Scrapy is a robust Python web scraping framework that can manage requests asynchronously, follow links, and parse site content. To store scraped data, you can use MongoDB, a scalable NoSQL database, that stores data in a JSON-like format. Combining Scrapy with MongoDB offers a powerful solution for web scraping projects, leveraging Scrapy’s efficiency and MongoDB’s flexible data storage.
In this tutorial, you’ll learn how to:
- Set up and configure a Scrapy project
- Build a functional web scraper with Scrapy
- Extract data from websites using selectors
- Store scraped data in a MongoDB database
- Test and debug your Scrapy web scraper
If you’re new to web scraping and you’re looking for flexible and scalable tooling, then this is the right tutorial for you. You’ll also benefit from learning this tool kit if you’ve scraped sites before, but the complexity of your project has outgrown using Beautiful Soup and Requests.
To get the most out of this tutorial, you should have basic Python programming knowledge, understand object-oriented programming, comfortably work with third-party packages, and be familiar with HTML and CSS.
By the end, you’ll know how to get, parse, and store static data from the Internet, and you’ll be familiar with several useful tools that allow you to go much deeper.
Get Your Code: Click here to download the free code that shows you how to gather Web data with Scrapy and MongoDB.
Take the Quiz: Test your knowledge with our interactive “Web Scraping With Scrapy and MongoDB” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Web Scraping With Scrapy and MongoDBIn this quiz, you'll test your understanding of web scraping with Scrapy and MongoDB. You'll revisit how to set up a Scrapy project, build a functional web scraper, extract data from websites, store scraped data in MongoDB, and test and debug your Scrapy web scraper.
Prepare the Scraper Scaffolding
You’ll start by setting up the necessary tools and creating a basic project structure that will serve as the backbone for your scraping tasks.
While working through the tutorial, you’ll build a complete web scraping project, approaching it as an ETL (Extract, Transform, Load) process:
- Extract data from the website using a Scrapy spider as your web crawler.
- Transform this data, for example by cleaning or validating it, using an item pipeline.
- Load the transformed data into a storage system like MongoDB with an item pipeline.
Scrapy provides scaffolding for all of these processes, and you’ll tap into that scaffolding to learn web scraping following the robust structure that Scrapy provides and that numerous enterprise-scale web scraping projects rely on.
Note: In a Scrapy web scraping project, a spider is a Python class that defines how to crawl a specific website or a group of websites. It contains the logic for making requests, parsing responses, and extracting the desired data.
First, you’ll install Scrapy and create a new Scrapy project, then explore the auto-generated project structure to ensure that you’re well-equipped to proceed with building a performant web scraper.
Install the Scrapy Package
To get started with Scrapy, you first need to install it using pip. Create and activate a virtual environment to keep the installation separate from your global Python installation. Then, you can install Scrapy:
(venv) $ python -m pip install scrapy
After the installation is complete, you can verify it by running the scrapy command and viewing the output:
(venv) $ scrapy
Scrapy 2.11.2 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command
The command-line (CLI) program should display the help text of Scrapy. This confirms that you installed the package correctly. You’ll next run the highlighted startproject command to create a project.
Create a Scrapy Project
Scrapy is built around projects. Generally, you’ll create a new project for each web scraping project that you’re working on. In this tutorial, you’ll work on scraping a website called Books to Scrape, so you can call your project books.
As you may have already identified in the help text, the framework provides a command to create a new project:
(venv) $ scrapy startproject books
This command resembles the command that you use to generate the scaffolding for a new Django project, and Scrapy and Django are two mature frameworks that can interact well with each other.
In Scrapy, the startproject command generates a new Scrapy project named books that sets you up with a project structure containing several auto-generated files and directories:
books/
│
├── books/
│ │
│ ├── spiders/
│ │ └── __init__.py
│ │
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ └── settings.py
│
└── scrapy.cfg
Scrapy relies on this structure, and it’ll help you in organizing your Scrapy project efficiently. Click around the different files and folders and think about what each of them might mean in the context of a web scraping project:
books/is the root directory of your Scrapy project.books/spiders/is a directory to store your spider definitions.books/items.pyis a file to define the data structure of your scraped items.books/middlewares.pyis a file to manage your custom middlewares.books/pipelines.pyis a file to define item processing pipelines.books/settings.pyis the settings file to configure your project.
In this tutorial, you’ll touch most of the files that you can see listed above and add your custom functionality to them. With your project scaffolding set up, you’ll now take a look at the source website that you want to extract information from.
Inspect the Source That You Want to Scrape
You won’t get far in your web scraping ambitions if you don’t know the structure of the website that you want to scrape information from. Therefore, it’s an essential early step in this process to inspect the target website. The quickest way to inspect a website is to open up your browser, navigate to the site, and click around.
Look at the Website in Your Browser
Start by navigating the target website in your browser as a user. Identify the specific elements that you want to scrape. For example, if you’re scraping book titles, prices, and URLs from a bookstore, then inspect the HTML to locate these elements. You can do this best using your browser’s built-in developer tools.
Note: Each browser has slightly different ways to open up the developer tools. If you haven’t looked into browser developer tools before, then you may need to do a web search on how to open them in your specific case. You can also check out a guide on how to inspect a site using developer tools.
Once you’ve opened the developer tools in your browser and identified a book item, you’ll get to see an interface that’ll look similar to the one shown below:
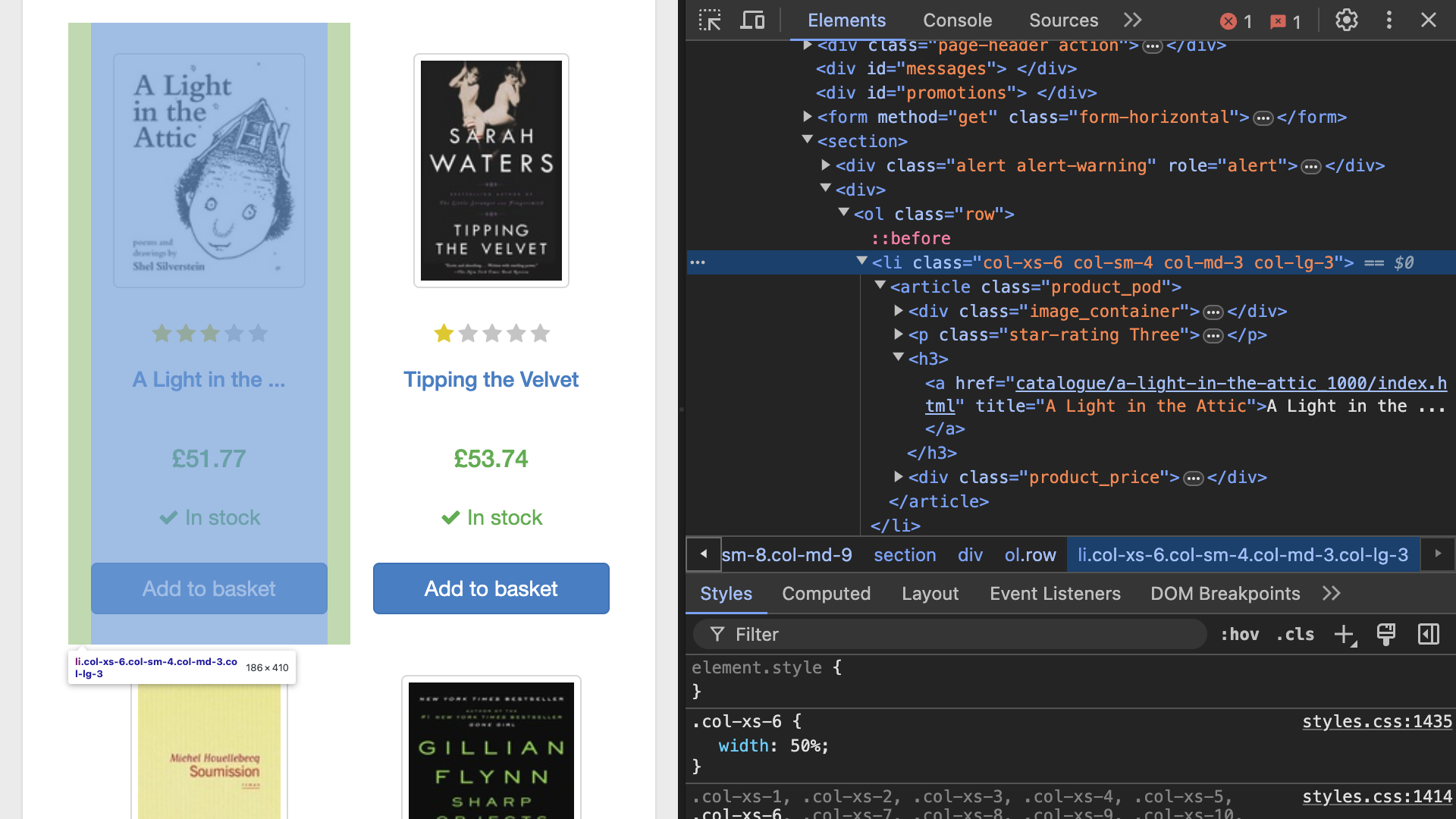
After you’ve gotten a good idea of how the information is organized on the site, you’ll want to gather the unique selectors for each piece of information that you want to scrape. You’ll want to extract three data points from each book:
- Title
- Price
- URL
You can use the developer tools to gather XPath expressions or CSS selectors for each of these elements by right-clicking on the element and selecting Copy → Copy selector or Copy → Copy XPath. For example, if you copy the CSS selectors for the first book on the site, then you should get the following values for each of the elements:
| Element | CSS Selector |
|---|---|
| Title | #default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a |
| Price | #default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color |
| URL | #default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a |
These are much too long to keep track of! However, you may notice that they all start the same way. That’s because they’re absolute paths that start at the root element of the HTML document.
Note: Using absolute selectors can be a quick way to identify elements in the document, but they’re brittle and prone to breaking if there are any changes in the document structure. For more robust and maintainable code, relative selectors are generally a better choice.
It looks like you can find all the information that you’re interested in within an <article> tag. Head back over to your browser and identify that <article> element:
<article class="product_pod">
<div class="image_container">
<a href="catalogue/a-light-in-the-attic_1000/index.html"><img
src="media/cache/2c/da/2cdad67c44b002e7ead0cc35693c0e8b.jpg"
alt="A Light in the Attic" class="thumbnail"></a>
</div>
<p class="star-rating Three">
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
<i class="icon-star"></i>
</p>
<h3><a href="catalogue/a-light-in-the-attic_1000/index.html"
title="A Light in the Attic">A Light in the ...</a></h3>
<div class="product_price">
<p class="price_color">£51.77</p>
<p class="instock availability">
<i class="icon-ok"></i>
In stock
</p>
<form>
<button type="submit" class="btn btn-primary btn-block"
data-loading-text="Adding...">Add to basket</button>
</form>
</div>
</article>
The highlighted lines confirm that you can find all three pieces of information for each book in its <article> element—and that element even has a class name, product_pod!
You can therefore plan to first target all <article> elements with the class name product_pod. These represent a single book’s parent element, which contains all of the information that you want. You can then loop over all of these, and extract the relevant information with much shorter selectors.
But is there a good way to confirm which selectors will do your bidding, before writing the whole spider script? Yes there is! You can work with Scrapy’s built-in shell to do just that, and more.
Preview the Data With the Scrapy Shell
Before writing a full-fledged spider, it’s often useful to preview and test how you’ll extract data from a webpage. The Scrapy shell is an interactive tool that lets you inspect and extract data from web pages in real time. This helps in experimenting with XPath expressions and CSS selectors to ensure they correctly target the elements you’re looking for.
Note: Using the shell allows you to view the data exactly like it comes back from an HTTP request. When you inspect the rendered page in your browser, you view the browser-internal representation of the Document Object Model (DOM). To create it, your browser may have executed JavaScript code and cleaned up malformed HTML, which makes the resulting HTML you can inspect using developer tools different from the original HTML.
You can open the shell and point it to the site that you want to scrape by using the shell command followed by the site’s URL:
(venv) $ scrapy shell http://books.toscrape.com
This command loads the specified URL and gives you an interactive environment to explore the page’s HTML structure. You can think of it like an interactive Python REPL, but with access to Scrapy objects and the target site’s HTML content.
When you run this command, you’ll see some logs followed by usage instructions:
...
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x1070dcd40>
[s] item {}
[s] request <GET https://books.toscrape.com/>
[s] response <200 https://books.toscrape.com/>
[s] settings <scrapy.settings.Settings object at 0x10727ac90>
[s] spider <BookSpider 'book' at 0x107756990>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>
The shell provides several pre-imported objects, with response being the most important one for inspecting the data that you might want to extract.
The response object has several useful attributes and methods that allow you to inspect the page similarly to how you previously did using your browser’s developer tools:
.urlcontains the URL of the page..statusshows you the HTTP status code of the response..headersdisplays all the HTTP headers of the response..bodycontains the raw bytes of the response..textcontains the decoded text of the response as a Unicode string.
For example, to check the HTTP status code of the response, you can run the following command:
>>> response.status
200
The response object also contains the content of the page that you’ve loaded. You can use it to examine the HTML and find the elements that you want to scrape. To view the HTML content of the page, you can use .text:
>>> response.text
'<!DOCTYPE html>\n<!--[if lt IE 7]>
...
However, printing the entire HTML is usually overwhelming, so it’s more practical to use XPath expressions or CSS selectors to target specific elements.
Scrapy uses the Parsel library to handle XPath expressions and CSS selectors. Parsel provides a Selector class that you can use independently of Scrapy. This is useful if you want to experiment with HTML parsing:
>>> from parsel import Selector
>>> html = "<html><body><h1>Hello, world!</h1></body></html>"
>>> selector = Selector(text=html)
>>> text = selector.xpath("//h1/text()").get()
>>> text
'Hello, world!'
You can use the same Parsel selectors within Scrapy to parse the response object.
You can now try the CSS selectors that you’ve found using your developer tools to confirm whether they can target the information that you want. You could also use XPath expressions instead, but CSS selectors will probably be more familiar to you if you’ve explored web development.
First, you want to drill down in the HTML to the <article> elements that contain all the information for one book, then select each book title using only the relevant part of the long CSS selector that you’ve found through copying:
>>> all_book_elements = response.css("article.product_pod")
>>> for book in all_book_elements:
... print(book.css("h3 > a::attr(title)").get())
...
A Light in the Attic
Tipping the Velvet
Soumission
(...)
You started by targeting all book container elements and assigned the result to all_book_elements. Calls to .css() return other Selector objects, so you can continue to drill down further using another call to .css(). This time, you define that you want the value of the title HTML attribute of all link elements contained within an <h3> element. By calling .get() on the resulting Selector, you get the first match of the results as a string.
You can use this approach to successfully print all book titles to your terminal.
Note: For this site, it’s not actually necessary to drill down into the <article> elements first, because the page doesn’t contain any other <h3> elements that contain links. Therefore, you could run the same .css() query directly on response to get the same result.
However, in general you can’t rely on something like that. It’ll all depend on the individual structure of the site that you’re scraping, so drilling down deeper into the HTML is often helpful.
You confirmed that you can get all the book titles with a shortened CSS selector. Now, target the URLs and the prices in a similar manner:
>>> for book in all_book_elements:
... print(book.css("h3 > a::attr(href)").get())
...
catalogue/a-light-in-the-attic_1000/index.html
catalogue/tipping-the-velvet_999/index.html
catalogue/soumission_998/index.html
(...)
>>> for book in all_book_elements:
... print(book.css(".price_color::text").get())
...
£51.77
£53.74
£50.10
(...)
Great, you can address all the information that you want. Before using this approach in your spider, consider the concepts from CSS syntax that you’ve used to target the right elements:
| Selector | Effect |
|---|---|
h3 and a |
Targets elements of that HTML element type |
> |
Indicates a child element |
.price_color and article.product_pod |
Indicates a class name and, optionally, specifies on which element the class name should be |
::text |
Targets the text content of a HTML tag |
::attr(href) |
Targets the value of an HTML attribute, in this case the URL in an href attribute |
You can use CSS syntax within selectors to target specific information on websites, be it the text within an element, or even the value of an HTML attribute. At this point, you’ve identified and confirmed shorter CSS selectors that can give you access to all the information that you’re looking for:
| Element | CSS Selector |
|---|---|
| Book elements | article.product_pod |
| URL | h3 > a::attr(href) |
| Title | h3 > a::attr(title) |
| Price | .price_color::text |
That looks a lot more manageable! You can keep these selectors around because you’ll use them in just a bit when writing your spider.
Using the Scrapy shell in this way helps you refine your selectors and ensures that your spider will correctly extract the desired data when you write the actual spider code. This interactive approach saves time and reduces errors in the scraping process.
Build Your Web Scraper With Scrapy
Now that you’ve got a solid understanding of how to inspect websites and have successfully created your Scrapy project, it’s time to build your spider. But writing your spider involves more than just pointing it at a website and letting it loose. You’ll need to carefully weave the spider’s web to ensure it accurately and efficiently collects the data that you need.
In this section, you’ll cover essential concepts such as creating item classes to structure your data, applying selectors to pinpoint the elements that you want to extract, and handling pagination to traverse multi-page datasets. By the end of this section, you’ll not only have a functional web scraper, but you’ll also have a deeper understanding of how to customize and optimize your spiders to handle various web scraping challenges.
Collect the Data in an Item
An Item is a container that defines the structure of the data that you want to collect. It’s a Python mapping, which means that you can assign values similarly to how you would with a Python dictionary.
An Item also provides additional features that are useful for web scraping, such as validation and serialization. Defining an Item for your data helps to organize and standardize the data that you scrape, which means less effort for processing and storing it later.
To start using an item, you need to create a class that inherits from scrapy.Item and define the fields that you want to scrape as instances of scrapy.Field. This approach allows you to specify the data structure in a clean and manageable way.
Note: If you’re familiar with the Django web framework, then you might recognize this way of defining items. It’s utilizing a simplified class definition syntax akin to defining a Django model.
Scrapy even ships with a dedicated DjangoItem that gets its fields definition directly from a Django model.
The default project structure that you created earlier provides a place for defining your item classes in a file called items.py. Open the file and add code to the generated BooksItem class with fields for the URL, title, and price of each book:
books/items.py
import scrapy
class BooksItem(scrapy.Item):
url = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
In this example, BooksItem inherits from Item, and you define .url, .title, and .price as fields. The Field class is a placeholder that’s just an alias to a Python dict. It integrates with Item so that you can use it to define the fields that Item will contain.
Now that you’ve defined BooksItem, you can use it in your spider to collect data. You’ll make use of the selectors that you explored using the shell to help your spider find URLs, book titles, and prices from target website.
Write a Scrapy Spider
It’s finally time to assemble the pieces that you’ve carefully constructed up to now. The framework has another command that you can use to conveniently create a spider within your project. Make sure that you’ve navigated into your project folder called books/, and then run the command to generate your first spider:
(venv) $ cd books/
(venv) $ scrapy genspider book https://books.toscrape.com/
Created spider 'book' using template 'basic' in module:
books.spiders.book
By passing a spider name and the target URL to genspider, Scrapy creates a new file in the spiders/ directory of your project. Open it up and take a look. You’ll see a new class that inherits from scrapy.Spider and has the name you entered, with Spider as a suffix—for example, BookSpider in your case. It also includes some additional scaffolding that you’ll now edit with your specific information.
Any basic spider has a name and needs to provide two more pieces of information:
- Where to start scraping
- How to parse the response
You can provide this information using start_urls and .parse(), respectively. start_urls is a list of strings that contains only one URL in your case, but could contain more. Your favorite web scraping framework already populated this value, and the spider’s name, when you set up the spider scaffolding using genspider.
The .parse() method of a Spider is a callback method that Scrapy calls with the downloaded response object for each URL. It should contain the logic to extract the relevant information from the response. You can work with the CSS selectors that you previously identified to extract the information from the response, then use your BooksItem to collect the data:
books/spiders/book.py
import scrapy
from books.items import BooksItem
class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com/"]
def parse(self, response):
for book in response.css("article.product_pod"):
item = BooksItem()
item["url"] = book.css("h3 > a::attr(href)").get()
item["title"] = book.css("h3 > a::attr(title)").get()
item["price"] = book.css(".price_color::text").get()
yield item
You’ve created a Scrapy spider with only a few lines of code! Note how you reused the code that you wrote in the shell. You only had to collect the information into a BooksItem instance, which you did using dictionary syntax. Finally, you used yield to generate each item.
Note: Using yield turns .parse() into a generator that yields its results rather than returning them. This allows the framework to handle multiple requests and responses concurrently.
Scrapy is built on top of the Twisted framework, which is an event-driven networking engine that allows for asynchronous requests. This makes the scraping process more efficient and scalable.
You set up .parse() so that it first finds all the books on the current page and then iterates over each book. For each book, it creates a BooksItem instance and extracts the URL, title, and price using CSS selectors. It assigns these values to the respective fields of your BooksItem and then yields the item instance to the item pipeline.
In this case, Python will call .parse() only once, but if you were working on a larger scraping project that involved multiple start_urls, then the framework would automatically call it for each of them.
Now that your spider has comfortably settled in its newly built web, you can send it off to fetch data from the Internet.
Extract Data From the Website
You’ve finished piecing your spider together. To run it and see the scraped data, open your terminal and confirm that you’re still in your Scrapy project directory. You can start the spider from there using the crawl command:
(venv) $ scrapy crawl book
Scrapy will start crawling the specified URL. It’ll print a bunch of logging information to your terminal. Nested in between the logs, you should also see the extracted data for each book on the landing page printed out:
2024-08-28 10:26:48 [scrapy.utils.log] INFO: Scrapy 2.11.2 started (bot: books)
...
{'price': '£51.77',
'title': 'A Light in the Attic',
'url': 'catalogue/a-light-in-the-attic_1000/index.html'}
2024-08-28 10:26:50 [scrapy.core.scraper] DEBUG: Scraped from <200 https://books.toscrape.com/>
{'price': '£53.74',
'title': 'Tipping the Velvet',
'url': 'catalogue/tipping-the-velvet_999/index.html'}
2024-08-28 10:26:50 [scrapy.core.scraper] DEBUG: Scraped from <200 https://books.toscrape.com/>
...
2024-08-28 10:26:50 [scrapy.core.engine] INFO: Spider closed (finished)
Great! You successfully scraped and extracted all the URL, title, and price information from the first page of the dummy bookstore! However, that’s just page one of many.
You may wonder whether you’ll have to add each page to start_url or set up a for loop to iterate over all the available pages. Don’t worry, there’s a more robust and straightforward way that’s already built into the framework!
Handle Pagination and Follow URLs
Many websites display data across multiple pages. If your spider can handle pagination and follow URLs, then it can navigate through multiple pages of a website and extract data from each one. In Scrapy, you’ll only need to add a bit of code to your spider so that it can tackle pagination and properly crawl your target website.
Web crawling means to systematically browse the Web to index and collect information. The primary function of a web crawler is to follow links on web pages to discover new content and gather data. In the context of web scraping, a crawler can navigate through different pages of a website, extract relevant information, and store it for further use.
But before you can update your spider, you’ll need to understand how the website handles pagination. Open up your browser or the Scrapy shell and inspect the website to find the pagination controls.
In the Books to Scrape website, you’ll find the pagination links at the bottom of the page:
<li class="next"><a href="catalogue/page-2.html">next</a></li>
The next button links to the next page of results. It’s implemented as a list item (<li>) with a class called "next" that contains a link element (<a>) with the URL of the next page. When you click it, you’ll see that the site loads the next page and displays different book items.
With that knowledge in mind, head back to book.py and modify your existing BookSpider to handle pagination and scrape data from all the result pages:
books/spiders/book.py
import scrapy
from books.items import BooksItem
class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com/"]
def parse(self, response):
for book in response.css("article.product_pod"):
item = BooksItem()
item["url"] = book.css("h3 > a::attr(href)").get()
item["title"] = book.css("h3 > a::attr(title)").get()
item["price"] = book.css(".price_color::text").get()
yield item
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
next_page_url = response.urljoin(next_page)
yield scrapy.Request(url=next_page_url, callback=self.parse)
You started by targeting the href attribute of the relevant element and saving its value to next_page. However, that URL isn’t a fully qualified URL, so you’ll need to combine it with the base URL before Scrapy can send a new request. You do that using .urljoin() inside the conditional block. Finally, you yield a scrapy.Request object, passing it the URL you just concatenated and using the .parse() method as a callback.
This setup allows the framework to make another request to the second page of the bookstore, again using the .parse() method you wrote, thereby continuing the scraping process.
The process will continue recursively until there are no more next links, effectively scraping all the pages of the website.
Your spider is now set up to handle pagination. You can run it again to scrape data from all pages:
(venv) $ scrapy crawl book
Scrapy will start at the first page, extract the desired data, follow the pagination links, and continue extracting data from subsequent pages until it reaches the last page. The output in your terminal will look similar to before, only it’ll take longer and give you the book information for all the books that are present in the bookstore!
Handling pagination and following URLs are essential skills for building effective web crawlers. By incorporating pagination logic into your spider, you ensure that your web scraper can navigate through multiple pages and extract comprehensive data from the target website. This approach allows you to build more powerful and flexible scrapers that can handle a wide range of websites.
Store the Scraped Data in MongoDB
You’ve built a functioning spider that crawls the whole bookstore, following pagination links to extract all the data that you need. Currently, Scrapy is sending that data to the standard error stream (stderr) that you get to see in your terminal.
You could write code to save it to a JSON file, but you’re building a scraper that should be able to handle large amounts of data and continue to work long into the future.
Because of that, it’s usually a good idea to store the data that you scraped in a database. A database can help you to organize and persist the information securely and conveniently. MongoDB is an excellent choice for handling data scraped from the Internet due to its flexibility and capacity to handle dynamic and semi-structured data. In this section, you’ll learn how you can store the scraped data in a MongoDB collection.
Set Up a MongoDB Collection on Your Computer
Before you can start using MongoDB, you need to install it on your system. The installation process differs depending on your operating system, so make sure to follow the instructions appropriate for your operating system.
Note: For more detailed instructions and additional configuration options, you can refer to the comprehensive Introduction to MongoDB and Python.
After you’ve successfully installed MongoDB, you can verify your installation using your terminal:
$ mongod --version
db version v7.0.12
Build Info: {
"version": "7.0.12",
"gitVersion": "b6513ce0781db6818e24619e8a461eae90bc94fc",
"modules": [],
"allocator": "system",
"environment": {
"distarch": "aarch64",
"target_arch": "aarch64"
}
}
The exact output that you’ll get depends on the version you’ve installed, as well as your operating system. But it’ll look similar to the output that you can see above. If your terminal gives you an error message instead, then you’ll need to double-check your installation and try again.
If this is your first time using MongoDB, then you may need to perform a few setup tasks to prepare it for storing data.
By default, MongoDB stores data in /data/db. You may need to create this directory and ensure it has the correct permissions. For example:
$ sudo mkdir -p /data/db
$ sudo chown -R `id -u` /data/db
If MongoDB isn’t already running, then you can start it with the mongod command. This will start the MongoDB server and bind it to the default port 27017.
To interact with your MongoDB instance, you can use the MongoDB shell by running mongosh in your terminal. This will connect you to the MongoDB server and allow you to perform database operations:
$ mongosh
Current Mongosh Log ID: 66868598a3dbed30a11bb1a2
Connecting to: mongodb://127.0.0.1:27017/?directConnection=true&serverSelectionTimeoutMS=2000&appName=mongosh+2.2.10
Using MongoDB: 7.0.12
Using Mongosh: 2.2.10
For mongosh info see: https://docs.mongodb.com/mongodb-shell/
test>
In the MongoDB shell, you want to create a new database with a new collection. You’ll call the database books_db and the collection books:
test> use books_db
switched to db books_db
books_db> db.createCollection("books")
{ ok: 1 }
books_db> show collections
books
books_db>
With your new database and collection in place, you’re ready to dive back into Scrapy to connect your spider to MongoDB. You’ll set it up so that all the scraped data will find its way into your new books collection.
Connect to a MongoDB Database From Scrapy
You’ll use the third-party library pymongo to connect to your MongoDB database from within your Scrapy project. First, you’ll need to install pymongo from PyPI:
(venv) $ python -m pip install pymongo
After the installation is complete, you’re ready to add information about your MongoDB instance to your Scrapy project.
When you created your project, you also got a file named settings.py. It’s a central place that allows you to define settings for your project, and it already contains some information. It also contains a lot of notes about what additional settings you can use it for.
One use case for settings.py is to connect the web scraping framework to a database. Open up settings.py and add the MongoDB connection details at the bottom of the file:
books/settings.py
# ...
MONGO_URI = "mongodb://localhost:27017"
MONGO_DATABASE = "books_db"
You’ll later load these variables into your pipeline and use them to connect to the books_db database running on your local computer. If you’re connecting to a hosted MongoDB instance, then you’ll have to adapt the information accordingly.
Process the Data Through a Scrapy Pipeline
Scrapy’s item pipelines are a powerful feature that allows you to process the scraped data before you store it or process it further. Pipelines facilitate various post-processing tasks such as cleaning, validation, and storage. In this section, you’ll create an item pipeline to store scraped data in your new MongoDB collection, echoing the load process of a ETL workflow.
An item pipeline is a Python class that defines several methods to process items after your spider has scraped them from the Internet:
.open_spider()gets called when the spider opens..close_spider()gets called when the spider closes..process_item()gets called for every item pipeline component. It must either return an item or raise aDropItemexception..from_crawler()creates a pipeline from aCrawlerin order to make the general project settings available to the pipeline.
You’ll implement all of these methods when building your custom pipeline to insert the scraped items into your MongoDB collection. While loading data into a database is one possible use case of an item pipeline, you can also use them for other purposes, such as cleaning HTML data or validating scraped data.
Note: From the perspective of the ETL process, an item pipeline can serve for both transform and load operations.
You already installed MongoDB and pymongo, created a collection, and added the MongoDB-specific settings to your project’s settings.py file. Next, you’ll define a pipeline class in books/pipelines.py. This pipeline will connect to MongoDB and insert the scraped items into the collection:
books/pipelines.py
import pymongo
from itemadapter import ItemAdapter
class MongoPipeline:
COLLECTION_NAME = "books"
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get("MONGO_URI"),
mongo_db=crawler.settings.get("MONGO_DATABASE"),
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
self.db[self.COLLECTION_NAME].insert_one(ItemAdapter(item).asdict())
return item
You’ve added what may seem like a big chunk of code. However, most of it is boilerplate code. Here’s what each piece does:
-
itemadapterwraps different data containers to handle them in a uniform manner. The package was installed as a dependency of Scrapy. -
COLLECTION_NAMEspecifies the name of the MongoDB collection where you want to store the items. This should match the name of the collection that you set up earlier. -
.__init__()initializes the pipeline with the MongoDB URI and database name. You can access this information because you’re fetching it from theCrawlerusing the.from_crawler()class method. -
.from_crawler()is a class method that gives you access to all core Scrapy components, such as the settings. In this case, you use it to retrieve the MongoDB settings fromsettings.pythrough the Scrapy crawler. -
.open_spider()opens a connection to MongoDB when the spider starts. -
.close_spider()closes the MongoDB connection when the spider finishes. -
.process_item()inserts each scraped item into the MongoDB collection. This method usually contains the core functionality of a pipeline.
With your MongoPipeline in place, you’ll still need to activate it in the context of your project so that the framework will use it on the next run.
To enable the pipeline, you need to add it to your project settings in settings.py.
When you generate a Scrapy project scaffolding using scrapy startproject, your settings.py file already includes an entry for ITEM_PIPELINES. Like most settings in that file, it’s commented-out. You can find that entry and remove the Python comment, then add the qualified name location of your new pipeline object:
ITEM_PIPELINES = {
"books.pipelines.MongoPipeline": 300,
}
You can add pipelines to your project as entries in a dictionary, where the qualified name of your pipeline class is the key, and an integer is the value. The integer determines the order in which Scrapy runs the pipelines. Lower numbers mean higher priority.
Note: Using 300 is a convention that indicates to developers that this number is flexible and that they can use a wide range above and below it to order the priorities of your pipelines.
By defining an item pipeline, you can integrate both transform and load operations seamlessly into your web scraping tasks. With your MongoDB connection set up in your project, it’s time to run the scraper another time and assess whether it works as expected.
Avoid Adding Duplicate Entries
When you run your scraper the first time, everything should work as expected. Scrapy fills your MongoDB collection with the information from the website. If you check the length of your collection after the initial run in the Mongo shell, then you’ll see that it holds 1000 documents:
books_db> db.books.countDocuments()
1000
However, if you run the scraper another time, then your books database has doubled in length and now holds two thousand documents. This problem exists because by default, MongoDB creates a unique ID for each document based on timestamps, among other information. Therefore, it’ll consider each scraped item as a new document and assign it a new ID, which leads to data duplication in your database.
This might be what you want in some projects, but here you want to keep each scraped book item only once, even if you run the scraper multiple times. For that, you’ll need to create and specify a unique ID field for your data that MongoDB can use to identify each document.
Open up books/pipelines.py again and add the logic necessary to check for duplicates based on a new unique id field that you’ll derive from hashing the individual page URL:
books/pipelines.py
1import hashlib
2import pymongo
3from itemadapter import ItemAdapter
4from scrapy.exceptions import DropItem
5
6class MongoPipeline:
7 COLLECTION_NAME = "books"
8
9 def __init__(self, mongo_uri, mongo_db):
10 self.mongo_uri = mongo_uri
11 self.mongo_db = mongo_db
12
13 @classmethod
14 def from_crawler(cls, crawler):
15 return cls(
16 mongo_uri=crawler.settings.get("MONGO_URI"),
17 mongo_db=crawler.settings.get("MONGO_DATABASE"),
18 )
19
20 def open_spider(self, spider):
21 self.client = pymongo.MongoClient(self.mongo_uri)
22 self.db = self.client[self.mongo_db]
23
24 def close_spider(self, spider):
25 self.client.close()
26
27 def process_item(self, item, spider):
28 item_id = self.compute_item_id(item)
29 if self.db[self.COLLECTION_NAME].find_one({"_id": item_id}):
30 raise DropItem(f"Duplicate item found: {item}")
31 else:
32 item["_id"] = item_id
33 self.db[self.COLLECTION_NAME].insert_one(ItemAdapter(item).asdict())
34 return item
35
36 def compute_item_id(self, item):
37 url = item["url"]
38 return hashlib.sha256(url.encode("utf-8")).hexdigest()
To avoid gathering duplicate elements on multiple scraper runs, you’ve applied updates to .process_item() and added the new helper method .compute_item_id():
-
Lines 1 and 4 hold two new imports, one for the standard library
hashlibmodule that you use for processing the URLs into unique identifiers in.compute_item_id(). The second import bringsDropItemfromscrapy.exceptions, which is a quick way to drop duplicate items and write to Scrapy’s logs. -
Line 28 calls
.compute_item_id()and assigns the hashed output toitem_id. -
Lines 29 and 30 query the MongoDB collection to check if an item with the same
_idalready exists. If Python finds a duplicate, then the code raises aDropItemexception, which tells the framework to discard this item and not to process it further. If it doesn’t find a duplicate, then it proceeds to the next steps. -
Lines 31 to 34 make up the
elsecondition, where the scraped item doesn’t yet exist in the database. This code is nearly the code that you had before adding deduplication logic, however with an important difference. Before inserting the item into your collection, you add the calculateditem_idas the value for the._idattribute to yourItem. MongoDB uses a field named_idas the primary key, if it’s present.
Note that just like before, the method returns the item. This allows for further processing by other pipelines if you were to build any.
Before you can run your updated pipeline, you’ll have to account for the new _id field on a BooksItem. Open up books/items.py and add it to your item definition:
books/items.py
import scrapy
class BooksItem(scrapy.Item):
_id = scrapy.Field()
url = scrapy.Field()
title = scrapy.Field()
price = scrapy.Field()
You don’t need to change anything in your spider, and you’re now populating each BooksItem from two different places in your code:
- Your spider adds values for
.url,.title, and.priceto aBooksItem. - Your item pipeline adds the value for
._id, after calculating it from.url.
That’s a nice example of the power and flexibility that using Scrapy’s built-in processes offers you when building your web scraper.
As briefly mentioned, .compute_item_id() uses Python’s hashlib to hash the URL value. Using the hashed URL as a unique identifier means that Python won’t add any book that you scraped twice from the same URL to your collection.
What you consider a unique identifier is a design decision that you’ll have to think about individually for each project. In this case, using the hashed URL works well because you’re working with a dummy bookstore where each book resource has a unique URL. However, if the data for any of these books changed—while keeping the same URL—then the current implementation would drop that item.
If dropping the item in such a case isn’t the intended behavior, then you could update your code by using an upsert operation instead. In MongoDB, you can perform upserts using db.collection.updateOne() with upsert set to true. pymongo translates this operation into Python code:
books/pipelines.py
# ...
def process_item(self, item, spider):
item_id = self.compute_item_id(item)
item_dict = ItemAdapter(item).asdict()
self.db[self.COLLECTION_NAME].update_one(
filter={"_id": item_id},
update={"$set": item_dict},
upsert=True
)
return item
# ...
When you use this setup, then you don’t even need to update your BooksItem because it bypasses the item adapter and creates the document’s _id directly when interacting with MongoDB.
When you use .update_one() with pymongo, then you need to pass two main arguments:
- The filter to find the document in your collection
- The update operation
The third argument that you provide, upsert=True, assures that MongoDB will insert the item if it doesn’t exist. As mentioned, you don’t have to explicitly add the value for _id to your BooksItem, because .update_one() takes that value from the filter argument and only uses it to create the documents in your collection.
You’ll have to drop your existing collection, which still contains the timestamp-based IDs, before this code will have the intended effect:
books_db> db.books.drop()
true
books_db> db.books.countDocuments()
0
Now you can go ahead and run your scraper a couple more times, then check how many documents you have in your collection. The number should always stay at one thousand.
Keep in mind that which approach you choose may depend on the project that you’re working on. Either way, you now have a better idea how you can drop duplicate items and updating existing entries with new data.
Debug and Test Your Scrapy Web Scraper
You’ll likely run into situations where your scraper doesn’t do what you’d expect it to do. Web scraping projects always deal with multiple factors that can lead to unexpected results. Debugging will likely be an essential part of your scraper development process. Scrapy provides several powerful tools to help you debug your spiders and ensure they work as intended.
Writing tests for your spider ensures that your code will continue to work as expected. Testing is a crucial part of any software development process, and web scraping is no exception.
In this section, you’ll cover how to use Scrapy’s debugging and testing tools, including the logging feature, the Scrapy shell, an error callback function, and spider contracts. You’ll also write some custom unit tests to confirm that your spider works as expected.
Log Information With the Logger
Logging is a fundamental tool for understanding what your spider is doing at each step. By default, the framework logs various events, but you can customize the logging to fit your needs. Scrapy uses Python’s logging library that comes as part of the standard library. You don’t even need to import it, because spider objects already have access to a logger.
Open up your book.py file and add logging to keep track of when your spider navigates to a new page:
books/book.py
# ...
def parse(self, response):
for book in response.css("article.product_pod"):
item = BooksItem()
item["url"] = book.css("h3 > a::attr(href)").get()
item["title"] = book.css("h3 > a::attr(title)").get()
item["price"] = book.css(".price_color::text").get()
yield item
next_page = response.css("li.next > a::attr(href)").get()
if next_page:
next_page_url = response.urljoin(next_page)
self.logger.info(
f"Navigating to next page with URL {next_page_url}."
)
yield scrapy.Request(url=next_page_url, callback=self.parse)
# ...
You’ve added code that accesses the .logger from your BookSpider and logs information when the spider navigates to a new page with the INFO logging level.
By default, the framework logs with DEBUG severity, which can be helpful for debugging, but potentially overwhelming when you see it on every run. Now that you’ve added a debug message of a higher severity, you can switch to that level to only see messages of INFO and higher severity printed to your console.
You can configure logging in your spider directly through constants in settings.py:
books/settings.py
# ...
LOG_LEVEL = "INFO"
After you’ve added this line to settings.py, run your scraper another time. You won’t see any debug information, but only logs of a severity of INFO and higher.
If you’re running the spider while populating an empty collection, then you’ll only get the info that Scrapy navigated to a different page.
However, you’ll see different output if you run it a second time, depending on which deduplication logic you decided to keep in MongoPipeline.process_item():
-
If you’re working with upserts and pymongo’s
.update_one(), then you’ll see just the log messages when Scrapy navigates to a new page. -
If you’re still working with an explicit
._idfield andDropItem, then you’ll get overwhelmed with WARNING logs. Scrapy automatically writes a WARNING when it catches aDropItemexception.
Logging all warnings is probably a good idea, and you may want to keep the log file around for later inspection. You can set a value for LOG_FILE in Scrapy’s settings to write to a file instead of to stderr, and adapt the LOG_LEVEL again so that Python only writes warnings to the log file:
books/settings.py
# ...
LOG_LEVEL = "WARNING"
LOG_FILE = "book_scraper.log"
With these two settings, you customized the logging level and the log file location in your Scrapy project.
Setting LOG_LEVEL to "WARNING" means that Python will only log messages of higher severity. The LOG_FILE setting specifies the file where Scrapy will save the logs.
If you now run your spider, you won’t see any output in your console. Instead, a new file pops up into which Scrapy writes information about all the dropped items—assuming that you’re working with the code that uses DropItem:
book_scraper.log
2024-08-28 13:11:32 [scrapy.core.scraper] WARNING: Dropped: Duplicate item found: {'price': '£51.77',
'title': 'A Light in the Attic',
'url': 'catalogue/a-light-in-the-attic_1000/index.html'}
{'price': '£51.77',
'title': 'A Light in the Attic',
'url': 'catalogue/a-light-in-the-attic_1000/index.html'}
...
If you’re working with upserts, then you should see an empty log file. Good to know that nothing went wrong!
Logging can help you trace the flow of your spider, inspect variable values, and identify where things might be going wrong. It’s often a good idea to set the logging level to DEBUG and write logs to a file, to allow you to retrace what your spider did in case it ends up failing on a run.
Handle Errors With errback
Scrapy allows you to handle errors gracefully using an error callback function. If you pass a method to the errback parameter of a Request object, then Scrapy will use it to handle exceptions. This is especially helpful when dealing with network errors or unexpected server responses, and you can use it to log the error without terminating your program.
Open up book.py and add a new method to your spider to handle errors:
book/spiders/book.py
import scrapy
from books.items import BooksItem
class BookSpider(scrapy.Spider):
# ...
def log_error(self, failure):
self.logger.error(repr(failure))
In .log_error(), you catch the exception and log it with a severity level of ERROR. This can help you in diagnosing issues without stopping the spider’s execution.
Next, you need to integrate your new method into the code. To catch errors that happen when making requests, you need to specify the errback parameter additionally to callback. That way, you can ensure that Scrapy handles errors using your .log_error() method:
book/spiders/book.py
# ...
def parse(self, response):
# ...
if next_page:
next_page_url = response.urljoin(next_page)
self.logger.info(
f"Navigating to next page with URL {next_page_url}."
)
yield scrapy.Request(
url=next_page_url,
callback=self.parse,
errback=self.log_error,
)
By passing the name of your error callback method to scrapy.Request, you ensure that any requests for further pages of the book store that return an error will get logged.
If you also want to use .log_error() for the initial request to Books to Scrape, then you need to refactor your code to use .start_requests() instead of only relying on .start_urls:
book/spiders/book.py
# ...
class BookSpider(scrapy.Spider):
name = "book"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com/"]
def start_requests(self):
for url in self.start_urls:
yield scrapy.Request(
url, callback=self.parse, errback=self.log_error
)
def parse(self, response):
# ...
By adding .start_requests(), you gain additional flexibility on how to handle the initial request to each URL in start_urls. Scrapy only calls this method once for each start URL. In this example, you added your new .log_error() method also to that initial request by passing it to errback. If you define your own error handling with errback, then you can efficiently troubleshoot and refine error conditions in your web scraping spiders.
After you’ve explored a few debugging tools that Scrapy offers, you’ll now take a look at how you can write tests to ensure that your scraper works as intended.
Sign Some Spider Contracts
Scrapy offers a feature known as contracts, allowing you to embed test cases directly within your spider’s docstrings. Similar to Python’s doctest, this feature enables quick validation of spider methods, ensuring that they work as expected without requiring extensive test setups.
Spider contracts are essentially assertions that you can place in the docstring of your spider methods. They define the expected behavior of the methods:
@urlspecifies the URL that Scrapy should fetch.@returnsindicates the expected number of items or requests that the spider should return.@scrapeslists the fields that the items should contain.
Open up your book.py file and add a contract to your .parse() method:
books/spiders/book.py
# ...
def parse(self, response):
"""
@url https://books.toscrape.com
@returns items 20 20
@returns request 1 50
@scrapes url title price
"""
for book in response.css("article.product_pod"):
# ...
You’ve added four contracts to the docstring of .parse():
@url https://books.toscrape.comtells Scrapy to fetch the specified URL to test the parse method. This contract is required for any of the other tests to run.@returns items 20 20specifies that the method should return exactly twenty items. The first number is the minimum expected items, and the second is the maximum.@returns request 1 50means that.parse()should generate at least one and at most fifty requests. This part is relevant for the pagination code that you set up.@scrapes url title pricespecifies that each returned item should contain the fieldsurl,title, andprice.
With just these four lines, you’ve set up basic tests for .parse() that can help you spot issues with your scraper early on.
Note: There’s another built-in contract, @cb_kwargs, that you didn’t use in this case, but that may be helpful when you need to set the keyword arguments for the sample request. You can also write custom contracts.
To execute the contract tests, you can use the check command in your terminal:
(venv) $ scrapy check book
...
----------------------------------------------------------------------
Ran 3 contracts in 1.399s
OK
When running this command, Scrapy fetches the specified URL, executes .parse(), and validates the results against the assertions in the docstring. If any of the assertions fail, then the framework will output an error message indicating what went wrong.
Note that the @url contract is a prerequisite for the other contracts to run successfully. Scrapy doesn’t list it as a test condition in the output, which is why the message reads that Scrapy ran three contracts.
If any of the contracts fail, Scrapy will provide details about the failure, such as the number of items that didn’t meet the specified expectations. Go ahead and edit your contracts to inspect what a failing test looks like. If you’re familiar with Python’s unittest module, then you’ll likely recognize the output. Under the hood, contracts use unittest to organize and execute the tests.
In short, spider contracts come with a few benefits, such as:
-
Quick Validation: Contracts provide a quick way to validate your spiders without setting up extensive test frameworks. This is particularly useful during development when you want to ensure that your spider methods are working correctly.
-
Documentation: The docstrings with contracts serve as documentation, making it clear what the expected behavior of your spider methods is. This can be beneficial for team members or when revisiting the code after some time.
-
Automated Testing: Contracts can be integrated into your automated testing pipeline, ensuring that your spiders continue to work correctly as you make changes to your codebase.
By incorporating spider contracts into your development process, you can enhance the reliability and maintainability of your web scrapers, making sure that they perform as expected under various conditions.
Write Unit Tests for Detailed Testing
Spider contracts are a great way to create quick tests. However, if you’re working with a complex scraper and you want to check its functionality in more detail, it can be a good idea to write unit tests to test individual components.
Note: A popular option for unit testing in Python is the third-party library pytest. However, you’ll continue to work with Python’s built-in unittest library. Scrapy uses it for contracts, and hey—it already comes packaged with Python!
To write unit tests for the BookSpider methods, you need to simulate the Scrapy environment. This involves mocking responses and requests to ensure that your spider methods behave as expected.
Inside your top-level books/ project folder, create a tests/ folder. Inside of that folder, create two files:
__init__.pyinitializes the folder as a Python package.test_book.pywill hold the unit tests for your scraper.
Now, take a moment to think about what aspects of your scraper you’d like to test. It may be useful to reconsider what your spider contracts already cover, then build on top of that with added specificity.
For example, while there are contracts that check the number of items scraped per page, and the elements that Scrapy extracts, you don’t have any checks for whether these are the right items. Your contracts don’t know anything about the content of the elements it extracts. It could be a good idea to write a unit test to fill that gap.
Additionally, you may want to confirm that each call to .parse() identifies the right elements from the HTML, fetches all books, and creates a new request for the pagination URL:
tests/test_book.py
import unittest
class BookSpiderTest(unittest.TestCase):
def test_parse_scrapes_all_items(self):
"""Test if the spider scrapes books and pagination links."""
pass
def test_parse_scrapes_correct_book_information(self):
"""Test if the spider scrapes the correct information for each book."""
pass
def test_parse_creates_pagination_request(self):
"""Test if the spider creates a pagination request correctly."""
pass
if __name__ == "__main__":
unittest.main()
With your intentions set and a basic test class structure in place, you can go ahead and write your test code. Your tests will often benefit from a .setUp() method that creates the necessary setup that each test needs to function properly.
For these unit tests, you want to check against a small sample of the page’s HTML. You’ll also need access to your book spider, and some of the classes that the framework uses internally to handle requests and responses. As you’ll need this setup for each test, it’s a good candidate to move into a .setUp() method:
tests/test_book.py
import unittest
from scrapy.http import HtmlResponse
from books.spiders.book import BookSpider
class BookSpiderTest(unittest.TestCase):
def setUp(self):
self.spider = BookSpider()
self.example_html = """
Insert the example HTML here
"""
self.response = HtmlResponse(
url="https://books.toscrape.com",
body=self.example_html,
encoding="utf-8"
)
# ...
The .setUp() method initializes a BookSpider instance before each test, creates an example HTML string, containing two book entries and a link to the next page. It then mocks a request to the site by returning an HtmlResponse object with that sample HTML. You want the example HTML to be as close to the real page HTML as possible, without overwhelming your codebase.
You can fetch the sample HTML that this tutorial uses from the downloadable materials in books/tests/sample.html:
Get Your Code: Click here to download the free code that shows you how to gather Web data with Scrapy and MongoDB.
This excerpt from the landing page of Books to Scrape contains two full book elements and the pagination link, but is otherwise stripped down so that the string doesn’t get unnecessarily long. Add this HTML snippet in between the triple-double quotation marks to assign it to self.example_html.
Note: If you want to use the full page HTML, then you can also fetch that with your browser, requests, or Scrapy and save it as a string variable. The results should be the same.
However, keep in mind that if you fetch the content every time your test script runs, it poses a performance penalty and will only work if you’re connected to the Internet.
With your setup in place, you can make your first test fail:
tests/test_book.py
# ...
class BookSpiderTest(unittest.TestCase):
# ...
def test_parse_scrapes_all_items(self):
"""Test if the spider scrapes all books and pagination links."""
# There should be two book items and one pagination request
book_items = []
pagination_requests = []
self.assertEqual(len(book_items), 2)
self.assertEqual(len(pagination_requests), 1)
If you run your test code at this point, you’ll get one failed and two passed tests. Navigate into your top-level books/ directory, if you’re not already there, then run the unittest command:
(venv) $ python -m unittest
.F.
======================================================================
FAIL: test_parse_scrapes_all_items (tests.test_book.BookSpiderTest.test_parse_scrapes_all_items)
Test if the spider scrapes all items including books and pagination links.
----------------------------------------------------------------------
Traceback (most recent call last):
File "/path/to/books/tests/test_book.py", line 169, in test_parse_scrapes_all_items
self.assertEqual(len(book_items), 2)
AssertionError: 0 != 2
----------------------------------------------------------------------
Ran 3 tests in 0.011s
FAILED (failures=1)
The empty tests pass because they don’t contain any assertions yet. Your .test_parse_scrapes_all_items() fails because you’re not yet calling the .parse() method and handling its return value. Hop back into the code and add the missing pieces to make your test pass:
tests/test_book.py
# ...
from scrapy.http import HtmlResponse, Request
from books.items import BooksItem
class BookSpiderTest(unittest.TestCase):
# ...
def test_parse_scrapes_all_items(self):
"""Test if the spider scrapes all books and pagination links."""
# Collect the items produced by the generator in a list
# so that it's possible to iterate over it more than once.
results = list(self.spider.parse(self.response))
# There should be two book items and one pagination request
book_items = [item for item in results if isinstance(item, BooksItem)]
pagination_requests = [
item for item in results if isinstance(item, Request)
]
self.assertEqual(len(book_items), 2)
self.assertEqual(len(pagination_requests), 1)
You start by adding an import for Request from scrapy.http. You’re using this class to compare whether the pagination request that the framework should generate is part of the results. You’ll also want to confirm that Scrapy gathers the book info in a BooksItem, so you import that from books.items.
Keep in mind that .parse() is a generator. For convenience, you collect all the items it yields into a list. Then, you add two list comprehensions that assemble all dicts and Request objects into the two lists that you created earlier when setting up the outline of this test method. The sample HTML contains two book items and one pagination URL, so that’s what you’re checking against in your assertions.
Note: If you used the full page HTML for your test, then you should receive twenty book items and still only one pagination request. You’ll have to adapt your assertion accordingly for the test to pass.
You can now run unittest another time, and all three tests should pass:
(venv) $ python -m unittest
...
----------------------------------------------------------------------
Ran 3 tests in 0.011s
You can continue developing the other two test methods using a similar approach. In the collapsible section below, you can find an example implementation:
You can copy the code below and paste it into your test_book.py file:
tests/test_book.py
import unittest
from scrapy.http import HtmlResponse, Request
from books.items import BooksItem
from books.spiders.book import BookSpider
class BookSpiderTest(unittest.TestCase):
def setUp(self):
self.spider = BookSpider()
self.example_html = """
Insert the example HTML here
"""
self.response = HtmlResponse(
url="https://books.toscrape.com",
body=self.example_html,
encoding="utf-8",
)
def test_parse_scrapes_all_items(self):
"""Test if the spider scrapes all books and pagination links."""
# Collect the items produced by the generator in a list
# so that it's possible to iterate over it more than once.
results = list(self.spider.parse(self.response))
# There should be two book items and one pagination request
book_items = [
item for item in results if isinstance(item, BooksItem)
]
pagination_requests = [
item for item in results if isinstance(item, Request)
]
self.assertEqual(len(book_items), 2)
self.assertEqual(len(pagination_requests), 1)
def test_parse_scrapes_correct_book_information(self):
"""Test if the spider scrapes the correct information for each book."""
results_generator = self.spider.parse(self.response)
# Book 1
book_1 = next(results_generator)
self.assertEqual(
book_1["url"], "catalogue/a-light-in-the-attic_1000/index.html"
)
self.assertEqual(book_1["title"], "A Light in the Attic")
self.assertEqual(book_1["price"], "£51.77")
# Book 2
book_2 = next(results_generator)
self.assertEqual(
book_2["url"], "catalogue/tipping-the-velvet_999/index.html"
)
self.assertEqual(book_2["title"], "Tipping the Velvet")
self.assertEqual(book_2["price"], "£53.74")
def test_parse_creates_pagination_request(self):
"""Test if the spider creates a pagination request correctly."""
results = list(self.spider.parse(self.response))
next_page_request = results[-1]
self.assertIsInstance(next_page_request, Request)
self.assertEqual(
next_page_request.url,
"https://books.toscrape.com/catalogue/page-2.html",
)
if __name__ == "__main__":
unittest.main()
Note that you’ll still need to update the value for .example_html with the sample HTML that you can find in books/tests/sample.html in the downloadable resources:
Get Your Code: Click here to download the free code that shows you how to gather Web data with Scrapy and MongoDB.
This setup ensures that individual components of the BookSpider are tested for correctness, helping to identify and fix issues early in the development process.
Handle Common Web Scraping Challenges
Web scraping can be a powerful tool, but it’s often not as straightforward as you’d hope. Whether you’re dealing with dynamically generated content or need to navigate around anti-scraping mechanisms, being prepared to tackle these obstacles is essential for building a robust and reliable web scraper.
In this section, you’ll explore some of the most common challenges that you may encounter. You’ll also get to know some practical solutions to overcome them using Scrapy and its extensive ecosystem.
Equipped with these tools and best practices, you’ll be better prepared to build resilient scrapers capable of extracting valuable data also from more challenging websites.
Retry Failed Requests
Web scraping often involves sending numerous requests to web servers. Some of these requests may result in connection errors due to network issues, server downtime, or temporary blocks from the target site. These errors can disrupt the scraping process and lead to incomplete data collection. Implementing robust retry logic in your project helps to make sure that temporary issues don’t cause your spider to fail.
Scrapy provides built-in support for retrying requests that encounter certain types of errors. This RetryMiddleware is enabled by default, so for many cases you won’t need to do anything, and Scrapy will automatically retry common failed requests for you. The middleware retries failed requests a specified number of times before giving up, increasing the chances of successful data extraction.
If you need to customize the behavior of the RetryMiddleware, then you can conveniently do so right within your settings.py file. Of the available configuration options, there are three that you may want to adjust for your project:
RETRY_ENABLED: Enables or disables the retry middleware. It’s enabled by default.RETRY_TIMES: Specifies the maximum number of retries for a failed request. By default, the framework retries a failed request twice.RETRY_HTTP_CODES: Defines the HTTP response codes that should trigger a retry.
As mentioned, Scrapy retries your requests by default, but if you need to configure the retry middleware for your Scrapy project outside the default, then you can modify these values in the settings.py file:
books/settings.py
# ...
RETRY_TIMES = 3
RETRY_HTTP_CODES = [500, 429]
In this example, you changed the number of retries per request to 3 and adapted the default HTTP codes so that Scrapy only retries requests when it receives HTTP 500 (Internal Server Error) and 429 (Too Many Requests) error codes. However, sticking with the default settings that Scrapy implements is usually a good idea for most scraper projects.
In short, Scrapy handles retry logic for you by default through its built-in RetryMiddleware, which you can also customize. Because of that, you can achieve more reliable data extraction and reduce the impact of transient problems.
Deal With Dynamic Content
Scraping dynamic content, such as pages rendered by JavaScript, presents a unique set of challenges. Traditional web scraping techniques that rely on static HTML don’t work when you’re dealing with content that’s dynamically generated. There are a few approaches that you can take to still get access to the data that you’re interested in:
-
Reproduce requests: Often, your browser fetches the data that you need through API calls in the background. By inspecting the network requests made by the browser using the developer tools in your browser, you can identify these API endpoints and directly make similar requests from your scraper. This bypasses the need for JavaScript rendering and is more efficient.
-
Use Splash to pre-render JavaScript: Splash is a headless browser designed specifically for web scraping. It allows you to render JavaScript and capture the resultant HTML. Scrapy has a dedicated middleware for Splash, called scrapy-splash, which allows you to seamlessly integrate it in your project.
-
Automate a browser: Tools like Selenium and Playwright provide full browser automation, including JavaScript execution. Selenium is well-established and widely used, while Playwright offers newer, faster, and more reliable alternatives with built-in support for multiple browsers. Scrapy can be integrated with Playwright using the
scrapy-playwrightpackage.
While scraping content from JavaScript-rendered pages certainly increases the difficulty for your web scraping project, Scrapy provides you with helpful integrations that will help you get the job done.
Manage Anti-Scraping Mechanisms
Many websites employ anti-scraping measures to protect their data and ensure fair use of their resources. You can circumvent some of these measures with a varying degree of effort.
Scrapy allows you to customize some of the most commonly used approaches directly in a project’s settings.py file.
Websites often block requests from clients with no or default user-agent headers. Setting a custom user-agent in your project settings can help mimic a real browser:
books/settings.py
# ...
USER_AGENT = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3"
You can also use a middleware to rotate user agents and proxies, which can help distribute requests and reduce the chances of getting blocked:
books/settings.py
# ...
DOWNLOADER_MIDDLEWARES = {
"scrapy.downloadermiddlewares.useragent.UserAgentMiddleware": None,
"scrapy_user_agents.middlewares.RandomUserAgentMiddleware": 400,
}
# ...
Finally, you can introduce delays between requests, which can also help to avoid triggering anti-bot measures:
books/settings.py
# ...
DOWNLOAD_DELAY = 2
If a site builds a lot of defenses against web scrapers, then you might want to consider whether it’s really a good idea to scrape it. For any site that you plan on scraping, you should always check and adhere to its robots.txt file. This file specifies the site’s permissions for web crawlers. Scrapy also has a setting for this, which is enabled by default:
books/settings.py
# ...
ROBOTSTXT_OBEY = True
# ...
By applying these techniques and configurations, you can tackle common challenges in web scraping, ensuring your scrapers are robust, efficient, and respectful of the websites that you interact with.
Conclusion
By following this tutorial, you’ve successfully used Scrapy and MongoDB for a complete web scraping project that follows the ETL process. Nice work!
You’ve learned about a wide array of Scrapy’s functionalities, including what testing capabilities it ships with, and how you can extend on top of them. You’ve also gained insight on how to handle common web scraping challenges, such as managing retries, dealing with dynamic content, and circumventing anti-scraping mechanisms.
In this tutorial, you learned how to:
- Set up and configure a Scrapy project
- Build a functional web scraper with Scrapy
- Extract data from websites using selectors
- Store scraped data in a MongoDB database
- Test and debug your Scrapy web scraper
With these skills, you’re well-equipped to tackle a variety of web scraping projects, leveraging the efficiency of Scrapy and the flexibility of MongoDB. Whether you’re collecting data for research, building a data-driven application, or just exploring the web, the knowledge and tools you have gained from this tutorial will serve you well. Keep scraping and stay respectful!
Get Your Code: Click here to download the free code that shows you how to gather Web data with Scrapy and MongoDB.
Take the Quiz: Test your knowledge with our interactive “Web Scraping With Scrapy and MongoDB” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Web Scraping With Scrapy and MongoDBIn this quiz, you'll test your understanding of web scraping with Scrapy and MongoDB. You'll revisit how to set up a Scrapy project, build a functional web scraper, extract data from websites, store scraped data in MongoDB, and test and debug your Scrapy web scraper.








