The MarkItDown library lets you quickly turn PDFs, Office files, images, HTML, audio, and URLs into LLM-ready Markdown. In this tutorial, you’ll compare MarkItDown with Pandoc, run it from the command line, use it in Python code, and integrate conversions into AI-powered workflows.
By the end of this tutorial, you’ll understand that:
- You can install MarkItDown with
pipusing the[all]specifier to pull in optional dependencies. - The CLI’s results can be saved to a file using the
-oor--outputcommand-line option followed by a target path. - The
.convert()method reads the input document and converts it to Markdown text. - You can connect MarkItDown’s MCP server to clients like Claude Desktop to expose on-demand conversions to chats.
- MarkItDown can integrate with LLMs to generate image descriptions and extract text from images with OCR and custom prompts.
To decide whether to use MarkItDown or another library—such as Pandoc—for your Markdown conversion tasks, consider these factors:
| Use Case | Choose MarkItDown | Choose Pandoc |
|---|---|---|
| You want fast Markdown conversion for documentation, blogs, or LLM input. | ✅ | — |
| You need high visual fidelity, fine-grained layout control, or broader input/output format support. | — | ✅ |
Your choice depends on whether you value speed, structure, and AI-pipeline integration over full formatting fidelity or wide-format support. MarkItDown isn’t intended for perfect, high-fidelity conversions for human consumption. This is especially true for complex document layouts or richly formatted content, in which case you should use Pandoc.
Get Your Code: Click here to download the free sample code that shows you how to use Python MarkItDown to convert documents into LLM-ready Markdown.
Take the Quiz: Test your knowledge with our interactive “Python MarkItDown: Convert Documents Into LLM-Ready Markdown” quiz. You’ll receive a score upon completion to help you track your learning progress:

Interactive Quiz
Python MarkItDown: Convert Documents Into LLM-Ready MarkdownPractice MarkItDown basics. Convert PDFs, Word documents, Excel documents, and HTML documents to Markdown. Try the quiz.
Start Using MarkItDown
MarkItDown is a lightweight Python utility for converting various file formats into Markdown content. This tool is useful when you need to feed large language models (LLMs) and AI-powered text analysis pipelines with specific content that’s stored in other file formats. This lets you take advantage of Markdown’s high token efficiency.
The library supports a wide list of input formats, including the following:
The relevance of MarkItDown lies in its minimal setup and its ability to handle multiple input file formats. In the following sections, you’ll learn how to install and set up MarkItDown in your Python environment and explore its command-line interface (CLI) and main features.
Installation
To get started with MarkItDown, you need to install the library from the Python Package Index (PyPI) using pip. Before running the command below, make sure you create and activate a Python virtual environment to avoid cluttering your system Python installation:
(venv) $ python -m pip install 'markitdown[all]'
This command installs MarkItDown and all its optional dependencies in your current Python environment. After the installation finishes, you can verify that the package is working correctly:
(venv) $ markitdown --version
markitdown 0.1.3
This command should display the installed version of MarkItDown, confirming a successful installation. That should be it! You’re all set up to start using the library.
Note: If you’re running the latest Python 3.14 release, pip might install an outdated version of MarkItDown instead of the current stable one. This happens because the library’s own dependencies haven’t been built for Python 3.14 yet, so pip falls back to the earliest compatible version it finds.
To fix this, you can install MarkItDown in a Python 3.13 or earlier environment. Check out pyenv to manage multiple versions of Python.
Alternatively, MarkItDown also supports several optional dependencies that enhance its capabilities. You can install them selectively according to your needs. Below is a list of some available optional dependencies:
pptxfor PowerPoint filesdocxfor Word documentsxlsxandxlsfor modern and older Excel workbookspdffor PDF filesoutlookfor Outlook messagesaz-doc-intelfor Azure Document Intelligenceaudio-transcriptionfor audio transcription of WAV and MP3 filesyoutube-transcriptionfor fetching YouTube video transcripts
If you only need a subset of dependencies, then you can install them with a command like the following:
(venv) $ python -m pip install 'markitdown[pdf,pptx,docx]'
This command installs only the dependencies needed for processing PDF, PPTX, and DOCX files. This way, you avoid cluttering your environment with artifacts that you won’t use or need in your code.
Command-Line Interface
Once you have MarkItDown installed, you can start using its CLI. You’ll have multiple ways to convert documents to Markdown from your command line. To try it out, say that you have the following CSV file with data about your company’s employees:
employees.csv
First Name,Last Name,Department,Position,Start Date
Alice,Johnson,Marketing,Marketing Coordinator,1/15/2022
Bob,Williams,Human Resources,HR Generalist,6/1/2021
Carol,Davis,Engineering,Software Engineer,3/20/2023
David,Brown,Sales,Sales Representative,9/10/2022
Eve,Miller,Finance,Financial Analyst,11/5/2021
Frank,Garcia,Customer Service,Customer Support Specialist,7/1/2023
Grace,Rodriguez,Research & Development,Research Scientist,4/25/2022
Henry,Martinez,Operations,Operations Manager,2/14/2021
Click the link below to download a folder containing this CSV file and other sample documents you’ll use throughout this tutorial. You’ll find the code examples in the root of the download folder and the sample files in the data/ subdirectory.
Get Your Code: Click here to download the free sample code that shows you how to use Python MarkItDown to convert documents into LLM-ready Markdown.
Once you’ve downloaded the sample files, make sure you’re in the data/ subdirectory before running the commands below. You can use one of the following commands to convert the CSV file’s content into a Markdown-formatted table and display the result in your terminal window:
$ cat employees.csv | markitdown # Pipe the file's content
| First Name | Last Name | Department | Position | Start Date |
| --- | --- | --- | --- | --- |
| Alice | Johnson | Marketing | Marketing Coordinator | 1/15/2022 |
| Bob | Williams | Human Resources | HR Generalist | 6/1/2021 |
| Carol | Davis | Engineering | Software Engineer | 3/20/2023 |
| David | Brown | Sales | Sales Representative | 9/10/2022 |
| Eve | Miller | Finance | Financial Analyst | 11/5/2021 |
| Frank | Garcia | Customer Service | Customer Support Specialist | 7/1/2023 |
| Grace | Rodriguez | Research & Development | Research Scientist | 4/25/2022 |
| Henry | Martinez | Operations | Operations Manager | 2/14/2021 |
$ markitdown < employees.csv # Use input redirection from a file
# Same output as above...
You’ll typically pass the output of either commands to another program, an LLM, or a file. However, if you want a more fancy table preview right in your terminal, then consider using the Rich library:
$ cat employees.csv | markitdown | python -m rich.markdown -
First Name Last Name Department Position Start Date
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
Alice Johnson Marketing Marketing Coordinator 1/15/2022
Bob Williams Human Resources HR Generalist 6/1/2021
Carol Davis Engineering Software Engineer 3/20/2023
David Brown Sales Sales Representative 9/10/2022
Eve Miller Finance Financial Analyst 11/5/2021
Frank Garcia Customer Service Customer Support Specialist 7/1/2023
Grace Rodriguez Research & Development Research Scientist 4/25/2022
Henry Martinez Operations Operations Manager 2/14/2021
To save the resulting content into a Markdown file, you can use the -o command-line option:
$ markitdown employees.csv -o employees.md
The -o or --output command-line option allows you to specify a file path to save the result. Once you’ve run one of these commands, you’ll have an employees.md file with the following content:
employees.md
| First Name | Last Name | Department | Position | Start Date |
| --- | --- | --- | --- | --- |
| Alice | Johnson | Marketing | Marketing Coordinator | 1/15/2022 |
| Bob | Williams | Human Resources | HR Generalist | 6/1/2021 |
| Carol | Davis | Engineering | Software Engineer | 3/20/2023 |
| David | Brown | Sales | Sales Representative | 9/10/2022 |
| Eve | Miller | Finance | Financial Analyst | 11/5/2021 |
| Frank | Garcia | Customer Service | Customer Support Specialist | 7/1/2023 |
| Grace | Rodriguez | Research & Development | Research Scientist | 4/25/2022 |
| Henry | Martinez | Operations | Operations Manager | 2/14/2021 |
This table looks good, doesn’t it? It has proper Markdown formatting, which is great for keeping the information organized. You can use the MarkItDown CLI to convert any of the supported input formats.
MarkItDown considers the input file extension when converting the content into Markdown. If you have a file with no extension or are reading the content from standard input, then you can use the --extension or -x command-line option to provide a hint about the file extension. This will improve the conversion results.
For example, say that you have a zen-of-python.txt file with the following HTML content:
zen-of-python.txt
<h2>The Zen of Python, by Tim Peters</h2>
<ul>
<li>Beautiful is better than ugly.</li>
<li>Explicit is better than implicit.</li>
<li>Simple is better than complex.</li>
<li>Complex is better than complicated.</li>
<li>Flat is better than nested.</li>
<li>Sparse is better than dense.</li>
<li>Readability counts.</li>
<li>Special cases aren't special enough to break the rules.</li>
<li>Although practicality beats purity.</li>
<li>Errors should never pass silently.</li>
<li>Unless explicitly silenced.</li>
<li>In the face of ambiguity, refuse the temptation to guess.</li>
<li>There should be one-- and preferably only one --obvious way to do it.</li>
<li>Although that way may not be obvious at first unless you're Dutch.</li>
<li>Now is better than never.</li>
<li>Although never is often better than <em>right</em> now.</li>
<li>If the implementation is hard to explain, it's a bad idea.</li>
<li>If the implementation is easy to explain, it may be a good idea.</li>
<li>Namespaces are one honking great idea -- let's do more of those!</li>
</ul>
Then, you run the command below and expect to get an H2 heading and an unordered list of principles. However, the result is HTML again:
$ markitdown zen-of-python.txt
<h2>The Zen of Python, by Tim Peters</h2>
<ul>
<li>Beautiful is better than ugly.</li>
<li>Explicit is better than implicit.</li>
<li>Simple is better than complex.</li>
...
As you can see, MarkItDown doesn’t perform any conversion in this example because the input file extension is .txt, and plain text is already valid Markdown. Here’s what happens when you use the -x option:
$ markitdown zen-of-python.txt -x html
## The Zen of Python, by Tim Peters
* Beautiful is better than ugly.
* Explicit is better than implicit.
* Simple is better than complex.
...
Even though the file extension isn’t .html, the library performs the conversion correctly due to the provided extension hint.
Key Features
MarkItDown offers a nice set of features designed to help you quickly convert your documents and files into Markdown content and integrate with LLMs and AI-powered workflows:
- Multi-format conversion: Supports converting PDF, Word (DOCX), PowerPoint (PPTX), Excel (XLSX and XLS), images (JPG and PNG), audio (WAV and MP3), HTML, and ZIP archives.
- Structure preservation: Preserves document structure as much as possible, including headings, lists, tables, and links. This is especially true for Microsoft Office files, including Word documents, Excel workbooks, and PowerPoint presentations.
- In-memory processing: Processes files in memory without creating temporary files, enhancing performance and security.
- Plugin support: Supports third-party plugins and extensions.
- LLM integration: Integrates with LLMs to create image captions and descriptions.
You’ve already learned that MarkItDown is accessible through a CLI. It also provides a Python API, giving you the chance to process your files from Python code. You’ll learn about this API in the following section.
Convert Documents With MarkItDown and Python
You can use MarkItDown from Python with a concise and straightforward API. To get started, you only need to import the MarkItDown class from markitdown, instantiate it, and pass a document path to its .convert() method.
If you’ve downloaded the sample documents for this tutorial, then you can start a Python REPL in the downloaded directory and run the following:
>>> from markitdown import MarkItDown
>>> md = MarkItDown()
>>> result = md.convert("./data/markdown_syntax.docx")
>>> print(result.markdown)
# Markdown Syntax Demo
This is a **bold** text, and this is *italic* text.
You can also combine them: ***bold + italic*** or ~~strikethrough~~.
## Headings
# Heading 1
## Heading 2
### Heading 3
...
In this example, you call the .convert() method with a sample DOCX file. The method returns a DocumentConverterResult instance whose most relevant attribute is .markdown. As its name suggests, this attribute contains the Markdown that results from converting the input document.
Note: In MarkItDown’s documentation, you’ll find examples that use .text_content instead of .markdown. The .text_content attribute is being deprecated in favor of the more intuitive .markdown attribute. New code should migrate to using .markdown or .__str__().
If you compare the original content of markdown_syntax.docx with the output, then you’ll find that MarkItDown did a great job converting the document to Markdown. It recognized the headings, font formatting, lists, and so on.
Below is another example where you convert the employees.xlsx, also provided in the downloadable materials:
>>> result = md.convert("./data/employees.xlsx")
>>> print(result)
## Sheet1
| First Name | Last Name | Department | Position | Start Date |
| --- | --- | --- | --- | --- |
| Alice | Johnson | Marketing | Marketing Coordinator | 2022-01-15 |
| Bob | Williams | Human Resources | HR Generalist | 2021-06-01 |
| Carol | Davis | Engineering | Software Engineer | 2023-03-20 |
| David | Brown | Sales | Sales Representative | 2022-09-10 |
| Eve | Miller | Finance | Financial Analyst | 2021-11-05 |
| Frank | Garcia | Customer Service | Customer Support Specialist | 2023-07-01 |
| Grace | Rodriguez | Research & Development | Research Scientist | 2022-04-25 |
| Henry | Martinez | Operations | Operations Manager | 2021-02-14 |
The Excel sheet is successfully converted into a Markdown table, which you can use in your documentation or AI-powered pipelines. Note that this time, you printed the result object itself rather than the .markdown attribute. This is possible because the string representation of DocumentConverterResult is the Markdown text.
You can also pass HTML content to .convert() using either an input file or a URL:
>>> result = md.convert("http://example.com")
>>> print(result)
# Example Domain
This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.
[More information...](https://www.iana.org/domains/example)
When you pass a URL to .convert(), MarkItDown navigates to the target resource, reads it, and converts it into Markdown.
When it comes to converting PDF files, the resulting Markdown isn’t as good as it is for Office documents. Consider the following example where you convert the markdown_syntax.pdf file:
>>> result = md.convert("./data/markdown_syntax.pdf")
>>> print(result.markdown)
Markdown Syntax Demo
This is a bold text, and this is italic text.
You can also combine them: bold + italic or strikethrough.
Headings
Heading 1
Heading 2
Heading 3
...
The result is more plain text than Markdown content. In any case, plain text is also a suitable format for feeding LLMs and AI pipelines. However, you might be somewhat disappointed if your intention is to use the resulting content for human consumption.
You already have a general idea of how to use MarkItDown’s Python API in your code. Next, you’ll create a quick script to batch-convert the documents in a given directory:
batch_converter.py
from pathlib import Path
from markitdown import MarkItDown
def main(
input_dir,
output_dir="output",
target_formats=(".docx", ".xlsx", ".pdf"),
):
input_path = Path(input_dir)
output_path = Path(output_dir)
output_path.mkdir(parents=True, exist_ok=True)
md = MarkItDown()
for file_path in input_path.rglob("*"):
if file_path.suffix in target_formats:
try:
result = md.convert(file_path)
except Exception as e:
print(f"✗ Error converting {file_path.name}: {e}")
continue
output_file = output_path / f"{file_path.stem}{file_path.suffix}.md"
output_file.write_text(result.markdown, encoding="utf-8")
print(f"✓ Converted {file_path.name} → {output_file.name}")
if __name__ == "__main__":
main("data", "output")
In this example, you create the main() function, which takes the input directory containing documents in different formats. The output directory is where you’d like to save the Markdown files. Next, you instantiate MarkItDown as usual.
The for loop walks through all files in the input directory recursively, using .rglob() to select the files whose extensions match the target formats. For each matching file, you call .convert() to run the conversion. Then, you write the .markdown content to an .md file in the output directory. These files will preserve the original filename.
Because MarkItDown handles multiple document types with a unified interface—the .convert() method—you don’t need to write format-specific code inside the loop.
Connect LLMs With MarkItDown’s MCP Server
MarkItDown offers a Model Context Protocol (MCP) server that you can set up to integrate with LLM or AI clients such as Claude Desktop. For this integration to work, you need to install markitdown-mcp, which you can do with the following command:
(venv) $ python -m pip install markitdown-mcp
This command will download and install markitdown-mcp in your current Python environment. To try out the server, you’ll use the Claude Desktop app. You can install the app by visiting the download page to get the official installer for your platform.
Once you launch the app, you’ll also need to sign in or register for a free Claude account if you don’t already have one.
Note: If you’re on Linux, then you won’t be able to use Claude Desktop. Instead, you can use other Linux-compatible AI clients. For example, you can check out the Python MCP Server: Connect LLMs to Your Data tutorial for instructions on how to set up the Cursor editor to query MCP servers.
In Claude Desktop, you need to connect to the MCP server. Go to Settings… → Developers and click the Edit Config button. Open the configuration file and add the following server configuration:
claude_desktop_config.json
{
"mcpServers": {
"markitdown": {
"command": "/full/path/to/python",
"args": ["-m", "markitdown_mcp"]
}
}
}
You need to specify the command property in the configuration above with the path of the Python interpreter where you installed markitdown-mcp. If you’ve installed the server within your system Python, then you can use the python command directly.
To ensure the correct configuration, you can run the following code in your Python REPL:
>>> import sys
>>> import json
>>> config = {
... "mcpServers": {
... "markitdown": {
... "command": sys.executable,
... "args": ["-m", "markitdown_mcp"]
... }
... }
... }
>>> print(json.dumps(config, indent=2))
{
"mcpServers": {
"markitdown": {
"command": "/full/path/to/python",
"args": [
"-m",
"markitdown_mcp"
]
}
}
}
Then, copy the resulting JSON into Claude Desktop’s configuration file and restart the app so it can load the MCP server. Start a new chat and run a prompt like this:
Summarize the content of the file
/path/to/file/pep8.docx.
Here’s what this chat might look like:
When you prompt the chat client, it’ll ask for permission to run the MCP server’s functionality. You’ll need to authorize that. Then, the chat will call the server’s tool to make the Markdown conversion, which you can see in the collapsible box as the server response. Finally, the chat summarizes the document content for you.
Explore Other AI Integrations
Besides text extraction, MarkItDown can directly integrate with LLMs to perform operations beyond the library’s capabilities. These operations may include image captioning, generating descriptions, and other related tasks. You can also do optical character recognition (OCR) to extract text from images.
In the following sections, you’ll code quick examples of how to use MarkItDown to generate image descriptions and extract text from image files.
Image Description
MarkItDown supports LLM-generated image descriptions and captions, making it well-suited for pipelines that feed LLMs with Markdown from diverse image types. To try out this feature, you’ll use the image below:

This image is also available in the downloads for this tutorial. Next, you need to install the openai library from PyPI with the following command:
(venv) $ python -m pip install openai
This library will allow you to connect MarkItDown to OpenAI’s LLMs using a Python interface. Once you’ve installed the library, run the following code in the REPL:
>>> from markitdown import MarkItDown
>>> from openai import OpenAI
>>> client = OpenAI()
>>> md = MarkItDown(llm_client=client, llm_model="gpt-4o")
>>> result = md.convert("./data/real-python.png")
>>> print(result.markdown)
Note that for this code to work, you must set up the OPENAI_API_KEY environment variable to contain a valid OpenAI API key.
The code above will generate an output similar to the following:
# Description:
In this vibrant and playful illustration, two characters are
enthusiastically engaged in a virtual learning session titled
"Real Python Online Python Training."
The character in the center, a large cartoonish figure wearing
a cap and sunglasses, is enjoying a bowl of popcorn while seated
on a green couch. Beside them, another character, with a cheerful
expression, is joining in the fun.
In front of them, a television screen displays the Real Python logo,
indicating they are watching or participating in an online course.
To the right, a figure with glasses is animatedly speaking into a camera,
highlighting that this is part of a creative and interactive learning
environment. The scene is set in a cozy room with a coffee table stacked
with books, emphasizing a blend of entertainment and education.
This is cool, isn’t it? Of course, your output may vary because the model won’t respond the same way for everyone. Note that the magic here comes from OpenAI’s image-recognition capabilities. MarkItDown creates a convenient wrapper around this functionality.
Optical Character Recognition (OCR)
Sometimes, you’ll have an image that contains text you want to extract as plain text. In such cases, you can use optical character recognition (OCR).
MarkItDown supports OCR through its Azure Document Intelligence integration. The DocumentIntelligenceConverter class enables OCR with high-resolution capabilities and additional features such as formula extraction and font style preservation.
For this feature to work, you need a Document Intelligence endpoint. Once you have it, you can do OCR with the following code snippet:
>>> from markitdown import MarkItDown
>>> md = MarkItDown(docintel_endpoint="<document_intelligence_endpoint>")
>>> result = md.convert("/path/to/image.png")
You can create a free Azure account to try this feature if needed. Finally, note that OCR features are applied to image files such as PDF, JPEG, PNG, BMP, and TIFF.
Custom Prompts
The MarkItDown constructor also accepts the llm_prompt argument, which you can use to provide a custom prompt for the target LLM.
Below is a screenshot of a terminal window showing a Python REPL session displaying the Zen of Python on screen:
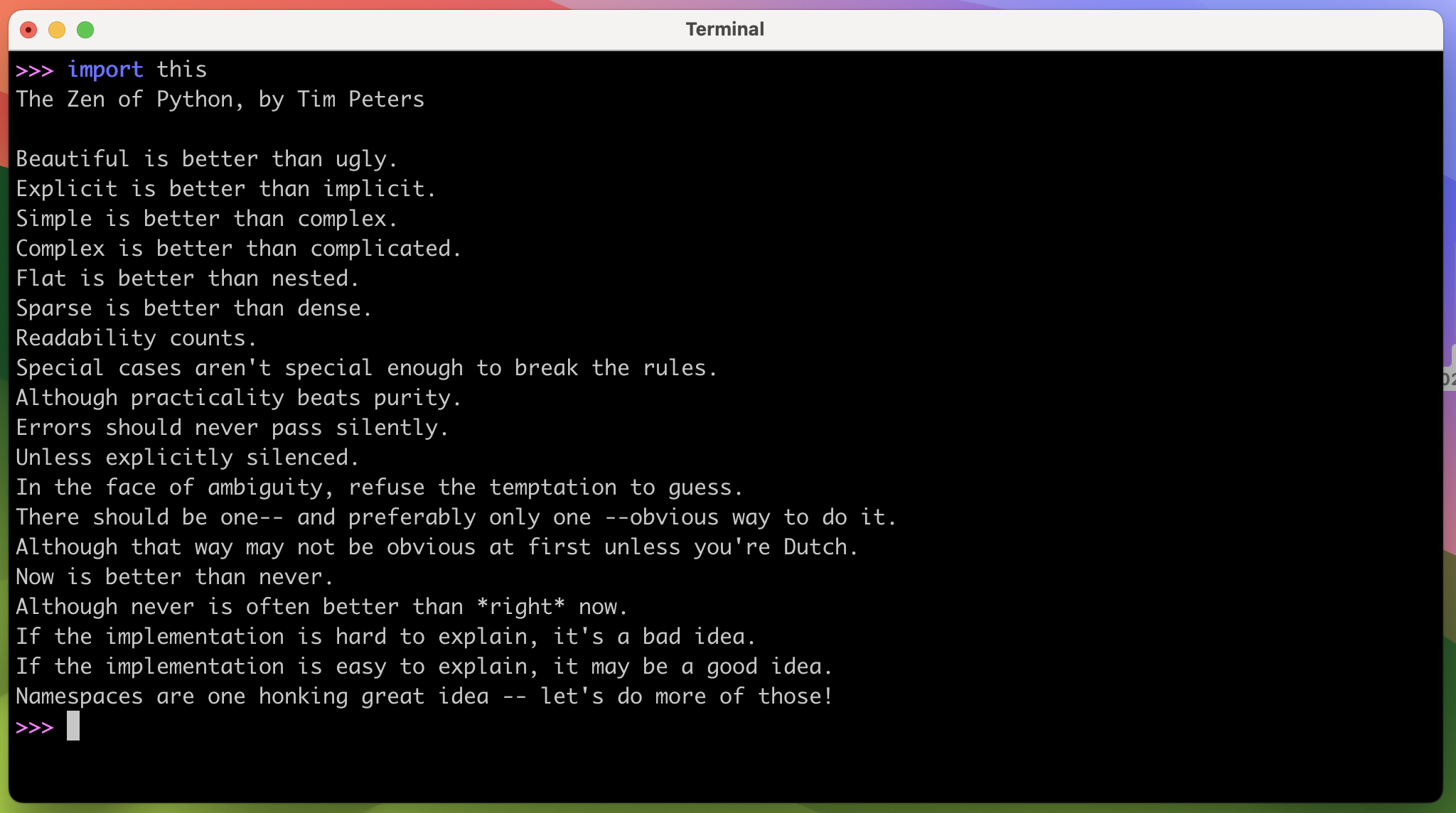
This image is included in the downloadable materials for this tutorial. Make sure you have it available when running the code below.
Go ahead and try the following prompt:
>>> from markitdown import MarkItDown
>>> from openai import OpenAI
>>> client = OpenAI()
>>> md = MarkItDown(
... llm_client=client,
... llm_model="gpt-4o",
... llm_prompt="Extract text from image with OCR and return Markdown.",
... )
>>> result = md.convert("./data/zen-of-python.png")
>>> print(result.markdown)
Once the code runs, you’ll get an output similar to the following:
# Description:
>>> import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
>>>
As you can see, the LLM did a great job extracting the text from the provided image. Now you have the image content as plain text. You can provide any relevant custom prompt based on the task you’re trying to perform.
Beware of MarkItDown’s Limitations
While MarkItDown’s output is often reasonably accurate and human-friendly, it’s intended to be used by text analysis tools, such as LLMs. It might not be the best option when you need high-fidelity, human-readable conversions.
Although MarkItDown is powerful, it currently has some limitations that include the following:
- Image handling: Complex images, graphics, and PDF files may not convert perfectly to Markdown.
- Fidelity issues: Some document formatting might be lost during conversion, especially with heavily styled documents.
- OCR accuracy: The accuracy of text extraction from images depends on both the image quality and the OCR engine’s performance.
If MarkItDown doesn’t meet your specific needs, consider alternatives such as:
- Pandoc: A versatile document converter that supports many input and output formats with extensive customization options.
- Python-Markdown: A library focused on converting Markdown to HTML and vice versa, which can be useful for specific Markdown processing tasks.
Be aware of these MarkItDown limitations so you can choose the right tool for your task. In general, if you mainly need to extract text from various document formats and send it to LLMs or other AI pipelines, then MarkItDown could be the best choice.
Conclusion
You’ve learned how to use the MarkItDown library to convert various document types, such as PDFs, Office files, images, and HTML, into Markdown text that’s ready for LLMs and AI-powered workflows. You also briefly explored how MarkItDown compares to alternatives like Pandoc.
You explored MarkItDown’s command-line interface (CLI) and Python API, used it in a batch-processing script, connected it to AI clients through its MCP server, and leveraged LLMs for advanced features such as image descriptions and OCR.
Rapid document-to-Markdown conversion can be essential for Python developers working with LLMs, AI, and text-processing pipelines.
In this tutorial, you’ve learned how to:
- Install MarkItDown with optional dependencies for multi-format support
- Convert documents using the CLI and Python API
- Batch-process files and automate conversion tasks in scripts
- Integrate MarkItDown with LLMs for tasks like image description and OCR
- Set up and connect MarkItDown’s MCP server to AI clients
With these skills, you’re now equipped to efficiently convert and process documents for LLM pipelines, automate bulk conversions, and integrate rich content extraction into your AI-driven applications. MarkItDown will help you bridge the gap between diverse file formats and AI-ready Markdown.
Get Your Code: Click here to download the free sample code that shows you how to use Python MarkItDown to convert documents into LLM-ready Markdown.
Frequently Asked Questions
Now that you have some experience with Python MarkItDown, you can use the questions and answers below to check your understanding and recap what you’ve learned.
These FAQs are related to the most important concepts you’ve covered in this tutorial. Click the Show/Hide toggle beside each question to reveal the answer.
Choose MarkItDown when you need fast, LLM-ready Markdown from multiple input formats and prioritize structure over fidelity. Use Pandoc when you need precise formatting control or a wider range of output formats.
You run python -m pip install 'markitdown[all]' to include all optional features. When you only need specific format handlers, you can install a subset like 'markitdown[pdf,pptx,docx]'.
You run markitdown <path> to print Markdown, and add -o <output_file.md> to write the output to your disk. You can also pipe input or use input redirection to feed data to markitdown.
To convert documents from Python code, you create a MarkItDown instance and call its .convert() method with a path or URL. Then, you access the .markdown attribute for the conversion result.
Yes, you can use Azure Document Intelligence to perform OCR on image formats such as PDF, JPEG, PNG, BMP, and TIFF. Alternatively, you can use a custom prompt and an OCR-capable LLM.
Take the Quiz: Test your knowledge with our interactive “Python MarkItDown: Convert Documents Into LLM-Ready Markdown” quiz. You’ll receive a score upon completion to help you track your learning progress:
Interactive Quiz
Python MarkItDown: Convert Documents Into LLM-Ready MarkdownPractice MarkItDown basics. Convert PDFs, Word documents, Excel documents, and HTML documents to Markdown. Try the quiz.








