of two numbers is the smallest number that can be divided by both of them. It’s possible to define LCM in terms of GCD:
>>> def lcm(num1, num2):
... if num1 == num2 == 0:
... return 0
... return num1 * num2 // math.gcd(num1, num2)
...
>>> lcm(49, 14)
98
The least common multiple of 49 and 14 is 98 because 98 is the smallest number that can be divided by both 49 and 14. In Python 3.9, you no longer need to define your own LCM function:
>>> import math
>>> math.lcm(49, 14)
98
Both math.gcd() and math.lcm() now also support more than two numbers. You can, for instance, calculate the greatest common divisor of 273, 1729, and 6048 like this:
>>> import math
>>> math.gcd(273, 1729, 6048)
7
Note that math.gcd() and math.lcm() aren’t able to calculate based on lists. However, you can unpack lists into comma-separated arguments:
>>> import math
>>> numbers = [273, 1729, 6048]
>>> math.gcd(numbers)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'list' object cannot be interpreted as an integer
>>> math.gcd(*numbers)
7
In earlier versions of Python, you would need to nest several calls to gcd() or use functools.reduce():
>>> import math
>>> math.gcd(math.gcd(273, 1729), 6048)
7
>>> import functools
>>> functools.reduce(math.gcd, [273, 1729, 6048])
7
In the latest version of Python, these calculations have gotten more straightforward to write.
New HTTP Status Codes
The IANA coordinates several key Internet infrastructure resources, including the Time Zone Database you saw earlier. Another such resource is the HTTP Status Code Registry. HTTP status codes are available in the http standard library:
>>> from http import HTTPStatus
>>> HTTPStatus.OK
<HTTPStatus.OK: 200>
>>> HTTPStatus.OK.description
'Request fulfilled, document follows'
>>> HTTPStatus(404)
<HTTPStatus.NOT_FOUND: 404>
>>> HTTPStatus(404).phrase
'Not Found'
In Python 3.9, the new HTTP status codes 103 (Early Hints) and 425 (Too Early) have been added to http:
>>> from http import HTTPStatus
>>> HTTPStatus.EARLY_HINTS.value
103
>>> HTTPStatus(425).phrase
'Too Early'
As you can see, you can access the new codes based on both their number and their name.
The Hyper Text Coffee Pot Control Protocol (HTCPCP) was introduced on April 1, 1998, to control, monitor, and diagnose coffee pots. It introduced new methods like BREW while mainly reusing the existing HTTP status codes. One exception was the new 418 (I’m a Teapot) status code meant to prevent the disaster of destroying a good teapot by brewing coffee in it.
The Hyper Text Coffee Pot Control Protocol for Tea Efflux Appliances (HTCPCP-TEA) also included 418 (I’m a Teapot) and the code also found its way into many mainstream HTTP libraries, including requests.
An initiative in 2017 to remove 418 (I’m a Teapot) from major libraries was met with swift pushback. Ultimately, the debate ended with 418 being proposed as a reserved HTTP status code. 418 (I’m a Teapot) has also been added to http:
>>> from http import HTTPStatus
>>> HTTPStatus(418).phrase
"I'm a Teapot"
>>> HTTPStatus.IM_A_TEAPOT.description
'Server refuses to brew coffee because it is a teapot.'
There are a few places you can see a 418 error in the wild, including on Google.
Removal of Deprecated Compatibility Code
One important milestone for Python in the last year has been the sunsetting of Python 2. Python 2.7 was first released in 2010. On January 1, 2020, official support for Python 2 ended.
Python 2 has served the community well for close to twenty years and is remembered fondly by many. At the same time, being free of the concern of keeping Python 3 somewhat compatible with Python 2 allows the core developers to focus on the continued improvement of Python 3 and to do some house cleaning along the way.
Many functions that were deprecated but kept around for backward compatibility with Python 2 have been removed in Python 3.9. A few more will be removed in Python 3.10. If you’re wondering whether your code uses any of these older features, then try running it in development mode:
$ python -X dev script_name.py
Using development mode will show you more warnings that can help you future-proof your code. See What’s New In Python 3.9 for more information about features being removed.
When Is the Next Version of Python Coming?
One final change in Python 3.9 unrelated to code is described by PEP 602—Annual Release Cycle for Python. Traditionally, new versions of Python have been released about every eighteen months.
Starting with the current version of Python, new versions will be released approximately every twelve months, in October of each year. This brings several advantages, the most evident being a more predictable and consistent release schedule. With annual releases, it’s easier to plan and synchronize with other important developer events like the PyCon US sprints and the annual core sprint.
While releases will happen more frequently going forward, Python won’t become incompatible faster or get new features faster. All releases will be supported for five years after their initial release, so Python 3.9 will receive security fixes until 2025.
With shorter release cycles, new features will be released faster. At the same time, new releases will bring fewer changes, making the update less critical.
Elections for Python’s steering council are held after every Python release. Going forward, this means that there will be annual elections for the five positions in the steering council.
Even though a new version of Python will be published every twelve months, development on a new version starts about seventeen months before its release. This is because no new features are added to a release during its beta testing phase, which lasts for about five months.
In other words, development on the next version of Python, Python 3.10, is already well underway. You can already test the first alpha version of Python 3.10 by running the latest core developers’ Docker image.
The final features of Python 3.10 are still to be decided. However, the version number is somewhat special in that it’s the first Python version with a two-digit minor version. This could cause some issues if, for instance, you have code that compares versions as strings because "3.9" > "3.10". A better solution is to compare versions as tuples: (3, 9) < (3, 10). The package flake8-2020 tests for these and similar issues in your code.
So, Should You Upgrade to Python 3.9?
To start with the evident, if you want to try out any of the cool new features showcased in this tutorial, then you’ll need to use Python 3.9. It’s possible to install the latest version side by side with your current version of Python. The easiest way is to use an environment manager like pyenv or conda. Even less intrusive would be running the new version through Docker.
When you consider upgrading to Python 3.9, there are really two different questions you should ask yourself:
- Should you upgrade your developer or production environment to Python 3.9?
- Should you make your project dependent on Python 3.9 so you can take advantage of the new features?
If you have code that’s running smoothly in Python 3.8, then you should experience few problems running the same code in Python 3.9. The main stumbling block will be if you rely on functions that have been deprecated in earlier versions of Python and are now being removed.
The new PEG parser has naturally not been tested as extensively as the old one. If you’re unlucky, you could run into some weird corner-case issues. However, remember that you can switch back to the old parser with a command-line flag.
Altogether, you should be quite safe upgrading your own environment to the latest version of Python as early as is convenient for you. If you want to be a bit more conservative, then you can wait for the first maintenance release, Python 3.9.1.
Whether you can start to really take advantage of the new features in your own code depends a lot on your user base. If your code is being run only in environments that you can control and upgrade to Python 3.9, then there’s no harm in using zoneinfo or the new dictionary merge operators.
However, if you’re distributing a library that’s being used by many others, then it’s better to be more conservative. The last version of Python 3.5 was released in September, and it’s no longer supported. If possible, you should still aim at having your library compatible with Python 3.6 and newer so that as many people as possible can enjoy your efforts.
For details about preparing your code for Python 3.9, see Porting to Python 3.9 in the official documentation.
Conclusion
The release of a new Python version is a big milestone for the community. You may not be able to start using the cool new features immediately, but in a few years Python 3.9 will be as widespread as Python 3.6 is today.
In this tutorial, you’ve seen new features like:
- The
zoneinfomodule for dealing with time zones - Union operators that can update dictionaries
- More expressive decorator syntax
- Annotations that can be used for other things besides type hints
For more Python 3.9 tips and a panel discussion with members of the Real Python team, check out these additional resources:
Set aside a few minutes to try out the features that excite you the most, then share your experiences in the comments below!









