Python’s namedtuple in the collections module allows you to create immutable sequences with named fields, providing a more readable and Pythonic way to handle tuples. You use namedtuple to access values with descriptive field names and dot notation, which improves code clarity and maintainability.
By the end of this tutorial, you’ll understand that:
- Python’s
namedtupleis a factory function that creates tuple subclasses with named fields. - The main difference between
tupleandnamedtupleis thatnamedtupleallows attribute access via named fields, enhancing readability. - The point of using
namedtupleis to improve code clarity by allowing access to elements through descriptive names instead of integer indices. - Some alternatives to
namedtupleinclude dictionaries, data classes, andtyping.NamedTuple.
Dive deeper into creating namedtuple classes, exploring their powerful features, and writing Python code that’s easier to read and maintain.
Get Your Code: Click here to download the free sample code that shows you how to use namedtuple to write Pythonic and clean code.
Take the Quiz: Test your knowledge with our interactive “Write Pythonic and Clean Code With namedtuple” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Write Pythonic and Clean Code With namedtupleIn this quiz, you'll test your understanding of Python's namedtuple() factory function from the collections module.
Getting to Know namedtuple in Python
Python’s namedtuple() is a factory function that’s available in the collections module. It allows you to create a tuple subclass with named fields. These named fields let you to access the values in a given named tuple using dot notation and field names—for example, my_tuple.field_name.
Python’s namedtuple was created to improve code readability by providing a way to access values using descriptive field names instead of integer indices, which often don’t provide any context on what the values are. This feature also makes the code cleaner and more maintainable.
In contrast, accessing values by index in a regular tuple can be frustrating, hard to read, and error-prone. This is especially true if the tuple has a lot of fields and is constructed far away from where you’re using it.
Note: In this tutorial, you’ll find different terms used to refer to Python’s namedtuple, its factory function, and its instances.
To avoid confusion, here’s a summary of how each term is used throughout the tutorial:
| Term | Meaning |
|---|---|
namedtuple() |
The factory function |
namedtuple, namedtuple class |
The tuple subclass returned by namedtuple() |
namedtuple instance, named tuple |
An instance of a specific namedtuple class |
You’ll find these terms used with their corresponding meaning throughout the tutorial.
Besides providing named fields, named tuples in Python offer the following features:
- Are immutable data structures
- Can have a hash value and work as dictionary keys
- Can be stored in sets when they have a hash value
- Generate a basic docstring using the type and field names
- Provide a helpful string representation that displays the tuple content in a
name=valueformat - Support indexing and slicing
- Provide additional methods and attributes, such as
._make(),_asdict(), and._fields - Are backward compatible with regular tuples
- Have similar memory usage to regular tuples
You can use namedtuple instances wherever you need a tuple-like object. They offer the added benefit of accessing values using field names and dot notation, which makes your code more readable and Pythonic.
With this brief introduction to namedtuple and its general features, you’re ready to explore how to create and use them effectively in your own code.
Creating Tuple-Like Classes With the namedtuple() Function
You use a namedtuple() to create an immutable, tuple-like sequence with named fields. A popular example that you’ll often find in resources about namedtuple is defining a class to represent a mathematical point.
Depending on the problem, you’ll probably want to use an immutable data structure to represent your points. Here’s how you can create a two-dimensional point using a regular tuple:
>>> # Create a 2D point as a regular tuple
>>> point = (2, 4)
>>> point
(2, 4)
>>> # Access coordinate x
>>> point[0]
2
>>> # Access coordinate y
>>> point[1]
4
>>> # Try to update a coordinate value
>>> point[0] = 100
Traceback (most recent call last):
...
TypeError: 'tuple' object does not support item assignment
In this example, you create an immutable, two-dimensional point using a regular tuple. This code works. You have a point with two coordinates that you can access by index. The point is immutable, so you can’t modify the coordinates. However, do you think this code is readable? Can you tell upfront what the 0 and 1 indices mean?
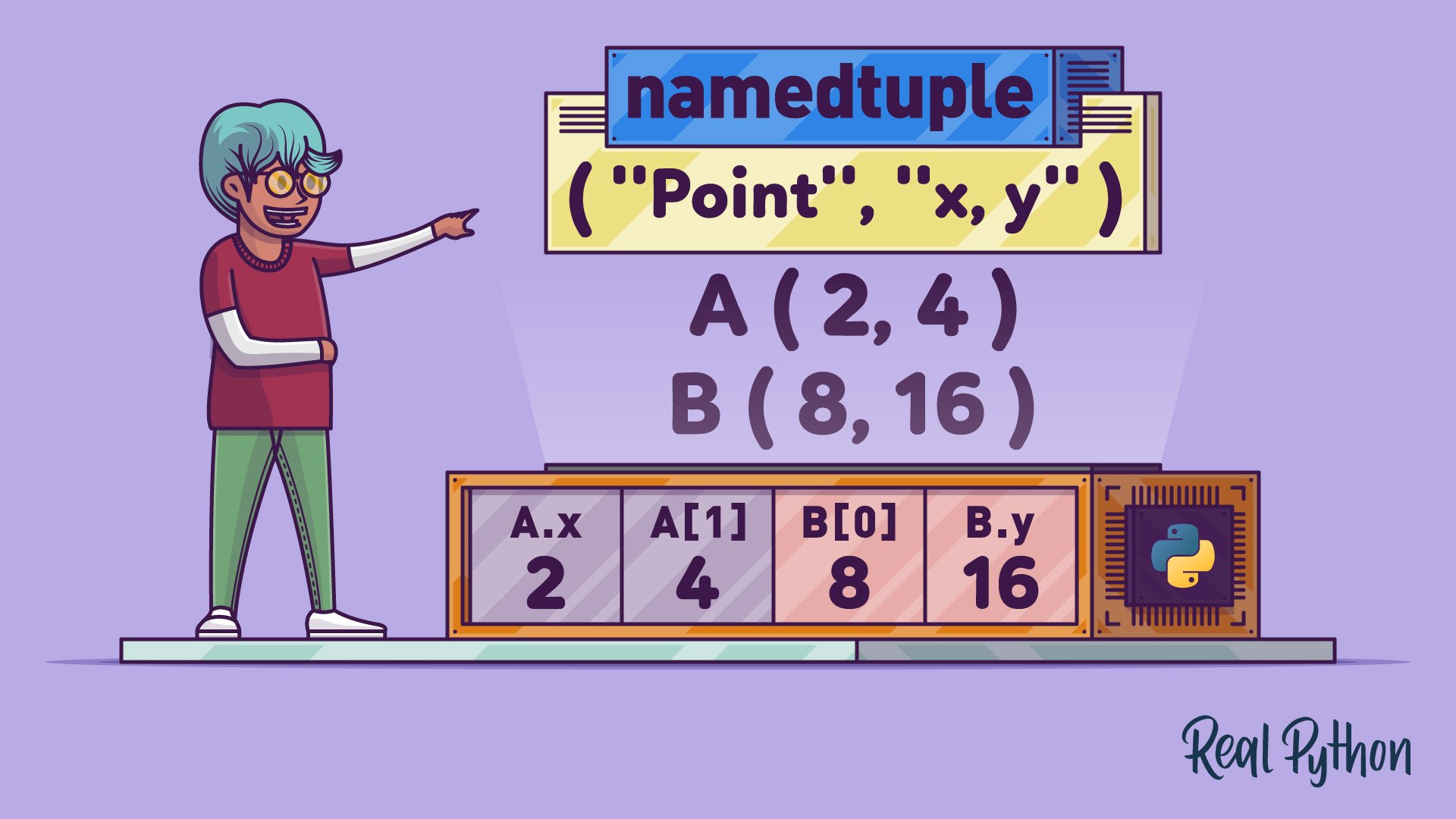
To improve clarity, you can use a namedtuple like in the following code. Note that you need to import the function from the collections module first:
>>> from collections import namedtuple
>>> # Create a namedtuple type, Point
>>> Point = namedtuple("Point", "x y")
>>> point = Point(2, 4)
>>> point
Point(x=2, y=4)
>>> # Access the coordinates by field name
>>> point.x
2
>>> point.y
4
>>> # Access the coordinates by index
>>> point[0]
2
>>> point[1]
4
>>> point.x = 100
Traceback (most recent call last):
...
AttributeError: can't set attribute
>>> issubclass(Point, tuple)
True
Now you have a Point class with two appropriately named fields, .x and .y. Your point provides a descriptive string representation by default: Point(x=2, y=4).
You can access the coordinates with dot notation and the field names, which is convenient, readable, and explicit. You can also use indices to access each coordinate’s value if you prefer.
Note: As with regular tuples, named tuples are immutable. However, the values they store don’t necessarily have to be immutable.
It’s completely valid to create a tuple or a named tuple that holds mutable values:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name children")
>>> john = Person("John Doe", ["Timmy", "Jimmy"])
>>> john
Person(name='John Doe', children=['Timmy', 'Jimmy'])
>>> id(john.children)
139695902374144
>>> john.children.append("Tina")
>>> john
Person(name='John Doe', children=['Timmy', 'Jimmy', 'Tina'])
>>> id(john.children)
139695902374144
>>> hash(john)
Traceback (most recent call last):
...
TypeError: unhashable type: 'list'
You can create named tuples that contain mutable objects. Then, you can modify the mutable objects in the underlying tuple. However, this doesn’t mean that you’re modifying the tuple itself. The tuple will continue being the same object.
Finally, tuples or named tuples with mutable values aren’t hashable, as you saw in the above example.
Finally, since namedtuple classes are subclasses of tuple, they’re immutable as well. So if you try to change the value of a coordinate, then you’ll get an AttributeError.
Supplying Required Arguments
As you learned before, namedtuple() is a factory function rather than a data structure. To create a new namedtuple class, you need to provide two positional arguments to the function:
typenameprovides the class name for thenamedtupleclass returned bynamedtuple(). You need to pass a string with a valid Python identifier to this argument.field_namesprovides the field names that you’ll use to access the values in the tuple. You can provide the field names using one of the following options:- An iterable of strings, such as
["field1", "field2", ..., "fieldN"] - A string with each field name separated by whitespace, such as
"field1 field2 ... fieldN" - A string with each field name separated by commas, such as
"field1, field2, ..., fieldN"
- An iterable of strings, such as
The typename argument is required because it defines the name of the new class being created. It’s similar to assigning a name to a class definition manually, as shown in the following comparison:
>>> from collections import namedtuple
>>> Point1 = namedtuple("Point", "x y")
>>> Point1
<class '__main__.Point'>
>>> class Point:
... def __init__(self, x, y):
... self.x = x
... self.y = y
...
>>> Point2 = Point
>>> Point2
<class '__main__.Point'>
In the first example, you call namedtuple() to dynamically create a new class with the name Point, and you then assign this class to the variable Point1. In the second example, you define a standard class, also named Point, using a class statement, and you assign the resulting class to the variable Point2.
In both cases, the variable names Point1 and Point2 act as references (or aliases) to a class named Point. However, the way the class is created—dynamically via namedtuple() or manually with a class statement—differs. The typename parameter ensures that the dynamically generated class has a meaningful and valid name.
To illustrate how to provide field_names, here are different ways to create points:
>>> # A list of strings for the field names
>>> Point = namedtuple("Point", ["x", "y"])
>>> Point
<class '__main__.Point'>
>>> Point(2, 4)
Point(x=2, y=4)
>>> # A string with comma-separated field names
>>> Point = namedtuple("Point", "x, y")
>>> Point
<class '__main__.Point'>
>>> Point(4, 8)
Point(x=4, y=8)
>>> # A generator expression for the field names
>>> Point = namedtuple("Point", (field for field in "xy"))
>>> Point
<class '__main__.Point'>
>>> Point(8, 16)
Point(x=8, y=16)
In these examples, you first create a Point using a list of field names. Then, you use a string of comma-separated field names. Finally, you use a generator expression. This last option might look like overkill in this example. However, it’s intended to illustrate the flexibility of the namedtuple() function.
Note: If you use an iterable to provide the field names, then you should use a sequence-like iterable because the order of the fields is important for producing reliable results.
Using a set, for example, would work but could produce unexpected results:
>>> Point = namedtuple("Point", {"x", "y"})
>>> Point(2, 4)
Point(y=2, x=4)
When you use an unordered iterable to provide the fields to a namedtuple, you can get unexpected results. In the example above, the coordinate names are swapped, which might not be right for your use case.
You can use any valid Python identifier for the field names, with two important exceptions:
- Names starting with an underscore (
_) - Python keywords
If you provide field names that violate either of these rules, then you’ll get a ValueError:
>>> Point = namedtuple("Point", ["x", "_y"])
Traceback (most recent call last):
...
ValueError: Field names cannot start with an underscore: '_y'
In this example, the second field name starts with an underscore, so you get a ValueError telling you that field names can’t start with that character. This behavior avoids name conflicts with the namedtuple methods and attributes, which start with a leading underscore.
Finally, you can also create instances of a named tuple using keyword arguments or a dictionary, like in the following example:
>>> Point = namedtuple("Point", "x y")
>>> Point(x=2, y=4)
Point(x=2, y=4)
>>> Point(**{"x": 4, "y": 8})
Point(x=4, y=8)
In the first example, you use keyword arguments to create a Point object. In the second example, you use a dictionary whose keys match the fields of Point. In this case, you need to perform a dictionary unpacking so that each value goes to the correct argument.
Using Optional Arguments
Besides the two required positional arguments, the namedtuple() factory function can also take the following optional keyword-only arguments:
renamedefaultsmodule
If you set rename to True, then all the invalid field names are automatically replaced with positional names, such as _0 or _1.
Say your company has an old Python database application that manages data about passengers who travel with the company:
database.py
def get_column_names(table):
if table == "passenger":
return ("id", "first_name", "last_name", "class")
raise ValueError(f"unknown table {table}")
def get_passenger_by_id(passenger_id):
if passenger_id == 1234:
return (1234, "John", "Doe", "Business")
raise ValueError(f"no record with id={passenger_id}")
This file provides two simple functions for interacting with a fictional passenger database. One function returns the column names for the passenger table, while the other fetches a hard-coded passenger record based on its ID. This code is a stub and serves purely as a demonstration, as it’s not connected to a real database or production system.
You’re asked to update the system. You realize that you can use get_column_names() to create a namedtuple class that helps you store passengers’ data.
You end up with the following code:
passenger.py
from collections import namedtuple
from database import get_column_names
Passenger = namedtuple("Passenger", get_column_names("passenger"))
However, when you run this code, you get an exception traceback like the following:
Traceback (most recent call last):
...
ValueError: Type names and field names cannot be a keyword: 'class'
This traceback tells you that the 'class' column name isn’t a valid field name for your namedtuple field. To fix this issue, you can use rename:
passenger.py
from collections import namedtuple
from database import get_column_names
Passenger = namedtuple("Passenger", get_column_names("passenger"), rename=True)
Setting rename to True causes namedtuple() to automatically replace invalid names with positional names using the format _0, _1, and so on.
Now, suppose you retrieve one row from the database and create your first Passenger instance:
>>> from passenger import Passenger
>>> from database import get_passenger_by_id
>>> Passenger(*get_passenger_by_id(1234))
Passenger(id=1234, first_name='John', last_name='Doe', _3='Business')
In this case, get_passenger_by_id() is another function available in your hypothetical application. It retrieves the data for a given passenger wrapped in a tuple. The final result is that your newly created passenger has replaced the class name with _3 because Python keywords can’t be used as field names.
The second optional argument to namedtuple() is defaults. This argument defaults to None, which means that the fields won’t have default values. You can set defaults to an iterable of values, in which case, namedtuple() assigns the values in the defaults iterable to the rightmost fields:
>>> from collections import namedtuple
>>> Developer = namedtuple(
... "Developer",
... "name level language",
... defaults=["Junior", "Python"]
... )
>>> Developer("John")
Developer(name='John', level='Junior', language='Python')
In this example, the .level and .language fields have default values, which makes them optional arguments. Since you don’t define a default value for name, you need to provide a value when you create an instance of Developer. Note that the default values are applied to the rightmost fields.
The last argument to namedtuple() is module. If you provide a valid module name to this argument, then the .__module__ attribute of the resulting namedtuple is set to that value. This attribute holds the name of the module in which a given function or callable is defined:
>>> Point = namedtuple("Point", "x y", module="custom")
>>> Point
<class 'custom.Point'>
>>> Point.__module__
'custom'
In this example, when you access .__module__ on Point, you get 'custom' as a result. This indicates that your Point class is defined in your custom module.
The motivation for adding the module argument to namedtuple() in Python 3.6 was to make it possible for named tuples to support pickling through different Python implementations.
Exploring Additional Features of namedtuple Classes
Besides the methods inherited from tuple, such as .index() and .count(), namedtuple classes also provide three additional methods: ._make(), ._asdict(), and ._replace(). They also have two attributes: ._fields and ._field_defaults.
Note how the names of these methods and attributes start with an underscore. This is to prevent name conflicts with fields. In the following sections, you’ll learn about these methods and attributes and how they work.
Creating Named Tuples From Iterables With ._make()
You can use the ._make() method to create namedtuple instances from an iterable of values:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> Person._make(["Jane", 25, 1.75])
Person(name='Jane', age=25, height=1.75)
In this example, you define the Person type using the namedtuple() factory function. Then, you call ._make() on it with a list of values corresponding to each field. Note that ._make() is a class method that works as an alternative class constructor. It returns a new namedtuple instance. Finally, ._make() expects a single iterable as an argument, such as a list in the example above.
Converting Named Tuples Into Dictionaries With ._asdict()
You can convert existing named tuples into dictionaries using ._asdict(). This method returns a new dictionary that uses the field names as keys and the stored items as values:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> jane._asdict()
{'name': 'Jane', 'age': 25, 'height': 1.75}
When you call ._asdict() on a named tuple, you get a new dict object that maps field names to their corresponding values. The order of keys in the resulting dictionary matches the order of fields in the original named tuple.
Replacing Named Tuple Fields With ._replace()
The ._replace() method takes keyword arguments of the form field_name=value and returns a new namedtuple instance with the field’s value updated to the new value:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> # After Jane's birthday
>>> jane = jane._replace(age=26)
>>> jane
Person(name='Jane', age=26, height=1.75)
In this example, you update Jane’s age after her birthday. Although the name of ._replace() might suggest that the method modifies the existing named tuple in place, that’s not what happens in practice. This is because named tuples are immutable, so ._replace() returns a new instance, which you assign to the jane variable, overwriting the original object.
Starting with Python 3.13, you can use the replace() function from the copy module to achieve similar functionality:
>>> from copy import replace
>>> replace(jane, age=27)
Person(name='Jane', age=27, height=1.75)
This new approach provides a more intuitive way to update fields in named tuples, leveraging the replace() function to create a modified copy of the original instance.
Exploring Named Tuple Attributes: ._fields and ._field_defaults
Named tuples also have two attributes: ._fields and ._field_defaults. The first one holds a tuple of strings representing the field names. The second attribute holds a dictionary that maps field names to their respective default values, if any.
In the case of ._fields, you can use it to introspect your namedtuple classes and instances. You can also create new classes from existing ones:
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> ExtendedPerson = namedtuple(
... "ExtendedPerson",
... [*Person._fields, "weight"]
... )
>>> jane = ExtendedPerson("Jane", 26, 1.75, 67)
>>> jane
ExtendedPerson(name='Jane', age=26, height=1.75, weight=67)
>>> jane.weight
67
In this example, you create a new namedtuple called ExtendedPerson by reusing the fields of Person and adding a new field called .weight. To do that, you access ._fields on Person and unpack it into a new list along with the additional field, .weight.
You can also use ._fields to iterate over the fields and values in a given namedtuple instance using the built-in zip() function as shown below:
>>> Person = namedtuple("Person", "name age height weight")
>>> jane = Person("Jane", 26, 1.75, 67)
>>> for field, value in zip(jane._fields, jane):
... print(field, "->", value)
...
name -> Jane
age -> 26
height -> 1.75
weight -> 67
In this example, zip() yields tuples of the form (field, value), which allows you to access both elements of the field-value pair in the underlying named tuple. Another way to iterate over fields and values at the same time is to use ._asdict().items(). Go ahead and give it a try!
With ._field_defaults, you can introspect namedtuple classes and instances to find out what fields provide default values.
Having default values makes the fields optional. For example, say your Person class needs an additional field to hold the country where the person lives. Now, suppose that you’re mostly working with people from Canada. In this situation, you can use "Canada" as the default value of .country:
>>> Person = namedtuple(
... "Person",
... "name age height weight country",
... defaults=["Canada"]
... )
>>> Person._field_defaults
{'country': 'Canada'}
A quick query to ._field_defaults lets you know which fields have default values. In this example, other programmers on your team can see that the Person class provides "Canada" as a handy default value for .country.
If your named tuple doesn’t have default values, then .field_defaults holds an empty dictionary:
>>> Person = namedtuple("Person", "name age height weight country")
>>> Person._field_defaults
{}
If you don’t provide a list of default values to namedtuple(), then the defaults argument is None, and the ._field_defaults holds an empty dictionary.
Writing Pythonic Code With namedtuple
Named tuples were created as a way to help you write readable, explicit, and maintainable code. They’re a tool that you can use to replace regular tuples with an equivalent and compatible data type that’s explicit and readable because of the named fields.
Using named fields and dot notation is more readable and less error-prone than using square brackets and integer indices, which provide little information about the object they reference.
In the following sections, you’ll write a few practical examples that will showcase good opportunities for using named tuples instead of regular tuples to make your code more Pythonic.
Using Field Names Instead of Indices
Say you’re creating a painting application and need to define the pen’s properties according to the user’s choice. You use a regular tuple to store the pen’s properties:
>>> pen = (2, "Solid", True)
>>> # Later in your code
>>> if pen[0] == 2 and pen[1] == "Solid" and pen[2]:
... print("Standard pen selected")
...
Standard pen selected
The first line of code defines a tuple with three values. Can you infer the meaning of each value? You can probably guess that the second value is related to the line style, but what’s the meaning of 2 and True?
To make the code clearer, you could add a nice comment to provide some context for pen, in which case you would end up with something like this:
>>> # Tuple containing: line weight, line style, and beveled edges
>>> pen = (2, "Solid", True)
By reading the comment, you understand the meaning of each value in the tuple. However, what if you or another programmer is using pen far away from this definition? They’d have to go back to the definition to check what each value means.
Here’s an alternative implementation of pen using a namedtuple:
>>> from collections import namedtuple
>>> Pen = namedtuple("Pen", "width style beveled")
>>> pen = Pen(2, "Solid", True)
>>> if pen.width == 2 and pen.style == "Solid" and pen.beveled:
... print("Standard pen selected")
...
Standard pen selected
Your code now clearly indicates that 2 represents the pen’s width, "Solid" is the line style, and so on. This new implementation represents a big difference in readability and maintainability because now you can check the fields of the pen at any place in your code without needing to come back to the definition.
Returning Multiple Values From Functions
Another situation in which you can use a named tuple is when you need to return multiple values from a function. To do this, you use the return statement followed by a series of comma-separated values, which is effectively a tuple. Again, the issue with this practice is that it might be hard to determine what each value is when you call the function.
In this situation, returning a named tuple can make your code more readable because the returned values will also provide some context for their content.
For example, Python has a built-in function called divmod() that takes two numbers as arguments and returns a tuple with the quotient and remainder resulting from the integer division of the input numbers:
>>> divmod(8, 4)
(2, 0)
To remember what each number is, you might need to read the documentation on divmod() because the numbers themselves don’t provide much context about their corresponding meaning. The function name doesn’t help much either.
Here’s a function that uses a namedtuple to clarify the meaning of each number that divmod() returns:
>>> from collections import namedtuple
>>> def custom_divmod(a, b):
... DivMod = namedtuple("DivMod", "quotient remainder")
... return DivMod(*divmod(a, b))
...
>>> custom_divmod(8, 4)
DivMod(quotient=2, remainder=0)
In this example, you add context to each returned value, allowing any programmer reading your code to immediately grasp what each number means.
Reducing the Number of Arguments in Functions
Having a small number of arguments in your function is a best programming practice. This makes your function’s signature concise and optimizes your testing process because of the reduced number of arguments and possible combinations between them. If you have a function with many arguments, you can group some of them using named tuples.
Say that you’re coding an application to manage your clients’ information. The application uses a database to store client data. To process this data and update the database, you’ve created several functions. One of your functions is create_client(), which looks something like the following:
def create_client(db, name, plan):
db.add_client(name)
db.complete_client_profile(name, plan)
This function takes three arguments. The first argument, db, represents the database you’re working with. The other two arguments are related to specific clients. Here, you have an opportunity to reduce the number of arguments using a named tuple to group the client-related ones:
from collections import namedtuple
Client = namedtuple("Client", "name plan")
client = Client("John Doe", "Premium")
def create_client(db, client):
db.add_client(client.name)
db.complete_client_profile(
client.name,
client.plan
)
Now, create_client() takes only two arguments: db and client. Inside the function, you use convenient and descriptive field names to provide the arguments to db.add_client() and db.complete_client_profile(). Your create_user() function is now more focused on the client.
Reading Tabular Data From Files and Databases
A great use case for named tuples is to use them to store database records. You can define namedtuple classes using the column names as field names and pull the data from the rows in the database into named tuples. You can also do something similar with CSV files.
For example, say you have a CSV file with data about your company’s employees and want to read that data into a suitable data structure for further processing. Your CSV file looks like this:
employees.csv
name,job,email
"Linda","Technical Lead","linda@example.com"
"Joe","Senior Web Developer","joe@example.com"
"Lara","Project Manager","lara@example.com"
"David","Data Analyst","david@example.com"
"Jane","Senior Python Developer","jane@example.com"
You’re considering using Python’s csv module and its DictReader to process the file, but you have an additional requirement. You need to store the data in an immutable and lightweight data structure, and DictReader returns dictionaries, which consume considerable memory and are mutable.
In this situation, a namedtuple is a good choice:
>>> import csv
>>> from collections import namedtuple
>>> with open("employees.csv", mode="r", encoding="utf-8") as csv_file:
... reader = csv.reader(csv_file)
... Employee = namedtuple("Employee", next(reader), rename=True)
... for row in reader:
... employee = Employee(*row)
... print(employee)
...
Employee(name='Linda', job='Technical Lead', email='linda@example.com')
Employee(name='Joe', job='Senior Web Developer', email='joe@example.com')
Employee(name='Lara', job='Project Manager', email='lara@example.com')
Employee(name='David', job='Data Analyst', email='david@example.com')
Employee(name='Jane', job='Senior Python Developer', email='jane@example.com')
In this example, you first open the employees.csv file using a with statement. Then, you call csv.reader() to get an iterator over the lines in the CSV file. With namedtuple(), you create a new Employee class. The call to the built-in next() function retrieves the first row of data from reader, which contains the CSV file’s header.
These CSV header provides the field names for your namedtuple. You also set rename to True to prevent issues with invalid field names, which can be common when you’re working with database tables and queries, CSV files, or any other type of tabular data.
Finally, the for loop creates an Employee instance from each row in the CSV file and prints the list of employees to the screen.
Comparing namedtuple With Other Data Structures
So far, you’ve learned how to use named tuples to make your code more readable, explicit, and Pythonic. You’ve also explored some examples that help you spot opportunities for using named tuples in your code.
In this section, you’ll take a quick look at the similarities and differences between namedtuple classes and other Python data structures, such as dictionaries, data classes, and typed named tuples. You’ll compare named tuples with other data structures regarding the following aspects:
- Readability
- Mutability
- Memory usage
- Performance
By the end of the following sections, you’ll be better prepared to choose the right data structure for your specific use case.
namedtuple vs Dictionaries
The dict data type is a fundamental data structure in Python. The language itself is built around dictionaries, so they’re everywhere. Since they’re so common and useful, you’ve probably used them a lot in your code. But how different are named tuples and dictionaries?
In terms of readability, you could say that dictionaries are as readable as named tuples. Even though they don’t provide a way to access attributes using dot notation, the dictionary-style key lookup is quite readable and straightforward:
>>> jane = {"name": "Jane", "age": 25, "height": 1.75}
>>> jane["age"]
25
>>> # Equivalent named tuple
>>> from collections import namedtuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> jane.age
25
In both examples, you can quickly grasp the code’s intention. The named tuple definition requires a couple of additional lines of code, though: one line to import the namedtuple() factory function and another to define your namedtuple class, Person. However, the syntax for accessing the values is pretty straightforward in both cases.
A big difference between both data structures is that dictionaries are mutable and named tuples are immutable. This means that you can modify dictionaries in place, but you can’t modify named tuples:
>>> jane = {"name": "Jane", "age": 25, "height": 1.75}
>>> jane["age"] = 26
>>> jane["age"]
26
>>> jane["weight"] = 67
>>> jane
{'name': 'Jane', 'age': 26, 'height': 1.75, 'weight': 67}
>>> # Equivalent named tuple
>>> Person = namedtuple("Person", "name age height")
>>> jane = Person("Jane", 25, 1.75)
>>> jane.age = 26
Traceback (most recent call last):
...
AttributeError: can't set attribute
>>> jane.weight = 67
Traceback (most recent call last):
...
AttributeError: 'Person' object has no attribute 'weight'
You can update the value of an existing key in a dictionary, but you can’t do something similar in a named tuple. You can add new key-value pairs to existing dictionaries, but you can’t add field-value pairs to existing named tuples.
Note: In named tuples, you can use ._replace() to update the value of a given field, but that method creates and returns a new named tuple instance instead of updating the underlying instance in place.
In general, if you need an immutable data structure to properly solve a given problem, then consider using a named tuple instead of a dictionary so you can meet your requirements.
Regarding memory usage, named tuples are quite a lightweight data structure. Fire up your code editor or IDE and create the following script:
namedtuple_dict_memory.py
from collections import namedtuple
from pympler import asizeof
Point = namedtuple("Point", "x y z")
point = Point(1, 2, 3)
namedtuple_size = asizeof.asizeof(point)
dict_size = asizeof.asizeof(point._asdict())
gain = 100 - namedtuple_size / dict_size * 100
print(f"namedtuple: {namedtuple_size} bytes ({gain:.2f}% smaller)")
print(f"dict: {dict_size} bytes")
This small script uses asizeof.asizeof() from Pympler to get the memory footprint of a named tuple and its equivalent dictionary.
Note: Pympler is a tool to monitor and analyze the memory behavior of Python objects. You can install it from PyPI using pip as shown below:
$ python -m pip install pympler
After you run this command, Pympler will be available in your current Python environment, and you’ll be able to run the above script.
If you run the script from your command line, then you’ll get an output like the following:
$ python namedtuple_dict_memory.py
namedtuple: 160 bytes (62.26% smaller)
dict: 424 bytes
This output confirms that named tuples consume less memory than equivalent dictionaries. If memory consumption is a restriction for you, then you should consider using a named tuple instead of a dictionary.
Note: When you compare named tuples and dictionaries, the final memory consumption difference will depend on the number of values and their types. With different values, you’ll get different results.
Finally, you need to have an idea of how different named tuples and dictionaries are in terms of performance. To do that, you’ll test membership and attribute access operations. Get back to your code editor and create the following script:
namedtuple_dict_time.py
from collections import namedtuple
from time import perf_counter
def average_time(structure, test_func):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
test_func(structure)
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_dict(dictionary):
"x" in dictionary
"missing_key" in dictionary
2 in dictionary.values()
"missing_value" in dictionary.values()
dictionary["y"]
def time_namedtuple(named_tuple):
"x" in named_tuple._fields
"missing_field" in named_tuple._fields
2 in named_tuple
"missing_value" in named_tuple
named_tuple.y
Point = namedtuple("Point", "x y z")
point = Point(x=1, y=2, z=3)
namedtuple_time = average_time(point, time_namedtuple)
dict_time = average_time(point._asdict(), time_dict)
gain = dict_time / namedtuple_time
print(f"namedtuple: {namedtuple_time:.2f} ns ({gain:.2f}x faster)")
print(f"dict: {dict_time:.2f} ns")
This script times operations common to both dictionaries and named tuples. These operations include membership tests and attribute access. Running the script on your system will display an output similar to the following:
$ namedtuple_dict_time.py
namedtuple: 145.00 ns (1.49x faster)
dict: 216.26 ns
This output shows that operations on named tuples are slightly faster than similar operations on dictionaries.
namedtuple vs Data Classes
Python comes with data classes, which—according to PEP 557—are similar to named tuples but are mutable:
Data Classes can be thought of as “mutable namedtuples with defaults.” (Source)
However, it’d be more accurate to say that data classes are like mutable named tuples with type hints. The defaults part isn’t a real difference because named tuples can also have default values for their fields. So, at first glance, the main differences are mutability and type hints.
To create a data class, you need to import the @dataclass decorator from the dataclasses module. Then, you can define your data classes using the regular class definition syntax:
>>> from dataclasses import dataclass
>>> @dataclass
... class Person:
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
...
>>> jane = Person("Jane", 25, 1.75, 67)
>>> jane
Person(name='Jane', age=25, height=1.75, weight=67, country='Canada')
>>> jane.name
'Jane'
>>> jane.name = "Jane Doe"
>>> jane.name
'Jane Doe'
In terms of readability, there are no significant differences between data classes and named tuples. Both provide similar string representations and allow attribute access using dot notation.
When it comes to mutability, data classes are mutable by definition, so you can change the value of their attributes when needed. However, they have an ace up their sleeve. You can set the @dataclass decorator’s frozen argument to True to make them immutable:
>>> from dataclasses import dataclass
>>> @dataclass(frozen=True)
... class Person:
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
...
>>> jane = Person("Jane", 25, 1.75, 67)
>>> jane.name = "Jane Doe"
Traceback (most recent call last):
...
dataclasses.FrozenInstanceError: cannot assign to field 'name'
If you set frozen to True in the call to @dataclass, then you make the data class immutable. In this case, when you try to update Jane’s name, you get a FrozenInstanceError.
Another subtle difference between named tuples and data classes is that the latter aren’t iterable by default. Stick with the Jane example and try to iterate over her data:
>>> for field in jane:
... print(field)
...
Traceback (most recent call last):
...
TypeError: 'Person' object is not iterable
If you try to iterate over a bare-bones data class, then you get a TypeError exception. This is consistent with the behavior of regular Python classes. Fortunately, there are ways to work around this behavior.
For example, you can make a data class iterable by providing the .__iter__() special method. Here’s how to do this in your Person class:
>>> from dataclasses import astuple, dataclass
>>> @dataclass
... class Person:
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
...
... def __iter__(self):
... return iter(astuple(self))
...
>>> jane = Person("Jane", 25, 1.75, 67)
>>> for field in jane:
... print(field)
...
Jane
25
1.75
67
Canada
In this example, you implement the .__iter__() method to make the data class iterable. The astuple() function converts the data class into a tuple, which you pass to the built-in iter() function to build an iterator. With this addition, you can start iterating over Jane’s data.
Regarding memory consumption, named tuples are more lightweight than data classes. You can confirm this by creating and running a small script similar to the one you saw in the above section. To view the complete script, expand the box below.
Here’s a script that compares memory usage between a namedtuple and its equivalent data class:
namedtuple_dataclass_memory.py
from collections import namedtuple
from dataclasses import dataclass
from pympler import asizeof
PointNamedTuple = namedtuple("PointNamedTuple", "x y z")
@dataclass
class PointDataClass:
x: int
y: int
z: int
namedtuple_memory = asizeof.asizeof(PointNamedTuple(x=1, y=2, z=3))
dataclass_memory = asizeof.asizeof(PointDataClass(x=1, y=2, z=3))
gain = 100 - namedtuple_memory / dataclass_memory * 100
print(f"namedtuple: {namedtuple_memory} bytes ({gain:.2f}% smaller)")
print(f"data class: {dataclass_memory} bytes")
In this script, you create a named tuple and a data class containing similar data and compare their memory footprints.
Here are the results of running the script above:
$ python namedtuple_dataclass_memory.py
namedtuple: 160 bytes (72.60% smaller)
data class: 584 bytes
Unlike namedtuple classes, data classes keep a per-instance .__dict__ to store writable instance attributes. This contributes to a bigger memory footprint.
Next, you can expand the section below to get a script that compares namedtuple classes and data classes in terms of their performance on attribute access.
The following script compares the performance of attribute access on a named tuple and its equivalent data class:
namedtuple_dataclass_time.py
from collections import namedtuple
from dataclasses import dataclass
from time import perf_counter
def average_time(structure, test_func):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
test_func(structure)
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_structure(structure):
structure.x
structure.y
structure.z
PointNamedTuple = namedtuple("PointNamedTuple", "x y z", defaults=[3])
@dataclass
class PointDataClass:
x: int
y: int
z: int
namedtuple_time = average_time(PointNamedTuple(x=1, y=2, z=3), time_structure)
dataclass_time = average_time(PointDataClass(x=1, y=2, z=3), time_structure)
print(f"namedtuple: {namedtuple_time:.2f} ns")
print(f"data class: {dataclass_time:.2f} ns")
In this script, you time the attribute access operation because that’s almost the only common operation between a named tuple and a data class. You can also time membership operations, but you’d have to access the data class’s .__dict__ attribute to do that.
In terms of performance, here are the results:
$ python namedtuple_dataclass_time.py
namedtuple: 83.24 ns
data class: 61.15 ns
The performance difference is minimal, so both data structures perform equivalently in attribute access operations.
namedtuple vs typing.NamedTuple
Python ships with a module called typing to support type hints. This module provides NamedTuple, which is a typed version of namedtuple. With NamedTuple, you can create namedtuple classes with type hints.
To continue with the Person example, you can create an equivalent typed named tuple as shown in the code below:
>>> from typing import NamedTuple
>>> class Person(NamedTuple):
... name: str
... age: int
... height: float
... weight: float
... country: str = "Canada"
...
>>> issubclass(Person, tuple)
True
>>> jane = Person("Jane", 25, 1.75, 67)
>>> jane.name
'Jane'
>>> jane.name = "Jane Doe"
Traceback (most recent call last):
...
AttributeError: can't set attribute
With NamedTuple, you can create tuple subclasses that support type hints and attribute access through dot notation. Since the resulting class is a tuple subclass, it’s also immutable.
A subtle detail in the example above is that NamedTuple subclasses look even more similar to data classes than named tuples.
When it comes to memory consumption, both namedtuple and NamedTuple instances use the same amount of memory. You can expand the box below to view a script that compares their memory usage.
Here’s a script that compares the memory usage of a namedtuple and its equivalent typing.NamedTuple:
typed_namedtuple_memory.py
from collections import namedtuple
from typing import NamedTuple
from pympler import asizeof
PointNamedTuple = namedtuple("PointNamedTuple", "x y z")
class PointTypedNamedTuple(NamedTuple):
x: int
y: int
z: int
namedtuple_memory = asizeof.asizeof(PointNamedTuple(x=1, y=2, z=3))
typed_namedtuple_memory = asizeof.asizeof(PointTypedNamedTuple(x=1, y=2, z=3))
print(f"namedtuple: {namedtuple_memory} bytes")
print(f"typing.NamedTuple: {typed_namedtuple_memory} bytes")
In this script, you create a named tuple and an equivalent typed NamedTuple instance. Then, you compare the memory usage of both instances.
This time, the script that compares memory usage produces the following output:
$ python typed_namedtuple_memory.py
namedtuple: 160 bytes
typing.NamedTuple: 160 bytes
In this case, both instances consume the same amount of memory, so there’s no winner this time.
Because namedtuple classes and NamedTuple subclasses are both subclasses of tuple, they have a lot in common. In this case, you can compare the performance of membership tests for fields and values, as well as attribute access using dot notation. Expand the box below to view a script that compares namedtuple and NamedTuple.
The following script compares namedtuple and typing.NamedTuple performance-wise:
typed_namedtuple_time.py
from collections import namedtuple
from time import perf_counter
from typing import NamedTuple
def average_time(structure, test_func):
time_measurements = []
for _ in range(1_000_000):
start = perf_counter()
test_func(structure)
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_structure(structure):
"x" in structure._fields
"missing_field" in structure._fields
2 in structure
"missing_value" in structure
structure.y
PointNamedTuple = namedtuple("PointNamedTuple", "x y z")
class PointTypedNamedTuple(NamedTuple):
x: int
y: int
z: int
namedtuple_time = average_time(PointNamedTuple(x=1, y=2, z=3), time_structure)
typed_namedtuple_time = average_time(
PointTypedNamedTuple(x=1, y=2, z=3), time_structure
)
print(f"namedtuple: {namedtuple_time:.2f} ns")
print(f"typing.NamedTuple: {typed_namedtuple_time:.2f} ns")
In this script, you first create a named tuple and then a typed named tuple with similar content. Then, you compare the performance of common operations over both data structures.
Here are the results:
$ python typed_namedtuple_time.py
namedtuple: 144.90 ns
typing.NamedTuple: 145.67 ns
In this case, you can say that both data structures behave almost the same in terms of performance. Other than that, using NamedTuple to create your named tuples can make your code even more explicit because you can add type information to the fields. You can also provide default values, add new functionality, and write docstrings for your typed named tuples.
namedtuple vs tuple
So far, you’ve compared namedtuple classes with other data structures according to several features. In this section, you’ll take a general look at how regular tuples and named tuples compare in terms of the time it takes to create an instance of each class.
Say you have an application that creates a ton of tuples dynamically. You decide to make your code more Pythonic and maintainable using named tuples. Once you’ve updated your codebase to use named tuples, you run the application and notice some performance issues. After some tests, you conclude that the issues could be related to creating named tuples dynamically.
Here’s a script that measures the average time required to create several tuples and named tuples dynamically:
tuple_namedtuple_time.py
from collections import namedtuple
from time import perf_counter
def average_time(test_func):
time_measurements = []
for _ in range(1_000):
start = perf_counter()
test_func()
end = perf_counter()
time_measurements.append(end - start)
return sum(time_measurements) / len(time_measurements) * int(1e9)
def time_tuple():
tuple([1] * 1000)
fields = [f"a{n}" for n in range(1000)]
TestNamedTuple = namedtuple("TestNamedTuple", fields)
def time_namedtuple():
TestNamedTuple(*([1] * 1000))
namedtuple_time = average_time(time_namedtuple)
tuple_time = average_time(time_tuple)
gain = namedtuple_time / tuple_time
print(f"tuple: {tuple_time:.2f} ns ({gain:.2f}x faster)")
print(f"namedtuple: {namedtuple_time:.2f} ns")
In this script, you calculate the average time it takes to create several tuples and their equivalent named tuples. If you run the script from your command line, then you’ll get an output similar to the following:
$ python tuple_namedtuple_time.py
tuple: 1707.38 ns (5.07x faster)
namedtuple: 8662.46 ns
Looking at this output, you can conclude that creating tuple objects dynamically is a lot faster than creating equivalent named tuples.
In some situations, such as working with large databases, the additional time required to create a named tuple can seriously affect your application’s performance.
You’ve learned a lot about namedtuple and other similar data structures and classes. Here’s a table that summarizes how the data structures covered in the previous sections compare to namedtuple:
dict |
@dataclass |
NamedTuple |
|
|---|---|---|---|
| Readability | Similar | Equal | Equal |
| Immutability | No | No by default, yes if you set @dataclass(frozen=True) |
Yes |
| Memory Usage | Higher | Higher | Equal |
| Performance | Slower | Similar | Similar |
| Iterability | Yes | No by default, yes if you provide an .__iter__() method |
Yes |
With this summary, you’ll be better prepared to choose the data structure that best fits your needs. Additionally, you should consider that data classes and NamedTuple allow you to add type hints, which can improve the type safety of your code.
Subclassing namedtuple Classes
Since namedtuple classes are regular Python classes, you can subclass them if you need to provide additional functionality, a docstring, a user-friendly string representation, or other additional methods.
For example, it’s generally not best practice to store a person’s age directly in an object. Instead, it’s better to store their birth date and compute the age dynamically when needed:
>>> from collections import namedtuple
>>> from datetime import date
>>> BasePerson = namedtuple(
... "BasePerson",
... "name birthdate country",
... defaults=["Canada"]
... )
>>> class Person(BasePerson):
... """A namedtuple subclass to hold a person's data."""
... __slots__ = ()
...
... def __str__(self):
... return f"Name: {self.name}, age: {self.age} years old."
...
... @property
... def age(self):
... return (date.today() - self.birthdate).days // 365
...
>>> Person.__doc__
"A namedtuple subclass to hold a person's data."
>>> jane = Person("Jane", date(1996, 3, 5))
>>> jane.age
25
>>> jane
Person(name='Jane', birthdate=datetime.date(1996, 3, 5), country='Canada')
>>> print(jane)
Name: Jane, age: 29 years old.
Person inherits from BasePerson, which is a namedtuple class. In the subclass definition, you add a docstring to describe what the class does. Then, you set the .__slots__ class attribute to an empty tuple. This prevents the automatic creation of a per-instance .__dict__ and keeps your BasePerson subclass memory-efficient.
You also add a custom .__str__() to provide a nice string representation for the class. Finally, you add an .age property to compute the person’s age using the datetime module and some of its functionality.
Conclusion
You’ve gained a comprehensive understanding of Python’s namedtuple, a tool in the collections module that creates tuple subclasses with named fields. You’ve seen how it can improve code readability and maintainability by allowing access to tuple items using descriptive field names instead of numeric indices.
You also explored additional features of namedtuple classes including immutability, memory efficiency, and compatibility with dictionaries and other data structures.
Knowing how to use namedtuple is a valuable skill because it allows you to write more Pythonic code that’s clean, explicit, and maintainable.
In this tutorial, you’ve learned how to:
- Create and use
namedtupleclasses and instances - Take advantage of some cool features of
namedtuple - Identify opportunities to write more Pythonic code with
namedtuple - Choose
namedtupleover other data structures when appropriate - Subclass a
namedtupleto add new functionalities
With this knowledge, you can deeply improve the quality of your existing and future code. If you frequently use tuples, then consider turning them into named tuples whenever it makes sense. Doing so will make your code much more readable and Pythonic.
Get Your Code: Click here to download the free sample code that shows you how to use namedtuple to write Pythonic and clean code.
Frequently Asked Questions
Now that you have some experience with the namedtuple collection in Python, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
A namedtuple is a factory function in the collections module. It creates a tuple subclass with named fields that allow you to access tuple items using field names instead of integer indices.
The primary difference is that namedtuple lets you access elements using named fields and dot notation, which improves readability, while a regular tuple requires you to access elements by index.
You use namedtuple to improve code clarity and maintainability by accessing elements through descriptive names instead of relying on indices that don’t reveal much about the tuple’s content.
Alternatives to namedtuple in Python include dictionaries, data classes, and typing.NamedTuple, each offering different features and trade-offs.
Take the Quiz: Test your knowledge with our interactive “Write Pythonic and Clean Code With namedtuple” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Write Pythonic and Clean Code With namedtupleIn this quiz, you'll test your understanding of Python's namedtuple() factory function from the collections module.







